 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJobResQA: A Benchmark for LLM Machine Reading Comprehension on Multilingual Résumés and JDs
Jan 30, 2026We introduce JobResQA, a multilingual Question Answering benchmark for evaluating Machine Reading Comprehension (MRC) capabilities of LLMs on HR-specific tasks involving résumés and job descriptions. The dataset comprises 581 QA pairs across 105 synthetic résumé-job description pairs in five languages (English, Spanish, Italian, German, and Chinese), with questions spanning three complexity levels from basic factual extraction to complex cross-document reasoning. We propose a data generation pipeline derived from real-world sources through de-identification and data synthesis to ensure both realism and privacy, while controlled demographic and professional attributes (implemented via placeholders) enable systematic bias and fairness studies. We also present a cost-effective, human-in-the-loop translation pipeline based on the TEaR methodology, incorporating MQM error annotations and selective post-editing to ensure an high-quality multi-way parallel benchmark. We provide a baseline evaluations across multiple open-weight LLM families using an LLM-as-judge approach revealing higher performances on English and Spanish but substantial degradation for other languages, highlighting critical gaps in multilingual MRC capabilities for HR applications. JobResQA provides a reproducible benchmark for advancing fair and reliable LLM-based HR systems. The benchmark is publicly available at: https://github.com/Avature/jobresqa-benchmark
Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025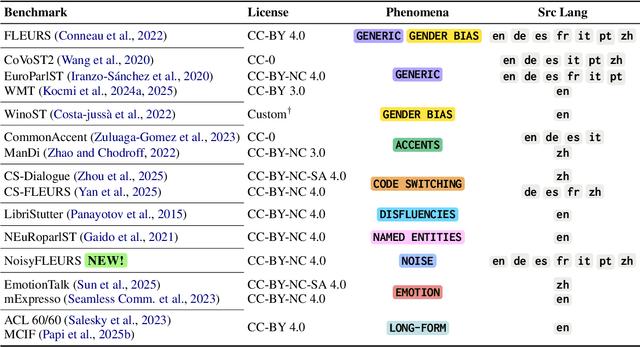
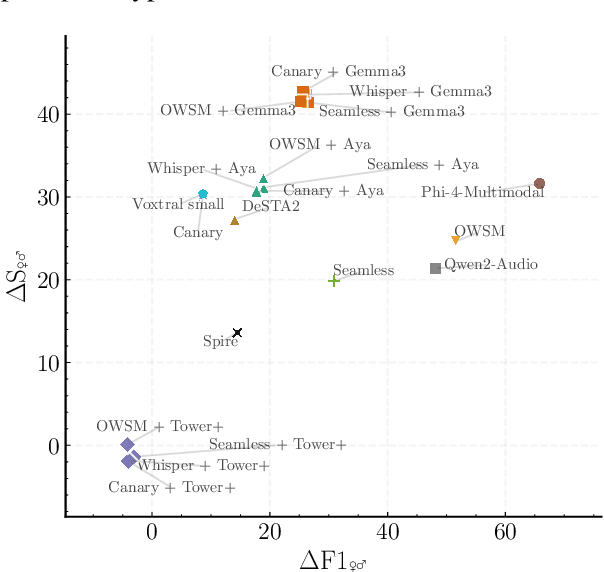
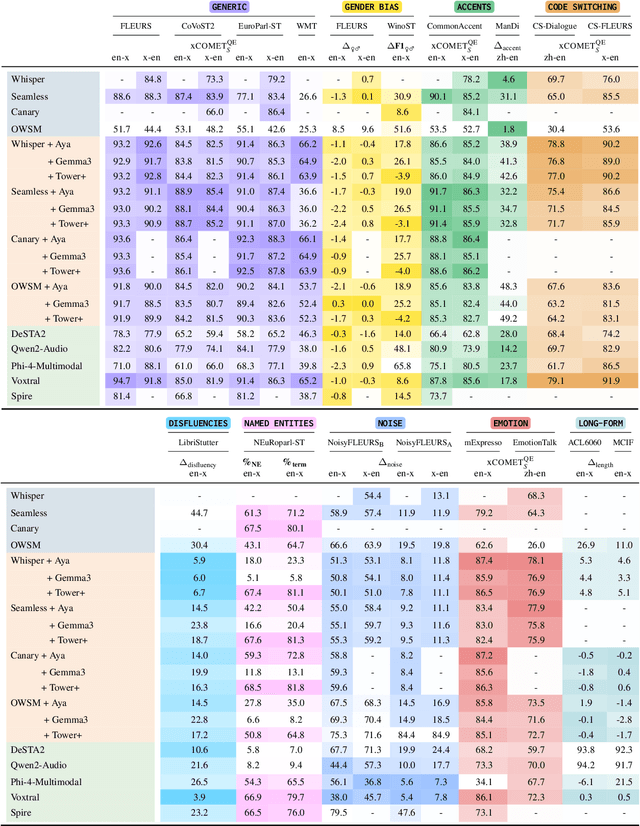
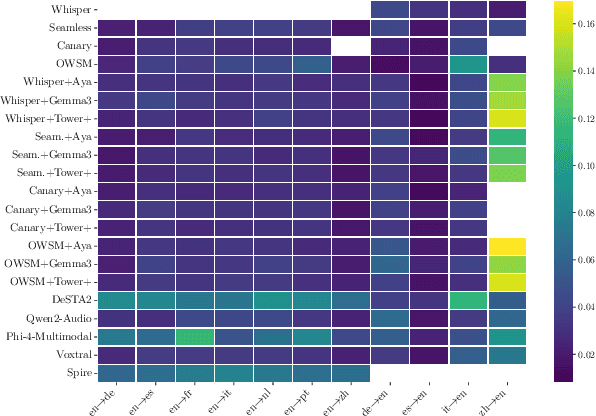
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.
Breaking Language Barriers in Visual Language Models via Multilingual Textual Regularization
Mar 28, 2025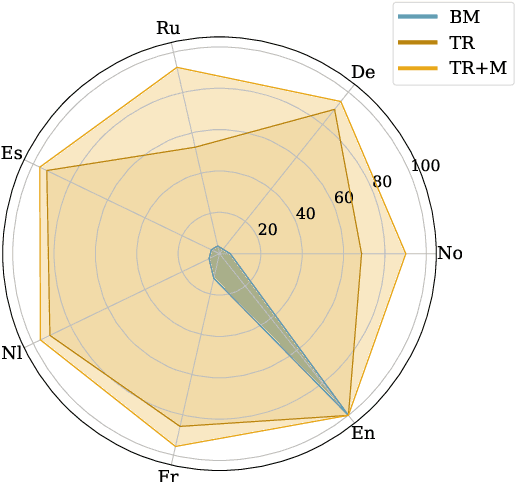
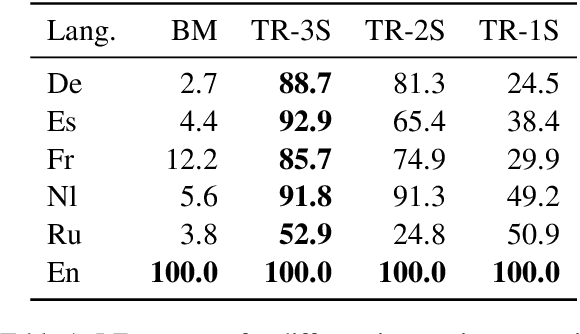
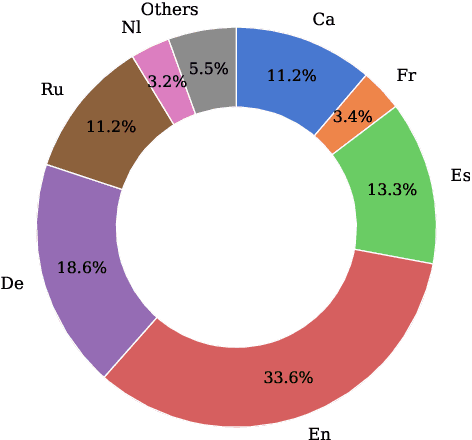
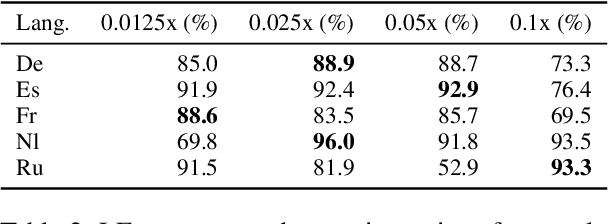
Rapid advancements in Visual Language Models (VLMs) have transformed multimodal understanding but are often constrained by generating English responses regardless of the input language. This phenomenon has been termed as Image-induced Fidelity Loss (IFL) and stems from limited multimodal multilingual training data. To address this, we propose a continuous multilingual integration strategy that injects text-only multilingual data during visual instruction tuning, preserving the language model's original multilingual capabilities. Extensive evaluations demonstrate that our approach significantly improves linguistic fidelity across languages without degradation in visual performance. We also explore model merging, which improves language fidelity but comes at the cost of visual performance. In contrast, our core method achieves robust multilingual alignment without trade-offs, offering a scalable and effective path to mitigating IFL for global VLM adoption.
