 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Multi-Head Attention for Speaker Recognition
Paper and Code
Jul 01, 2019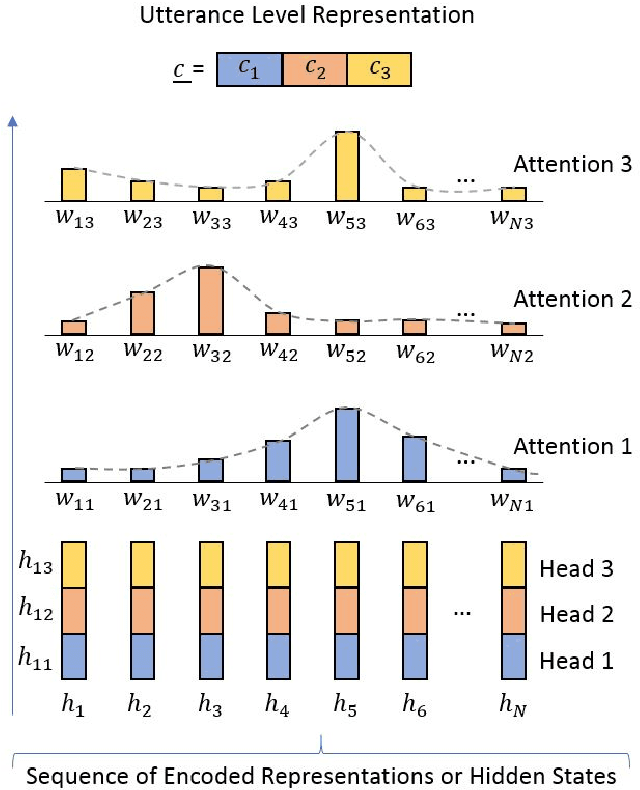
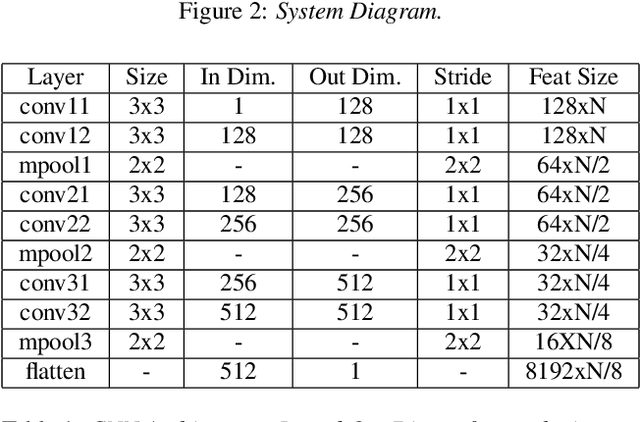
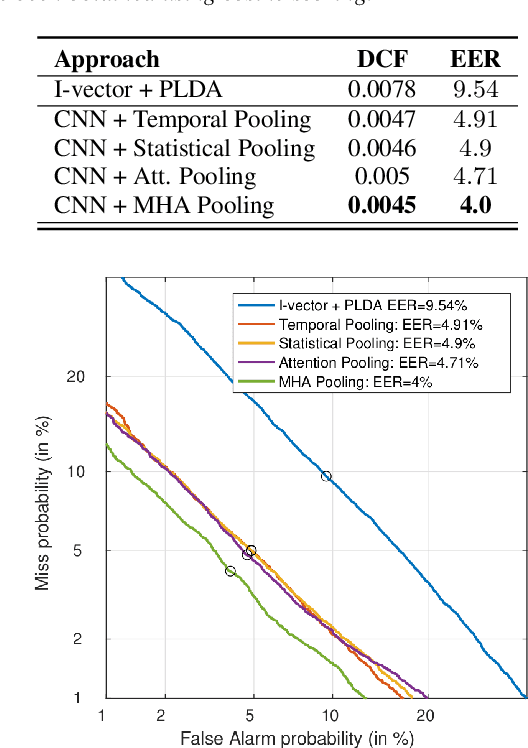
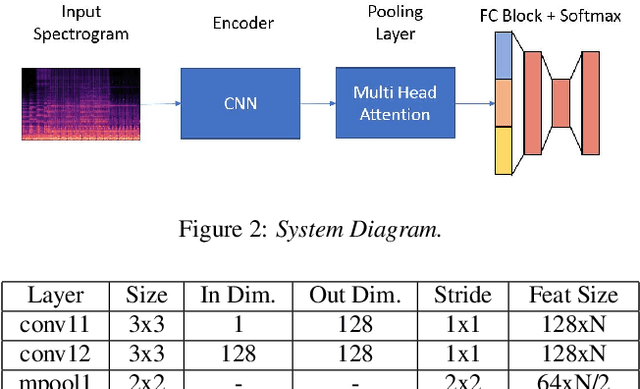
Most state-of-the-art Deep Learning (DL) approaches for speaker recognition work on a short utterance level. Given the speech signal, these algorithms extract a sequence of speaker embeddings from short segments and those are averaged to obtain an utterance level speaker representation. In this work we propose the use of an attention mechanism to obtain a discriminative speaker embedding given non fixed length speech utterances. Our system is based on a Convolutional Neural Network (CNN) that encodes short-term speaker features from the spectrogram and a self multi-head attention model that maps these representations into a long-term speaker embedding. The attention model that we propose produces multiple alignments from different subsegments of the CNN encoded states over the sequence. Hence this mechanism works as a pooling layer which decides the most discriminative features over the sequence to obtain an utterance level representation. We have tested this approach for the verification task for the VoxCeleb1 dataset. The results show that self multi-head attention outperforms both temporal and statistical pooling methods with a 18\% of relative EER. Obtained results show a 58\% relative improvement in EER compared to i-vector+PLDA.