 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Characterization by means of Attention Pooling
Paper and Code
May 07, 2024
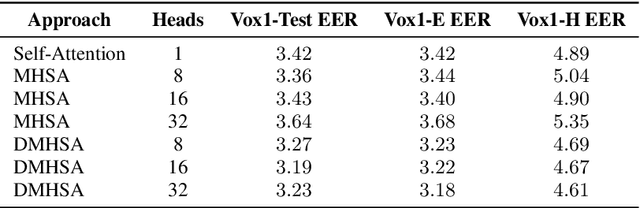


State-of-the-art Deep Learning systems for speaker verification are commonly based on speaker embedding extractors. These architectures are usually composed of a feature extractor front-end together with a pooling layer to encode variable-length utterances into fixed-length speaker vectors. The authors have recently proposed the use of a Double Multi-Head Self-Attention pooling for speaker recognition, placed between a CNN-based front-end and a set of fully connected layers. This has shown to be an excellent approach to efficiently select the most relevant features captured by the front-end from the speech signal. In this paper we show excellent experimental results by adapting this architecture to other different speaker characterization tasks, such as emotion recognition, sex classification and COVID-19 detection.