 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Modelling for Speaker Diarization in Telephonic Interviews
Jan 28, 2025



The aim of this paper is to investigate the benefit of combining both language and acoustic modelling for speaker diarization. Although conventional systems only use acoustic features, in some scenarios linguistic data contain high discriminative speaker information, even more reliable than the acoustic ones. In this study we analyze how an appropriate fusion of both kind of features is able to obtain good results in these cases. The proposed system is based on an iterative algorithm where a LSTM network is used as a speaker classifier. The network is fed with character-level word embeddings and a GMM based acoustic score created with the output labels from previous iterations. The presented algorithm has been evaluated in a Call-Center database, which is composed of telephone interview audios. The combination of acoustic features and linguistic content shows a 84.29% improvement in terms of a word-level DER as compared to a HMM/VB baseline system. The results of this study confirms that linguistic content can be efficiently used for some speaker recognition tasks.
BSC-UPC at EmoSPeech-IberLEF2024: Attention Pooling for Emotion Recognition
Jul 17, 2024The domain of speech emotion recognition (SER) has persistently been a frontier within the landscape of machine learning. It is an active field that has been revolutionized in the last few decades and whose implementations are remarkable in multiple applications that could affect daily life. Consequently, the Iberian Languages Evaluation Forum (IberLEF) of 2024 held a competitive challenge to leverage the SER results with a Spanish corpus. This paper presents the approach followed with the goal of participating in this competition. The main architecture consists of different pre-trained speech and text models to extract features from both modalities, utilizing an attention pooling mechanism. The proposed system has achieved the first position in the challenge with an 86.69% in Macro F1-Score.
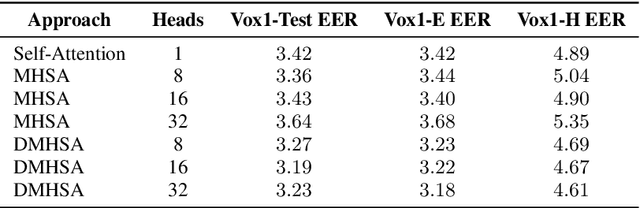
Double Multi-Head Attention Multimodal System for Odyssey 2024 Speech Emotion Recognition Challenge
Jun 15, 2024



As computer-based applications are becoming more integrated into our daily lives, the importance of Speech Emotion Recognition (SER) has increased significantly. Promoting research with innovative approaches in SER, the Odyssey 2024 Speech Emotion Recognition Challenge was organized as part of the Odyssey 2024 Speaker and Language Recognition Workshop. In this paper we describe the Double Multi-Head Attention Multimodal System developed for this challenge. Pre-trained self-supervised models were used to extract informative acoustic and text features. An early fusion strategy was adopted, where a Multi-Head Attention layer transforms these mixed features into complementary contextualized representations. A second attention mechanism is then applied to pool these representations into an utterance-level vector. Our proposed system achieved the third position in the categorical task ranking with a 34.41% Macro-F1 score, where 31 teams participated in total.
Speaker Characterization by means of Attention Pooling
May 07, 2024


State-of-the-art Deep Learning systems for speaker verification are commonly based on speaker embedding extractors. These architectures are usually composed of a feature extractor front-end together with a pooling layer to encode variable-length utterances into fixed-length speaker vectors. The authors have recently proposed the use of a Double Multi-Head Self-Attention pooling for speaker recognition, placed between a CNN-based front-end and a set of fully connected layers. This has shown to be an excellent approach to efficiently select the most relevant features captured by the front-end from the speech signal. In this paper we show excellent experimental results by adapting this architecture to other different speaker characterization tasks, such as emotion recognition, sex classification and COVID-19 detection.
