 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale
Mar 16, 2026Real-time AI experiences call for on-device large language models (OD-LLMs) optimized for efficient deployment on resource-constrained hardware. The most useful OD-LLMs produce near-real-time responses and exhibit broad hardware compatibility, maximizing user reach. We present a methodology for designing such models using hardware-in-the-loop architecture search under mobile latency constraints. This system is amenable to industry-scale deployment: it generates models deployable without custom kernels and compatible with standard mobile runtimes like Executorch. Our methodology avoids specialized attention mechanisms and instead uses attention skipping for long-context acceleration. Our approach jointly optimizes model architecture (layers, dimensions) and attention pattern. To efficiently evaluate candidates, we treat each as a pruned version of a pretrained backbone with inherited weights, thereby achieving high accuracy with minimal continued pretraining. We leverage the low cost of latency evaluation in a staged process: learning an accurate latency model first, then searching for the Pareto-frontier across latency and quality. This yields MobileLLM-Flash, a family of foundation models (350M, 650M, 1.4B) for efficient on-device use with strong capabilities, supporting up to 8k context length. MobileLLM-Flash delivers up to 1.8x and 1.6x faster prefill and decode on mobile CPUs with comparable or superior quality. Our analysis of Pareto-frontier design choices offers actionable principles for OD-LLM design.
T-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Jan 27, 2026Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Nov 18, 2024This paper presents Llama Guard 3-1B-INT4, a compact and efficient Llama Guard model, which has been open-sourced to the community during Meta Connect 2024. We demonstrate that Llama Guard 3-1B-INT4 can be deployed on resource-constrained devices, achieving a throughput of at least 30 tokens per second and a time-to-first-token of 2.5 seconds or less on a commodity Android mobile CPU. Notably, our experiments show that Llama Guard 3-1B-INT4 attains comparable or superior safety moderation scores to its larger counterpart, Llama Guard 3-1B, despite being approximately 7 times smaller in size (440MB).
Towards Open-World Gesture Recognition
Jan 20, 2024



Static machine learning methods in gesture recognition assume that training and test data come from the same underlying distribution. However, in real-world applications involving gesture recognition on wrist-worn devices, data distribution may change over time. We formulate this problem of adapting recognition models to new tasks, where new data patterns emerge, as open-world gesture recognition (OWGR). We propose leveraging continual learning to make machine learning models adaptive