MT-LENS: An all-in-one Toolkit for Better Machine Translation Evaluation
Dec 16, 2024
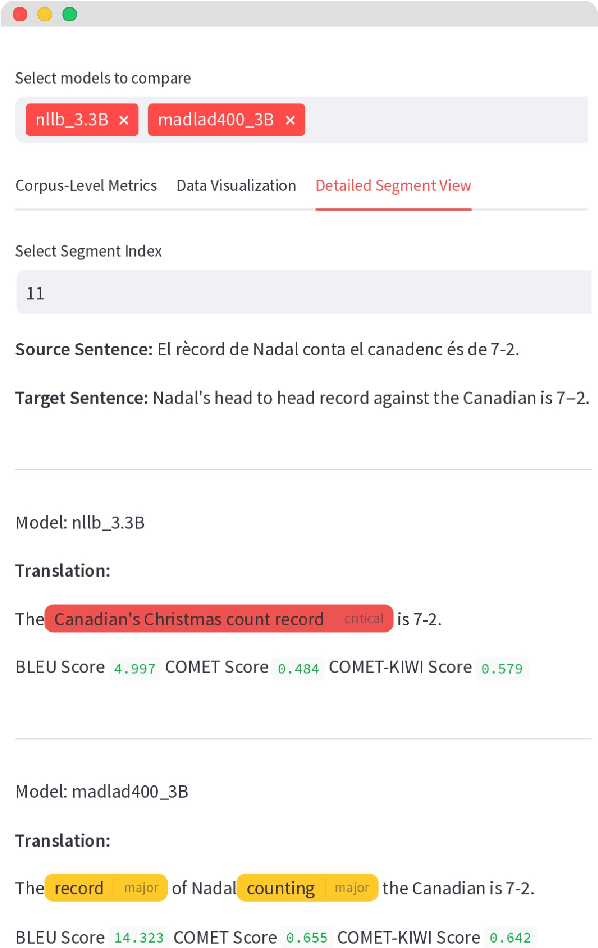
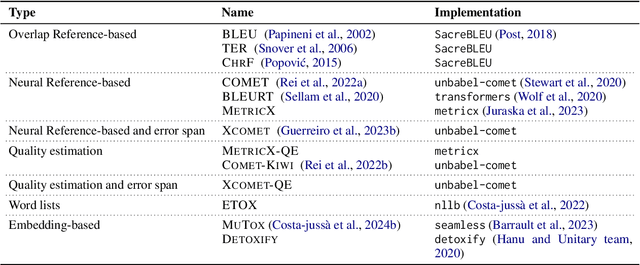
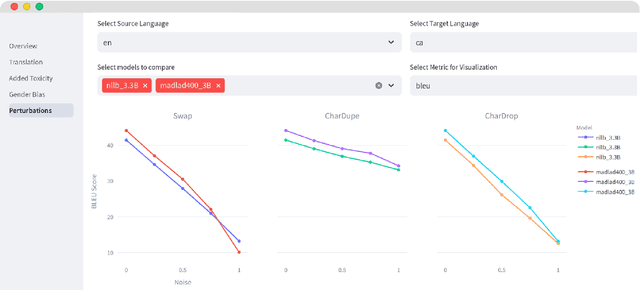
We introduce MT-LENS, a framework designed to evaluate Machine Translation (MT) systems across a variety of tasks, including translation quality, gender bias detection, added toxicity, and robustness to misspellings. While several toolkits have become very popular for benchmarking the capabilities of Large Language Models (LLMs), existing evaluation tools often lack the ability to thoroughly assess the diverse aspects of MT performance. MT-LENS addresses these limitations by extending the capabilities of LM-eval-harness for MT, supporting state-of-the-art datasets and a wide range of evaluation metrics. It also offers a user-friendly platform to compare systems and analyze translations with interactive visualizations. MT-LENS aims to broaden access to evaluation strategies that go beyond traditional translation quality evaluation, enabling researchers and engineers to better understand the performance of a NMT model and also easily measure system's biases.
