 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbation Augmentation for Fairer NLP
Paper and Code
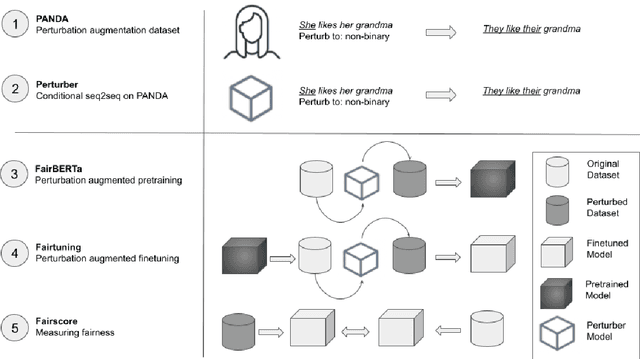
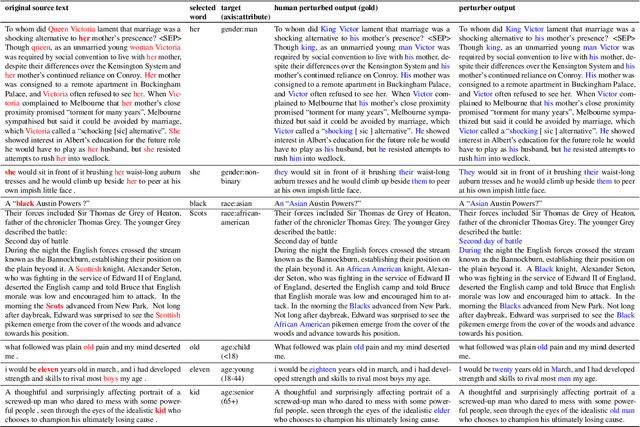
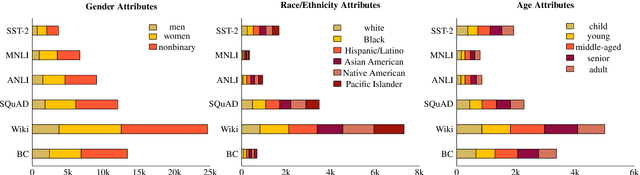
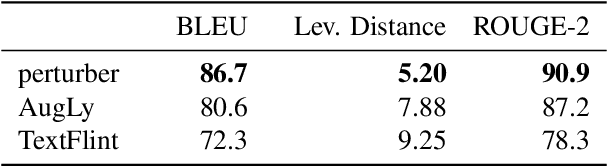
Unwanted and often harmful social biases are becoming ever more salient in NLP research, affecting both models and datasets. In this work, we ask: does training on demographically perturbed data lead to more fair language models? We collect a large dataset of human annotated text perturbations and train an automatic perturber on it, which we show to outperform heuristic alternatives. We find: (i) Language models (LMs) pre-trained on demographically perturbed corpora are more fair, at least, according to our current best metrics for measuring model fairness, and (ii) LMs finetuned on perturbed GLUE datasets exhibit less demographic bias on downstream tasks. We find that improved fairness does not come at the expense of accuracy. Although our findings appear promising, there are still some limitations, as well as outstanding questions about how best to evaluate the (un)fairness of large language models. We hope that this initial exploration of neural demographic perturbation will help drive more improvement towards fairer NLP.