to new tasks without degrading performance on previously learned tasks. However, the exploration of parameters for questions around when and how to train and deploy recognition models requires time-consuming user studies and is sometimes impractical. To address this challenge, we propose a design engineering approach that enables offline analysis on a collected large-scale dataset with various parameters and compares different continual learning methods. Finally, design guidelines are provided to enhance the development of an open-world wrist-worn gesture recognition process.
Collapsible Linear Blocks for Super-Efficient Super Resolution
Mar 17, 2021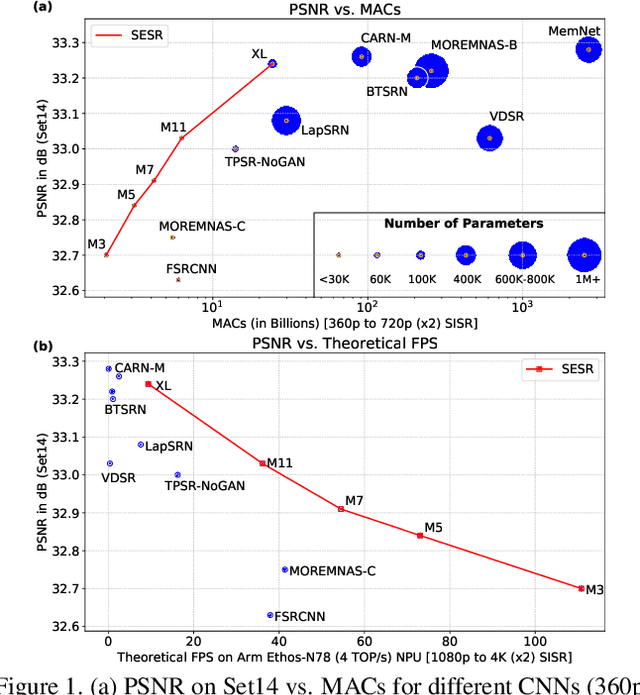
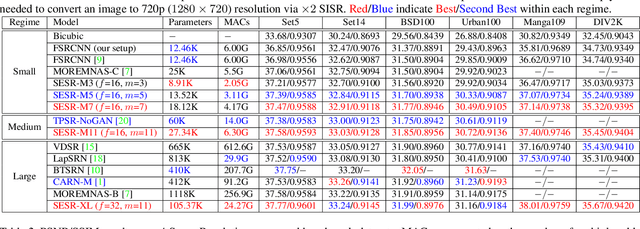
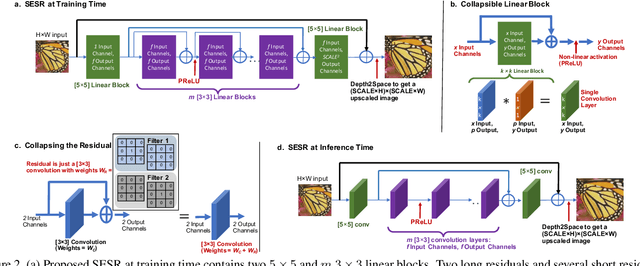
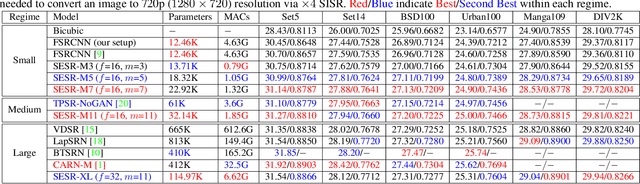
With the advent of smart devices that support 4K and 8K resolution, Single Image Super Resolution (SISR) has become an important computer vision problem. However, most super resolution deep networks are computationally very expensive. In this paper, we propose SESR, a new class of Super-Efficient Super Resolution networks that significantly improve image quality and reduce computational complexity. Detailed experiments across six benchmark datasets demonstrate that SESR achieves similar or better image quality than state-of-the-art models while requiring 2x to 330x fewer Multiply-Accumulate (MAC) operations. As a result, SESR can be used on constrained hardware to perform x2 (1080p to 4K) and x4 SISR (1080p to 8K). Towards this, we simulate hardware performance numbers for a commercial mobile Neural Processing Unit (NPU) for 1080p to 4K (x2) and 1080p to 8K (x4) SISR. Our results highlight the challenges faced by super resolution on AI accelerators and demonstrate that SESR is significantly faster than existing models. Overall, SESR establishes a new Pareto frontier on the quality (PSNR)-computation relationship for the super resolution task.
EdgeAI: A Vision for Deep Learning in IoT Era
Oct 23, 2019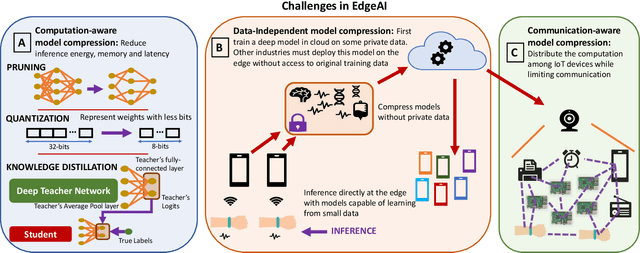
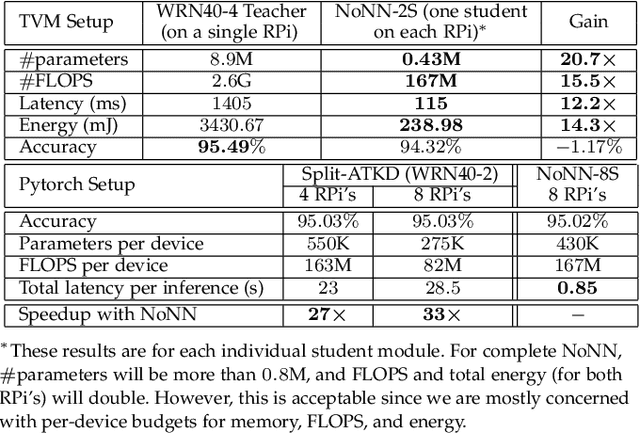
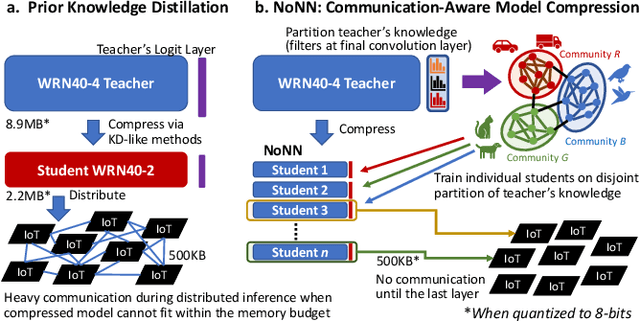
The significant computational requirements of deep learning present a major bottleneck for its large-scale adoption on hardware-constrained IoT-devices. Here, we envision a new paradigm called EdgeAI to address major impediments associated with deploying deep networks at the edge. Specifically, we discuss the existing directions in computation-aware deep learning and describe two new challenges in the IoT era: (1) Data-independent deployment of learning, and (2) Communication-aware distributed inference. We further present new directions from our recent research to alleviate the latter two challenges. Overcoming these challenges is crucial for rapid adoption of learning on IoT-devices in order to truly enable EdgeAI.