The power of Prompts: Evaluating and Mitigating Gender Bias in MT with LLMs
Jul 26, 2024This paper studies gender bias in machine translation through the lens of Large Language Models (LLMs). Four widely-used test sets are employed to benchmark various base LLMs, comparing their translation quality and gender bias against state-of-the-art Neural Machine Translation (NMT) models for English to Catalan (En $\rightarrow$ Ca) and English to Spanish (En $\rightarrow$ Es) translation directions. Our findings reveal pervasive gender bias across all models, with base LLMs exhibiting a higher degree of bias compared to NMT models. To combat this bias, we explore prompting engineering techniques applied to an instruction-tuned LLM. We identify a prompt structure that significantly reduces gender bias by up to 12% on the WinoMT evaluation dataset compared to more straightforward prompts. These results significantly reduce the gender bias accuracy gap between LLMs and traditional NMT systems.
Investigating the translation capabilities of Large Language Models trained on parallel data only
Jun 13, 2024



In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
Promoting Generalized Cross-lingual Question Answering in Few-resource Scenarios via Self-knowledge Distillation
Sep 29, 2023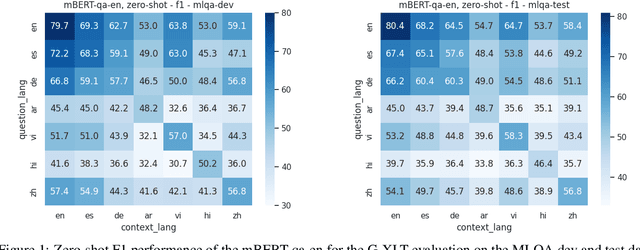
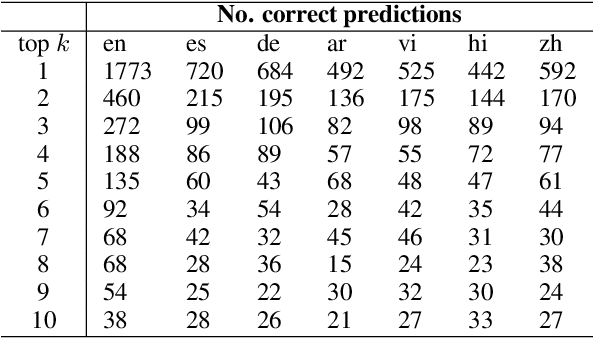

Despite substantial progress in multilingual extractive Question Answering (QA), models with high and uniformly distributed performance across languages remain challenging, especially for languages with limited resources. We study cross-lingual transfer mainly focusing on the Generalized Cross-Lingual Transfer (G-XLT) task, where the question language differs from the context language - a challenge that has received limited attention thus far. Our approach seeks to enhance cross-lingual QA transfer using a high-performing multilingual model trained on a large-scale dataset, complemented by a few thousand aligned QA examples across languages. Our proposed strategy combines cross-lingual sampling and advanced self-distillation training in generations to tackle the previous challenge. Notably, we introduce the novel mAP@k coefficients to fine-tune self-knowledge distillation loss, dynamically regulating the teacher's model knowledge to perform a balanced and effective knowledge transfer. We extensively evaluate our approach to assess XLT and G-XLT capabilities in extractive QA. Results reveal that our self-knowledge distillation approach outperforms standard cross-entropy fine-tuning by a significant margin. Importantly, when compared to a strong baseline that leverages a sizeable volume of machine-translated data, our approach shows competitive results despite the considerable challenge of operating within resource-constrained settings, even in zero-shot scenarios. Beyond performance improvements, we offer valuable insights through comprehensive analyses and an ablation study, further substantiating the benefits and constraints of our approach. In essence, we propose a practical solution to improve cross-lingual QA transfer by leveraging a few data resources in an efficient way.