* IberSpeech 2022
Self-attention encoding and pooling for speaker recognition
Aug 03, 2020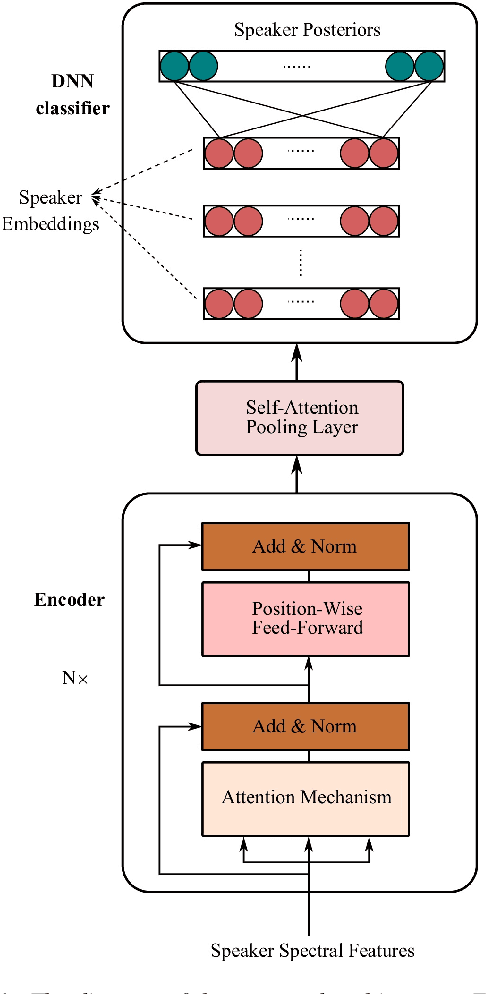
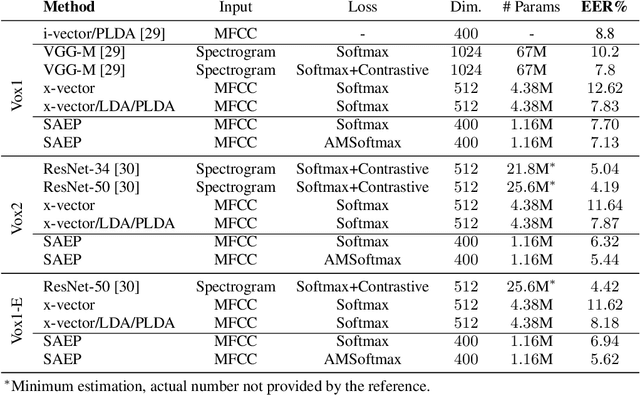
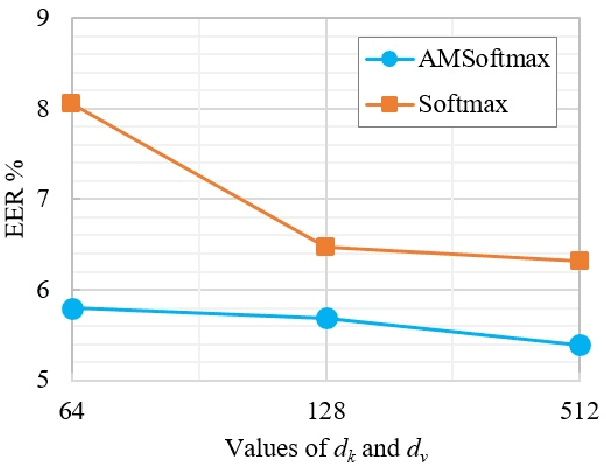
The computing power of mobile devices limits the end-user applications in terms of storage size, processing, memory and energy consumption. These limitations motivate researchers for the design of more efficient deep models. On the other hand, self-attention networks based on Transformer architecture have attracted remarkable interests due to their high parallelization capabilities and strong performance on a variety of Natural Language Processing (NLP) applications. Inspired by the Transformer, we propose a tandem Self-Attention Encoding and Pooling (SAEP) mechanism to obtain a discriminative speaker embedding given non-fixed length speech utterances. SAEP is a stack of identical blocks solely relied on self-attention and position-wise feed-forward networks to create vector representation of speakers. This approach encodes short-term speaker spectral features into speaker embeddings to be used in text-independent speaker verification. We have evaluated this approach on both VoxCeleb1 & 2 datasets. The proposed architecture is able to outperform the baseline x-vector, and shows competitive performance to some other benchmarks based on convolutions, with a significant reduction in model size. It employs 94%, 95%, and 73% less parameters compared to ResNet-34, ResNet-50, and x-vector, respectively. This indicates that the proposed fully attention based architecture is more efficient in extracting time-invariant features from speaker utterances.
