 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-task semi-supervised framework for Text2Graph & Graph2Text
Paper and Code
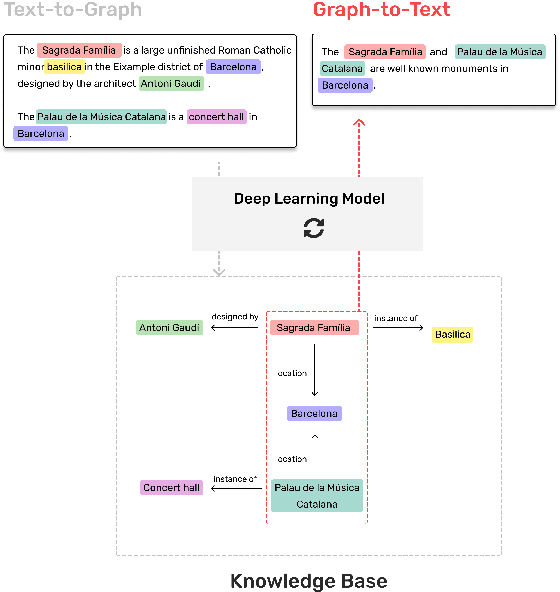



The Artificial Intelligence industry regularly develops applications that mostly rely on Knowledge Bases, a data repository about specific, or general, domains, usually represented in a graph shape. Similar to other databases, they face two main challenges: information ingestion and information retrieval. We approach these challenges by jointly learning graph extraction from text and text generation from graphs. The proposed solution, a T5 architecture, is trained in a multi-task semi-supervised environment, with our collected non-parallel data, following a cycle training regime. Experiments on WebNLG dataset show that our approach surpasses unsupervised state-of-the-art results in text-to-graph and graph-to-text. More relevantly, our framework is more consistent across seen and unseen domains than supervised models. The resulting model can be easily trained in any new domain with non-parallel data, by simply adding text and graphs about it, in our cycle framework.