ReSeTOX: Re-learning attention weights for toxicity mitigation in machine translation
May 19, 2023



Our proposed method, ReSeTOX (REdo SEarch if TOXic), addresses the issue of Neural Machine Translation (NMT) generating translation outputs that contain toxic words not present in the input. The objective is to mitigate the introduction of toxic language without the need for re-training. In the case of identified added toxicity during the inference process, ReSeTOX dynamically adjusts the key-value self-attention weights and re-evaluates the beam search hypotheses. Experimental results demonstrate that ReSeTOX achieves a remarkable 57% reduction in added toxicity while maintaining an average translation quality of 99.5% across 164 languages.
Toxicity in Multilingual Machine Translation at Scale
Oct 06, 2022
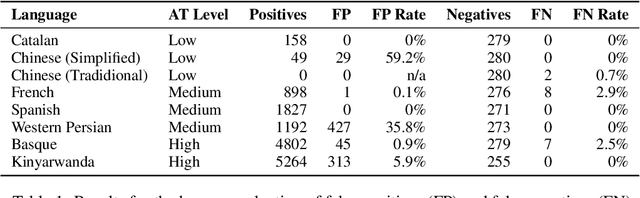
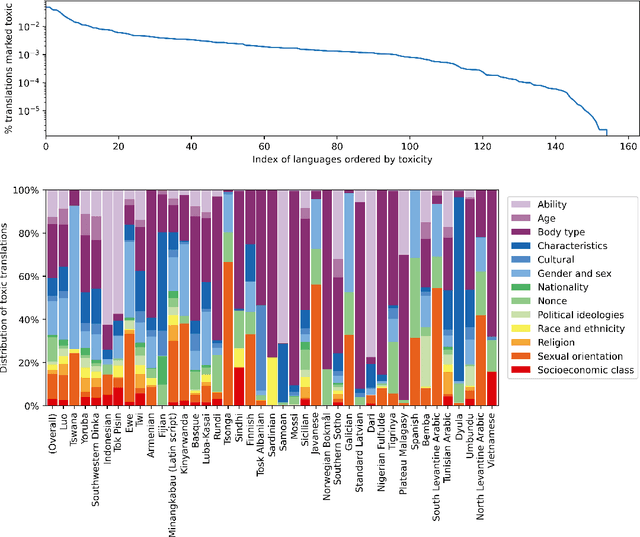
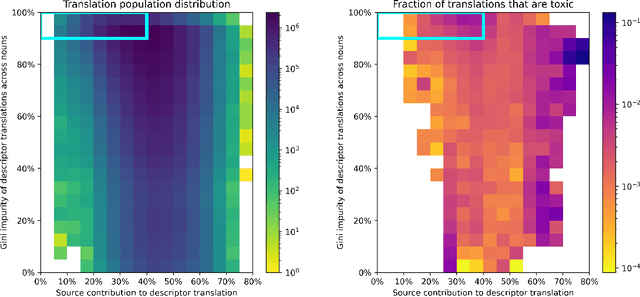
Machine Translation systems can produce different types of errors, some of which get characterized as critical or catastrophic due to the specific negative impact they can have on users. Automatic or human evaluation metrics do not necessarily differentiate between such critical errors and more innocuous ones. In this paper we focus on one type of critical error: added toxicity. We evaluate and analyze added toxicity when translating a large evaluation dataset (HOLISTICBIAS, over 472k sentences, covering 13 demographic axes) from English into 164 languages. The toxicity automatic evaluation shows that added toxicity across languages varies from 0% to 5%. The output languages with the most added toxicity tend to be low-resource ones, and the demographic axes with the most added toxicity include sexual orientation, gender and sex, and ability. We also perform human evaluation on a subset of 8 directions, confirming the prevalence of true added toxicity. We use a measurement of the amount of source contribution to the translation, where a low source contribution implies hallucination, to interpret what causes toxicity. We observe that the source contribution is somewhat correlated with toxicity but that 45.6% of added toxic words have a high source contribution, suggesting that much of the added toxicity may be due to mistranslations. Combining the signal of source contribution level with a measurement of translation robustness allows us to flag 22.3% of added toxicity, suggesting that added toxicity may be related to both hallucination and the stability of translations in different contexts. Given these findings, our recommendations to reduce added toxicity are to curate training data to avoid mistranslations, mitigate hallucination and check unstable translations.
Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
May 23, 2022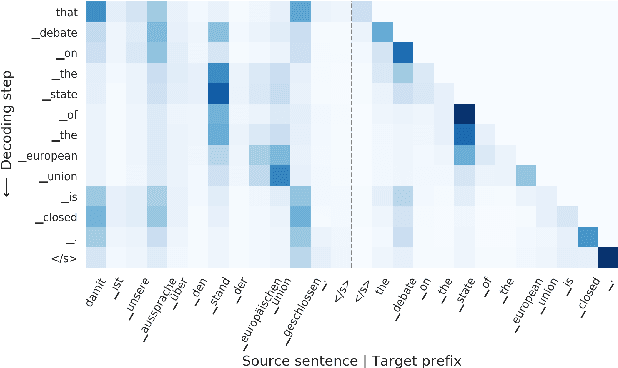
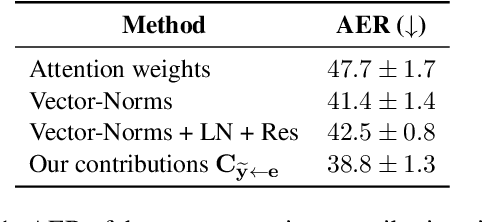
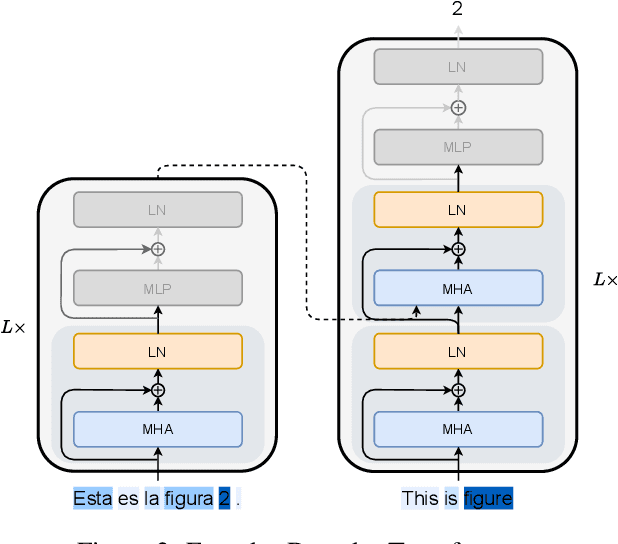
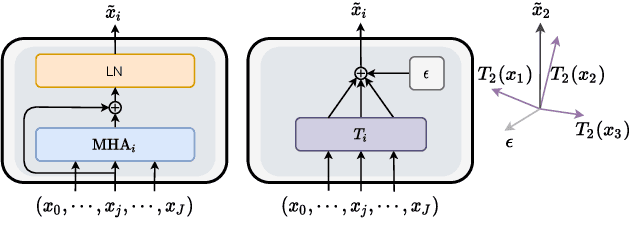
In Neural Machine Translation (NMT), each token prediction is conditioned on the source sentence and the target prefix (what has been previously translated at a decoding step). However, previous work on interpretability in NMT has focused solely on source sentence tokens attributions. Therefore, we lack a full understanding of the influences of every input token (source sentence and target prefix) in the model predictions. In this work, we propose an interpretability method that tracks complete input token attributions. Our method, which can be extended to any encoder-decoder Transformer-based model, allows us to better comprehend the inner workings of current NMT models. We apply the proposed method to both bilingual and multilingual Transformers and present insights into their behaviour.