 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Nov 18, 2024This paper presents Llama Guard 3-1B-INT4, a compact and efficient Llama Guard model, which has been open-sourced to the community during Meta Connect 2024. We demonstrate that Llama Guard 3-1B-INT4 can be deployed on resource-constrained devices, achieving a throughput of at least 30 tokens per second and a time-to-first-token of 2.5 seconds or less on a commodity Android mobile CPU. Notably, our experiments show that Llama Guard 3-1B-INT4 attains comparable or superior safety moderation scores to its larger counterpart, Llama Guard 3-1B, despite being approximately 7 times smaller in size (440MB).
Llama Guard 3 Vision: Safeguarding Human-AI Image Understanding Conversations
Nov 15, 2024
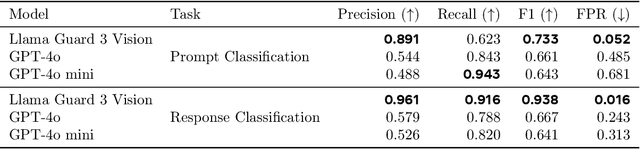
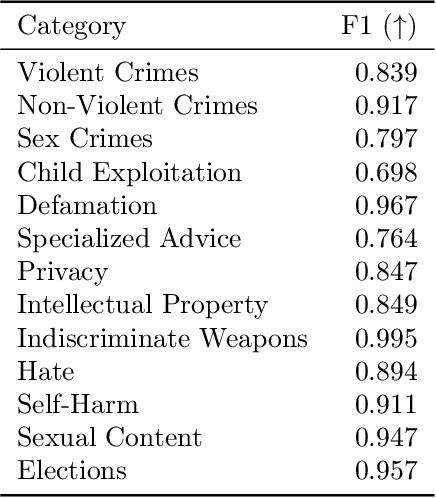
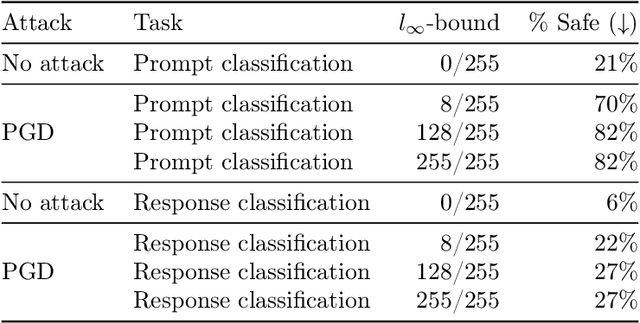
We introduce Llama Guard 3 Vision, a multimodal LLM-based safeguard for human-AI conversations that involves image understanding: it can be used to safeguard content for both multimodal LLM inputs (prompt classification) and outputs (response classification). Unlike the previous text-only Llama Guard versions (Inan et al., 2023; Llama Team, 2024b,a), it is specifically designed to support image reasoning use cases and is optimized to detect harmful multimodal (text and image) prompts and text responses to these prompts. Llama Guard 3 Vision is fine-tuned on Llama 3.2-Vision and demonstrates strong performance on the internal benchmarks using the MLCommons taxonomy. We also test its robustness against adversarial attacks. We believe that Llama Guard 3 Vision serves as a good starting point to build more capable and robust content moderation tools for human-AI conversation with multimodal capabilities.
Multilingual Holistic Bias: Extending Descriptors and Patterns to Unveil Demographic Biases in Languages at Scale
May 22, 2023



We introduce a multilingual extension of the HOLISTICBIAS dataset, the largest English template-based taxonomy of textual people references: MULTILINGUALHOLISTICBIAS. This extension consists of 20,459 sentences in 50 languages distributed across all 13 demographic axes. Source sentences are built from combinations of 118 demographic descriptors and three patterns, excluding nonsensical combinations. Multilingual translations include alternatives for gendered languages that cover gendered translations when there is ambiguity in English. Our benchmark is intended to uncover demographic imbalances and be the tool to quantify mitigations towards them. Our initial findings show that translation quality for EN-to-XX translations is an average of 8 spBLEU better when evaluating with the masculine human reference compared to feminine. In the opposite direction, XX-to-EN, we compare the robustness of the model when the source input only differs in gender (masculine or feminine) and masculine translations are an average of almost 4 spBLEU better than feminine. When embedding sentences to a joint multilingual sentence representations space, we find that for most languages masculine translations are significantly closer to the English neutral sentences when embedded.
