 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Logistic Regression with High-order Features for Automatic Grammar Rule Extraction from Treebanks
Mar 26, 2024



Descriptive grammars are highly valuable, but writing them is time-consuming and difficult. Furthermore, while linguists typically use corpora to create them, grammar descriptions often lack quantitative data. As for formal grammars, they can be challenging to interpret. In this paper, we propose a new method to extract and explore significant fine-grained grammar patterns and potential syntactic grammar rules from treebanks, in order to create an easy-to-understand corpus-based grammar. More specifically, we extract descriptions and rules across different languages for two linguistic phenomena, agreement and word order, using a large search space and paying special attention to the ranking order of the extracted rules. For that, we use a linear classifier to extract the most salient features that predict the linguistic phenomena under study. We associate statistical information to each rule, and we compare the ranking of the model's results to those of other quantitative and statistical measures. Our method captures both well-known and less well-known significant grammar rules in Spanish, French, and Wolof.
UCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024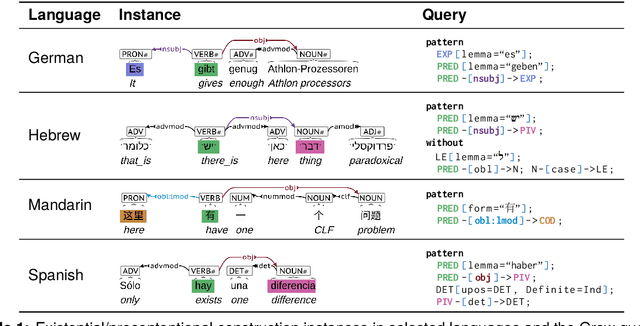
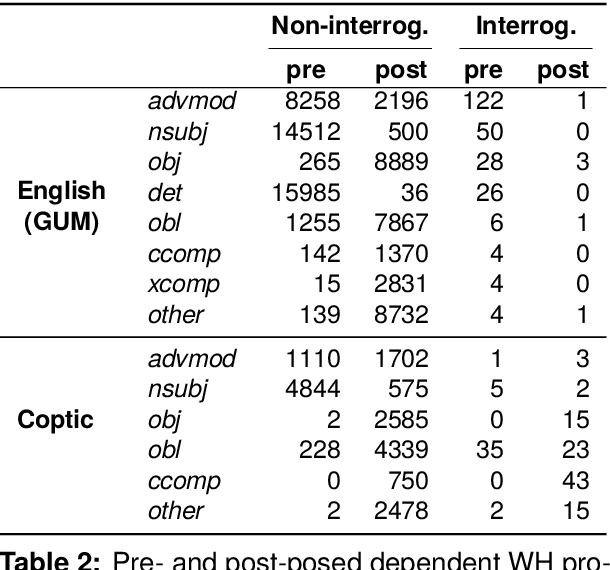
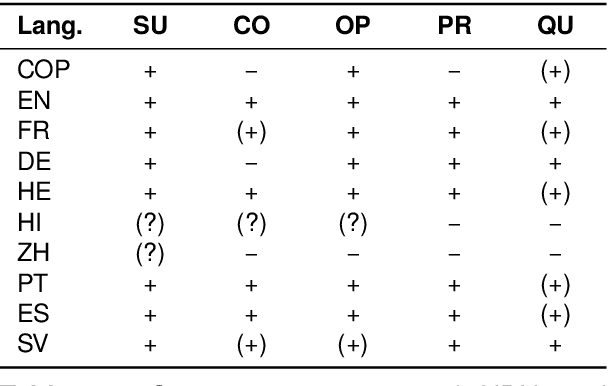
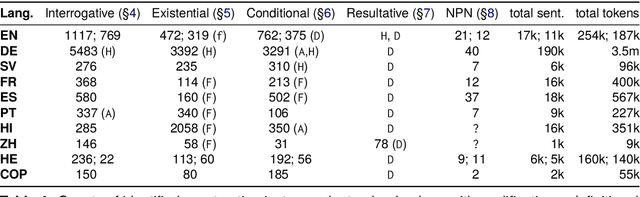
The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.