 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-to-Text Translation with Phoneme-Augmented CoT: Enhancing Cross-Lingual Transfer in Low-Resource Scenarios
May 30, 2025We propose a Speech-to-Text Translation (S2TT) approach that integrates phoneme representations into a Chain-of-Thought (CoT) framework to improve translation in low-resource and zero-resource settings. By introducing phoneme recognition as an intermediate step, we enhance cross-lingual transfer, enabling translation even for languages with no labeled speech data. Our system builds on a multilingual LLM, which we extend to process speech and phonemes. Training follows a curriculum learning strategy that progressively introduces more complex tasks. Experiments on multilingual S2TT benchmarks show that phoneme-augmented CoT improves translation quality in low-resource conditions and enables zero-resource translation, while slightly impacting high-resource performance. Despite this trade-off, our findings demonstrate that phoneme-based CoT is a promising step toward making S2TT more accessible across diverse languages.
Breaking Language Barriers in Visual Language Models via Multilingual Textual Regularization
Mar 28, 2025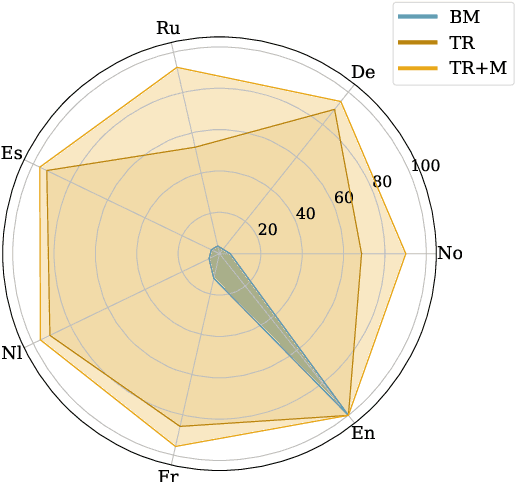
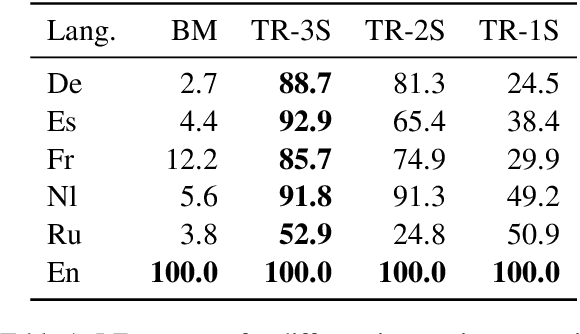
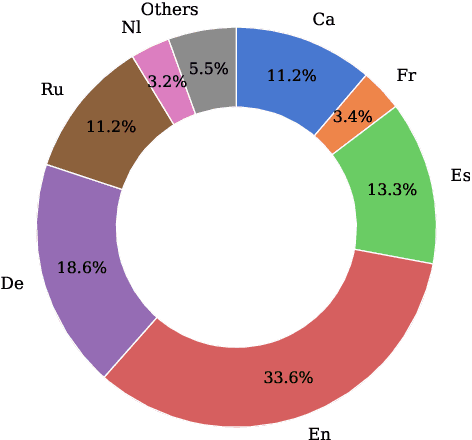
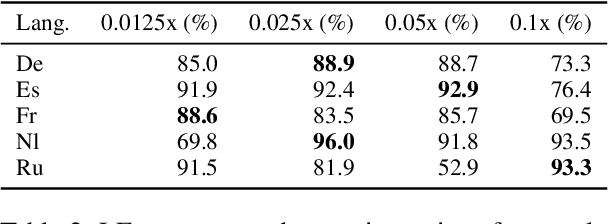
Rapid advancements in Visual Language Models (VLMs) have transformed multimodal understanding but are often constrained by generating English responses regardless of the input language. This phenomenon has been termed as Image-induced Fidelity Loss (IFL) and stems from limited multimodal multilingual training data. To address this, we propose a continuous multilingual integration strategy that injects text-only multilingual data during visual instruction tuning, preserving the language model's original multilingual capabilities. Extensive evaluations demonstrate that our approach significantly improves linguistic fidelity across languages without degradation in visual performance. We also explore model merging, which improves language fidelity but comes at the cost of visual performance. In contrast, our core method achieves robust multilingual alignment without trade-offs, offering a scalable and effective path to mitigating IFL for global VLM adoption.