Toxicity in Multilingual Machine Translation at Scale
Oct 06, 2022
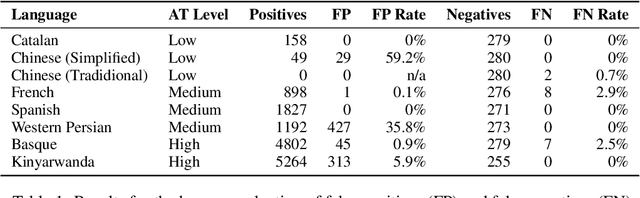
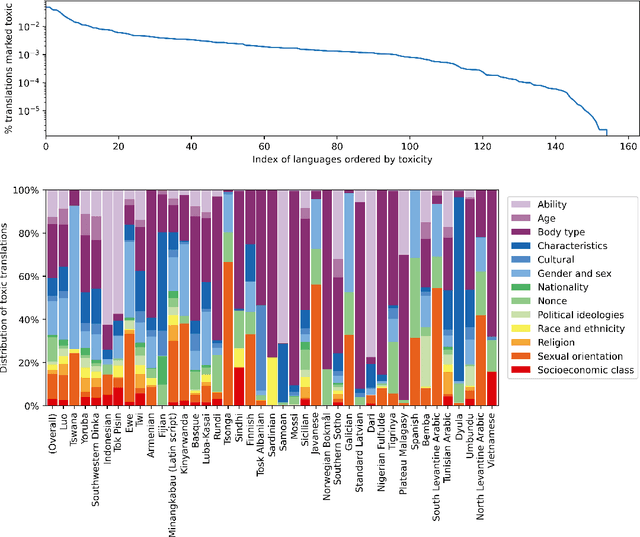
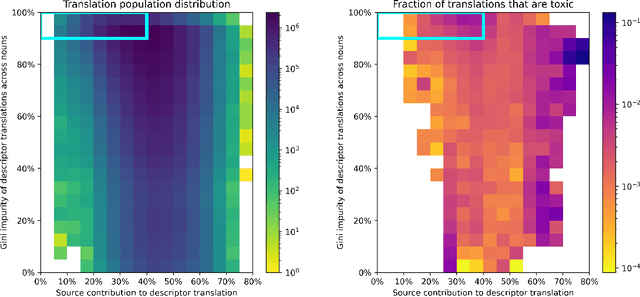
Machine Translation systems can produce different types of errors, some of which get characterized as critical or catastrophic due to the specific negative impact they can have on users. Automatic or human evaluation metrics do not necessarily differentiate between such critical errors and more innocuous ones. In this paper we focus on one type of critical error: added toxicity. We evaluate and analyze added toxicity when translating a large evaluation dataset (HOLISTICBIAS, over 472k sentences, covering 13 demographic axes) from English into 164 languages. The toxicity automatic evaluation shows that added toxicity across languages varies from 0% to 5%. The output languages with the most added toxicity tend to be low-resource ones, and the demographic axes with the most added toxicity include sexual orientation, gender and sex, and ability. We also perform human evaluation on a subset of 8 directions, confirming the prevalence of true added toxicity. We use a measurement of the amount of source contribution to the translation, where a low source contribution implies hallucination, to interpret what causes toxicity. We observe that the source contribution is somewhat correlated with toxicity but that 45.6% of added toxic words have a high source contribution, suggesting that much of the added toxicity may be due to mistranslations. Combining the signal of source contribution level with a measurement of translation robustness allows us to flag 22.3% of added toxicity, suggesting that added toxicity may be related to both hallucination and the stability of translations in different contexts. Given these findings, our recommendations to reduce added toxicity are to curate training data to avoid mistranslations, mitigate hallucination and check unstable translations.
