 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024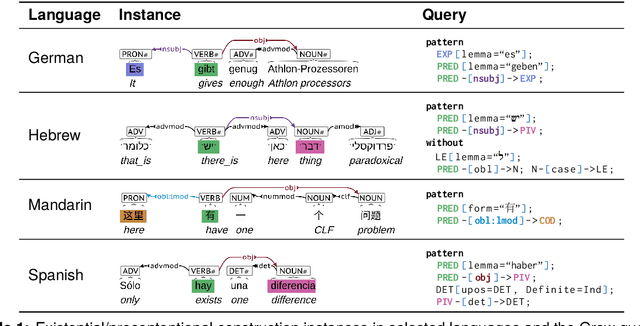
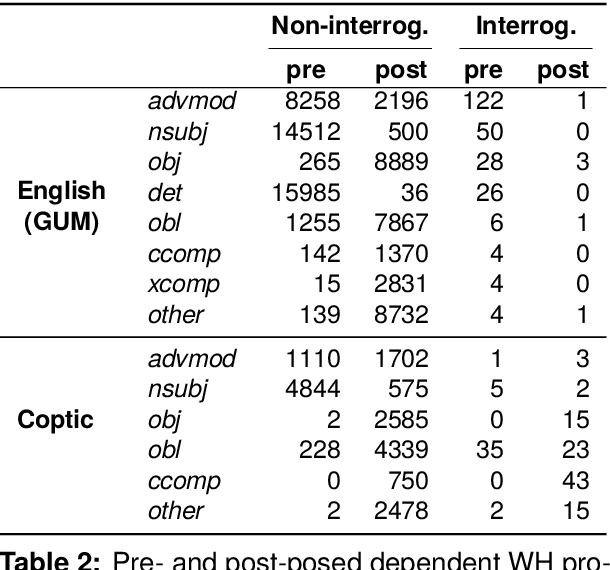
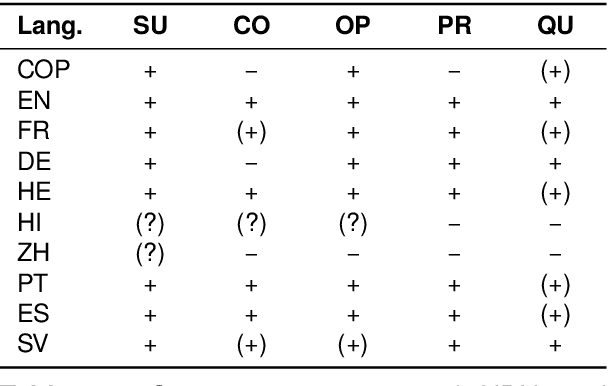
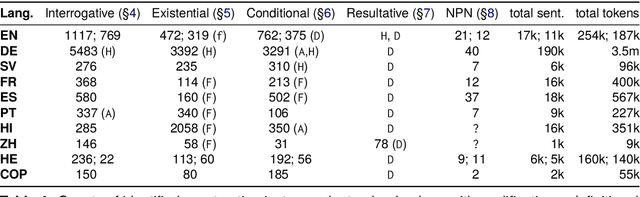
The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.
Predicting the Citation Count and CiteScore of Journals One Year in Advance
Oct 24, 2022Prediction of the future performance of academic journals is a task that can benefit a variety of stakeholders including editorial staff, publishers, indexing services, researchers, university administrators and granting agencies. Using historical data on journal performance, this can be framed as a machine learning regression problem. In this work, we study two such regression tasks: 1) prediction of the number of citations a journal will receive during the next calendar year, and 2) prediction of the Elsevier CiteScore a journal will be assigned for the next calendar year. To address these tasks, we first create a dataset of historical bibliometric data for journals indexed in Scopus. We propose the use of neural network models trained on our dataset to predict the future performance of journals. To this end, we perform feature selection and model configuration for a Multi-Layer Perceptron and a Long Short-Term Memory. Through experimental comparisons to heuristic prediction baselines and classical machine learning models, we demonstrate superior performance in our proposed models for the prediction of future citation and CiteScore values.