Self Multi-Head Attention for Speaker Recognition
Jul 01, 2019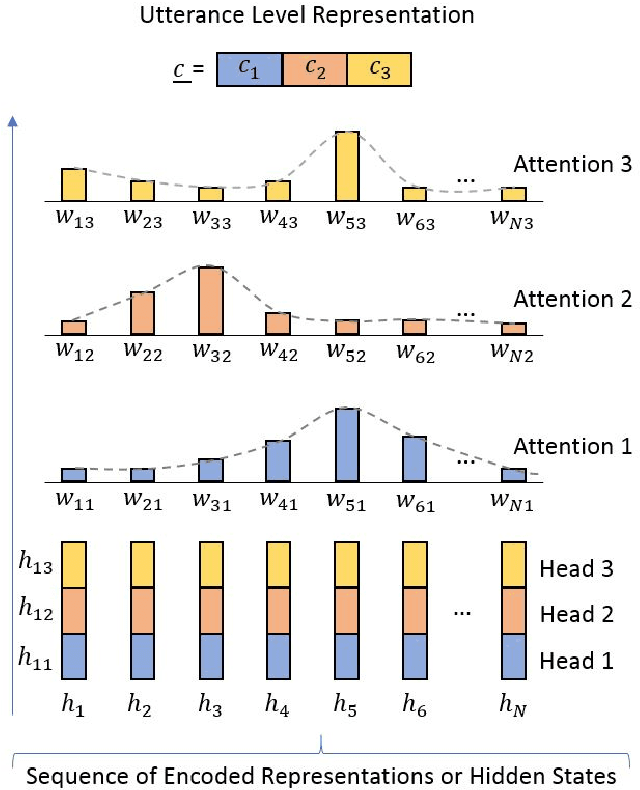
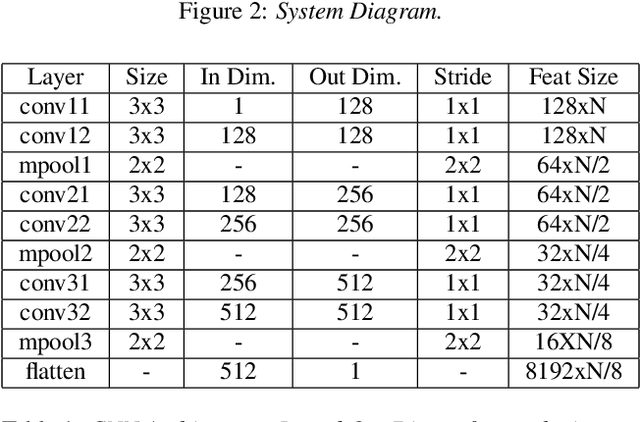
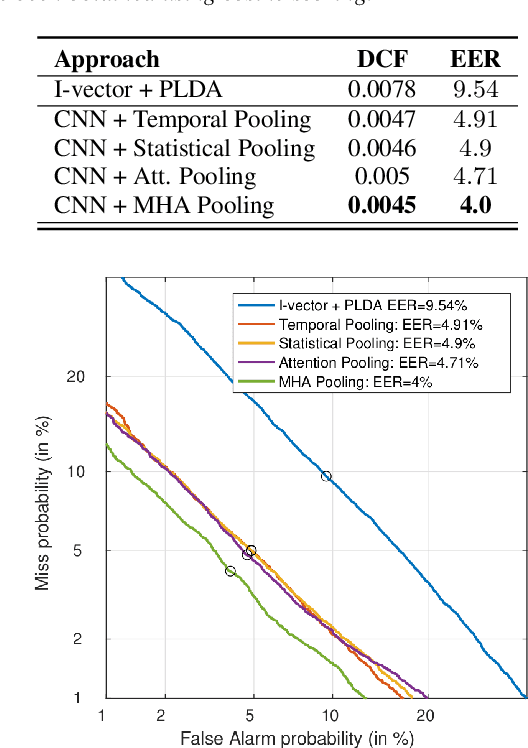
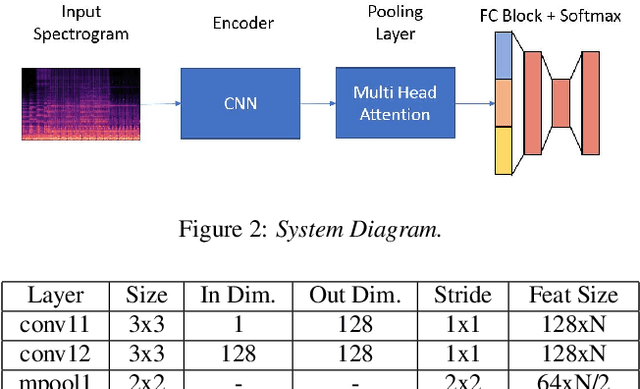
Most state-of-the-art Deep Learning (DL) approaches for speaker recognition work on a short utterance level. Given the speech signal, these algorithms extract a sequence of speaker embeddings from short segments and those are averaged to obtain an utterance level speaker representation. In this work we propose the use of an attention mechanism to obtain a discriminative speaker embedding given non fixed length speech utterances. Our system is based on a Convolutional Neural Network (CNN) that encodes short-term speaker features from the spectrogram and a self multi-head attention model that maps these representations into a long-term speaker embedding. The attention model that we propose produces multiple alignments from different subsegments of the CNN encoded states over the sequence. Hence this mechanism works as a pooling layer which decides the most discriminative features over the sequence to obtain an utterance level representation. We have tested this approach for the verification task for the VoxCeleb1 dataset. The results show that self multi-head attention outperforms both temporal and statistical pooling methods with a 18\% of relative EER. Obtained results show a 58\% relative improvement in EER compared to i-vector+PLDA.