Perturbation Augmentation for Fairer NLP
May 25, 2022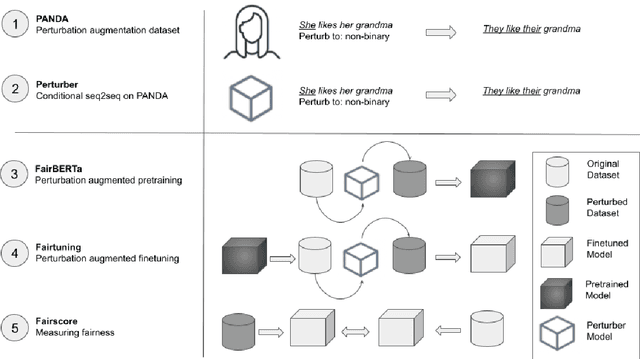
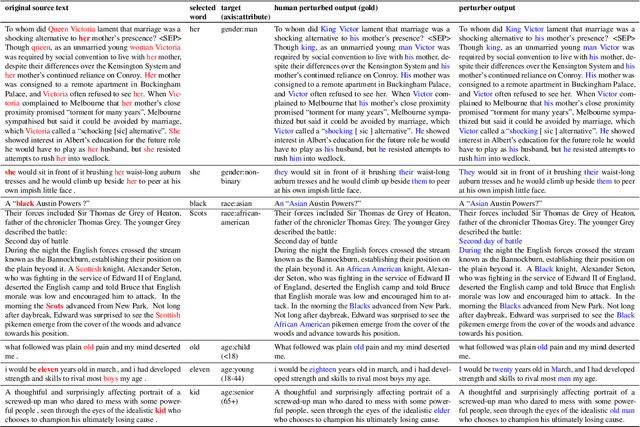
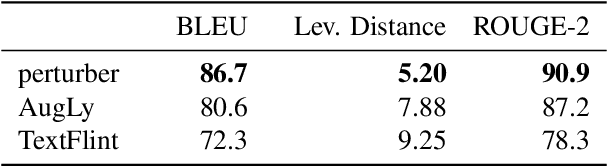
Unwanted and often harmful social biases are becoming ever more salient in NLP research, affecting both models and datasets. In this work, we ask: does training on demographically perturbed data lead to more fair language models? We collect a large dataset of human annotated text perturbations and train an automatic perturber on it, which we show to outperform heuristic alternatives. We find: (i) Language models (LMs) pre-trained on demographically perturbed corpora are more fair, at least, according to our current best metrics for measuring model fairness, and (ii) LMs finetuned on perturbed GLUE datasets exhibit less demographic bias on downstream tasks. We find that improved fairness does not come at the expense of accuracy. Although our findings appear promising, there are still some limitations, as well as outstanding questions about how best to evaluate the (un)fairness of large language models. We hope that this initial exploration of neural demographic perturbation will help drive more improvement towards fairer NLP.
On the universal structure of human lexical semantics
Apr 29, 2015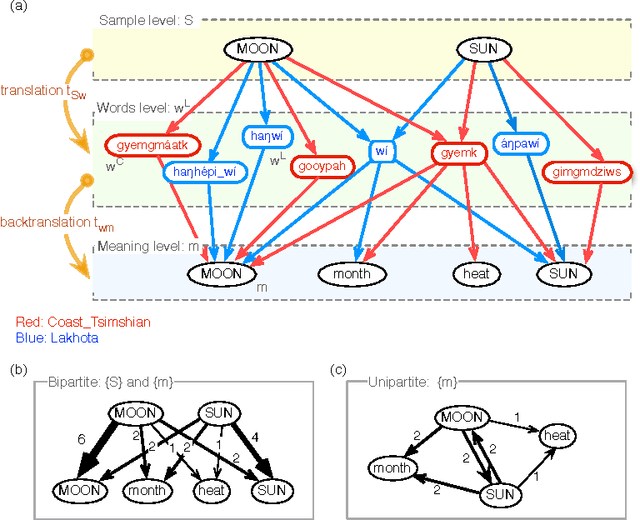
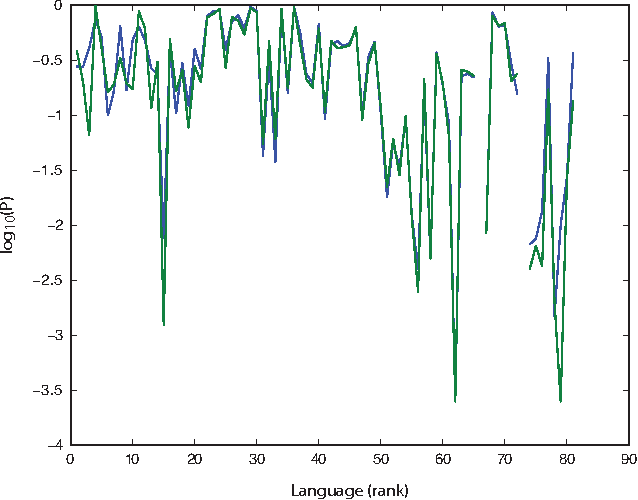
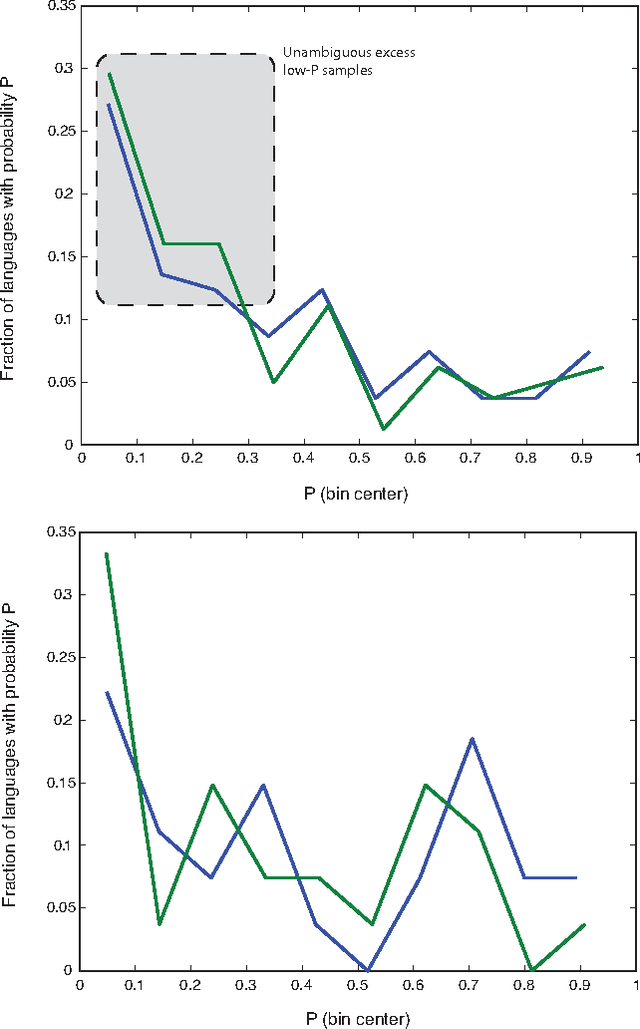
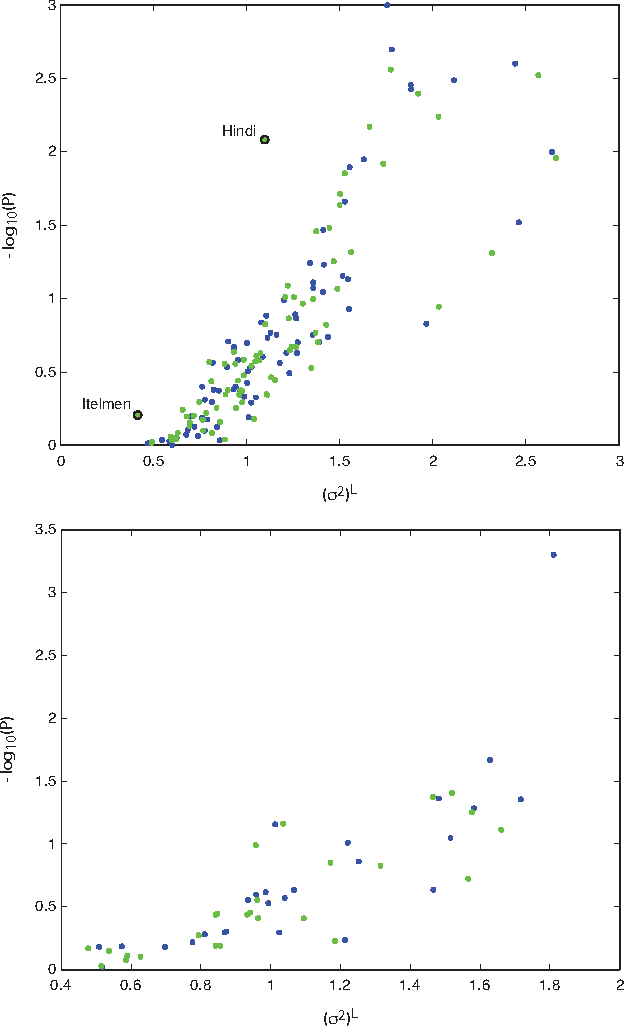
How universal is human conceptual structure? The way concepts are organized in the human brain may reflect distinct features of cultural, historical, and environmental background in addition to properties universal to human cognition. Semantics, or meaning expressed through language, provides direct access to the underlying conceptual structure, but meaning is notoriously difficult to measure, let alone parameterize. Here we provide an empirical measure of semantic proximity between concepts using cross-linguistic dictionaries. Across languages carefully selected from a phylogenetically and geographically stratified sample of genera, translations of words reveal cases where a particular language uses a single polysemous word to express concepts represented by distinct words in another. We use the frequency of polysemies linking two concepts as a measure of their semantic proximity, and represent the pattern of such linkages by a weighted network. This network is highly uneven and fragmented: certain concepts are far more prone to polysemy than others, and there emerge naturally interpretable clusters loosely connected to each other. Statistical analysis shows such structural properties are consistent across different language groups, largely independent of geography, environment, and literacy. It is therefore possible to conclude the conceptual structure connecting basic vocabulary studied is primarily due to universal features of human cognition and language use.
* Press embargo in place until publication