How individuals change language
Apr 20, 2021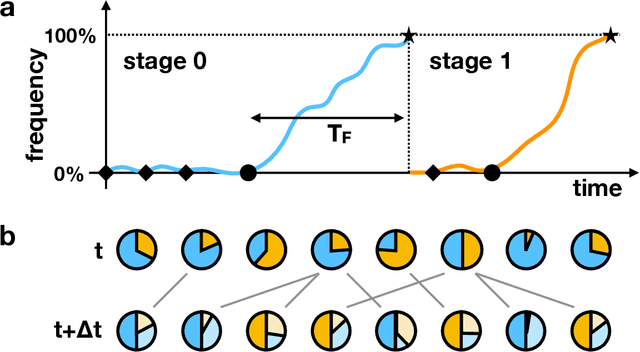

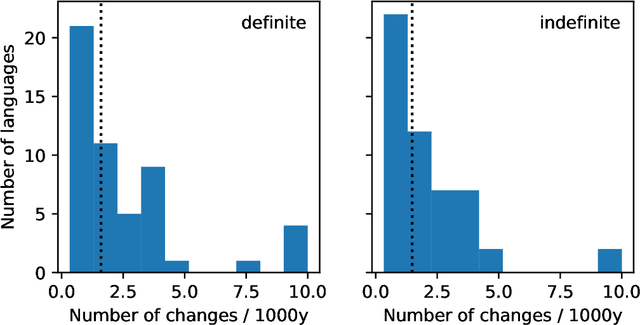

Languages emerge and change over time at the population level though interactions between individual speakers. It is, however, hard to directly observe how a single speaker's linguistic innovation precipitates a population-wide change in the language, and many theoretical proposals exist. We introduce a very general mathematical model that encompasses a wide variety of individual-level linguistic behaviours and provides statistical predictions for the population-level changes that result from them. This model allows us to compare the likelihood of empirically-attested changes in definite and indefinite articles in multiple languages under different assumptions on the way in which individuals learn and use language. We find that accounts of language change that appeal primarily to errors in childhood language acquisition are very weakly supported by the historical data, whereas those that allow speakers to change incrementally across the lifespan are more plausible, particularly when combined with social network effects.
On the universal structure of human lexical semantics
Apr 29, 2015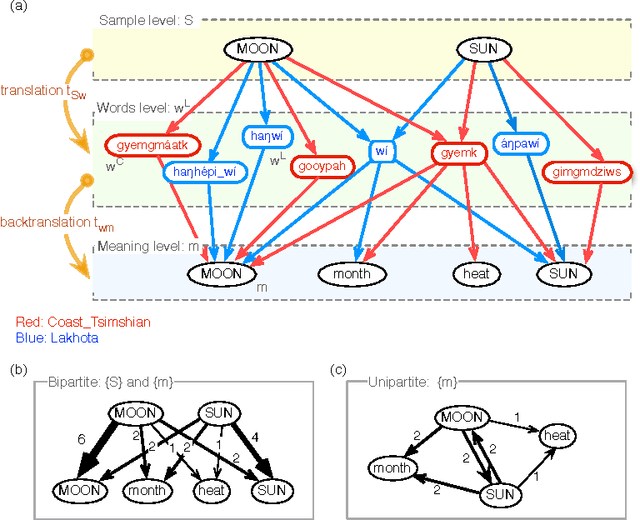
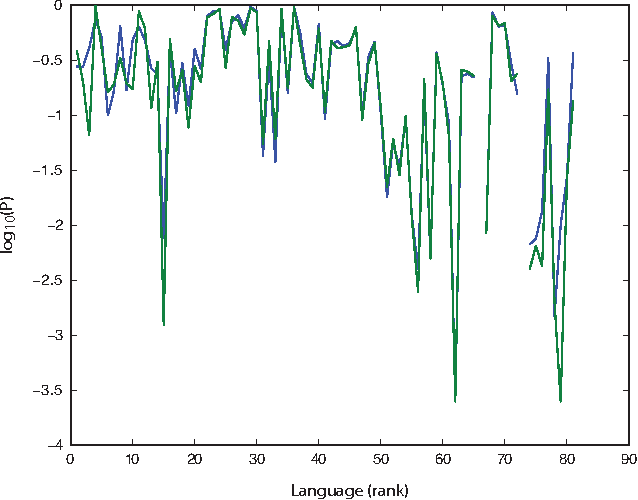
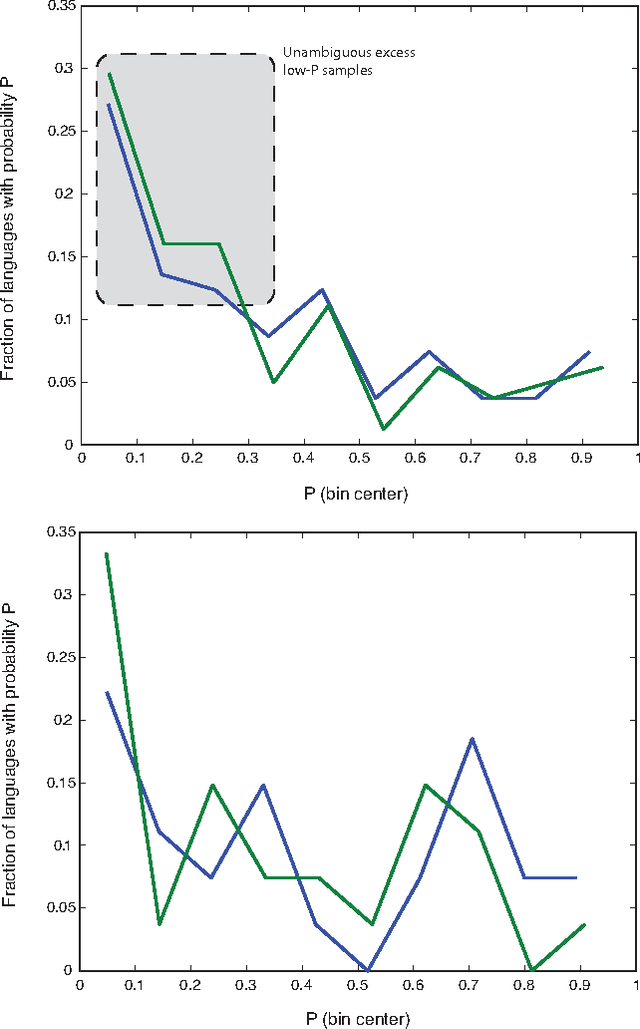
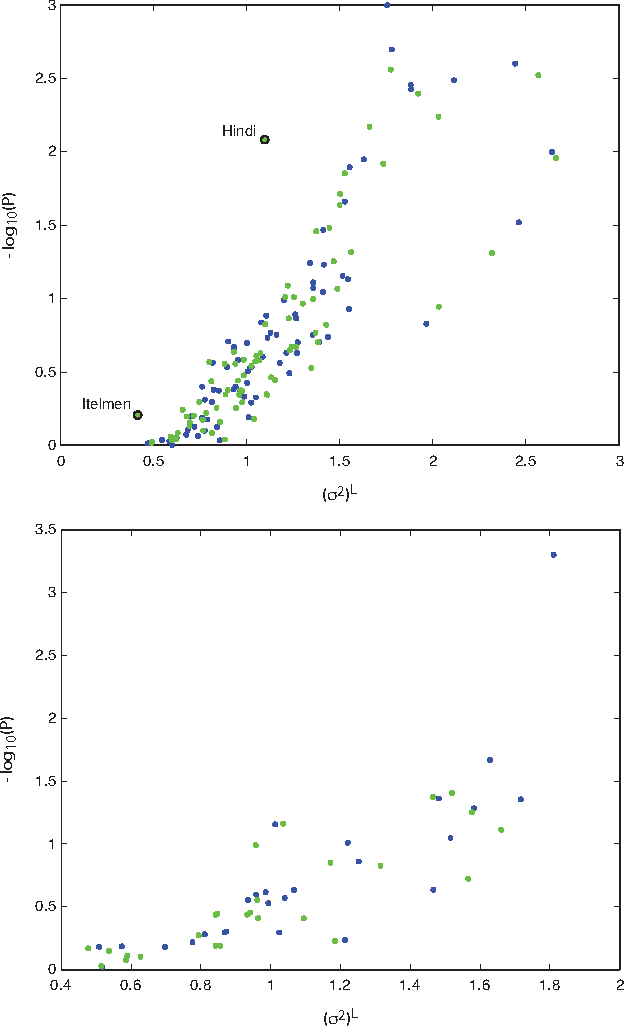
How universal is human conceptual structure? The way concepts are organized in the human brain may reflect distinct features of cultural, historical, and environmental background in addition to properties universal to human cognition. Semantics, or meaning expressed through language, provides direct access to the underlying conceptual structure, but meaning is notoriously difficult to measure, let alone parameterize. Here we provide an empirical measure of semantic proximity between concepts using cross-linguistic dictionaries. Across languages carefully selected from a phylogenetically and geographically stratified sample of genera, translations of words reveal cases where a particular language uses a single polysemous word to express concepts represented by distinct words in another. We use the frequency of polysemies linking two concepts as a measure of their semantic proximity, and represent the pattern of such linkages by a weighted network. This network is highly uneven and fragmented: certain concepts are far more prone to polysemy than others, and there emerge naturally interpretable clusters loosely connected to each other. Statistical analysis shows such structural properties are consistent across different language groups, largely independent of geography, environment, and literacy. It is therefore possible to conclude the conceptual structure connecting basic vocabulary studied is primarily due to universal features of human cognition and language use.
* Press embargo in place until publication