Dream Distillation: A Data-Independent Model Compression Framework
May 17, 2019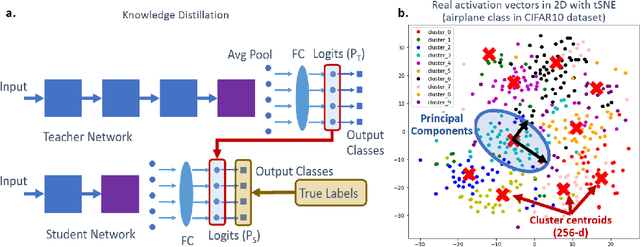
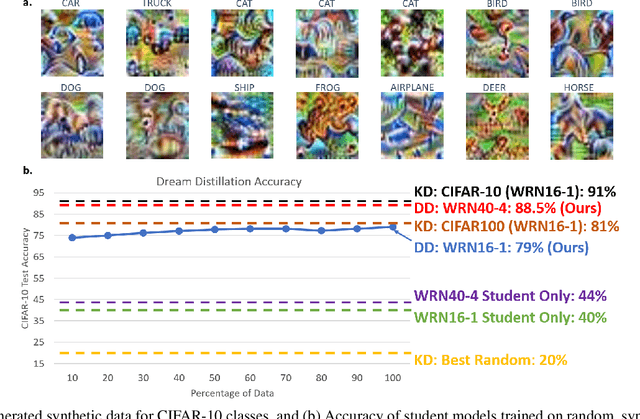
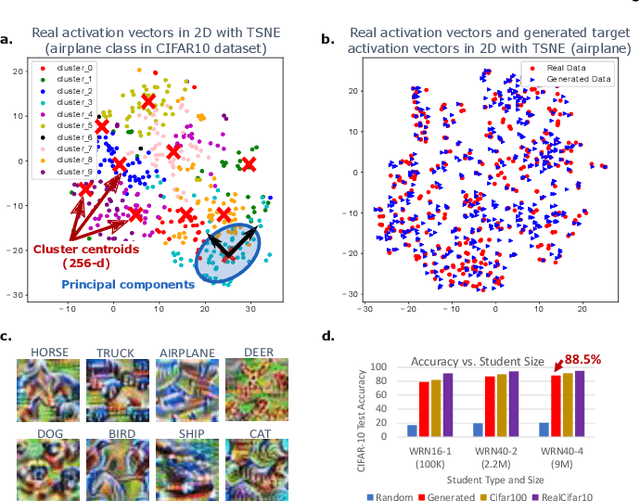
Model compression is eminently suited for deploying deep learning on IoT-devices. However, existing model compression techniques rely on access to the original or some alternate dataset. In this paper, we address the model compression problem when no real data is available, e.g., when data is private. To this end, we propose Dream Distillation, a data-independent model compression framework. Our experiments show that Dream Distillation can achieve 88.5% accuracy on the CIFAR-10 test set without actually training on the original data!
Rethinking Machine Learning Development and Deployment for Edge Devices
Jun 20, 2018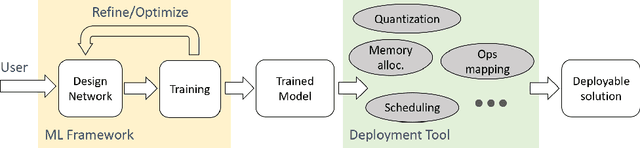



Machine learning (ML), especially deep learning is made possible by the availability of big data, enormous compute power and, often overlooked, development tools or frameworks. As the algorithms become mature and efficient, more and more ML inference is moving out of datacenters/cloud and deployed on edge devices. This model deployment process can be challenging as the deployment environment and requirements can be substantially different from those during model development. In this paper, we propose a new ML development and deployment approach that is specially designed and optimized for inference-only deployment on edge devices. We build a prototype and demonstrate that this approach can address all the deployment challenges and result in more efficient and high-quality solutions.
Federated Learning with Non-IID Data
Jun 02, 2018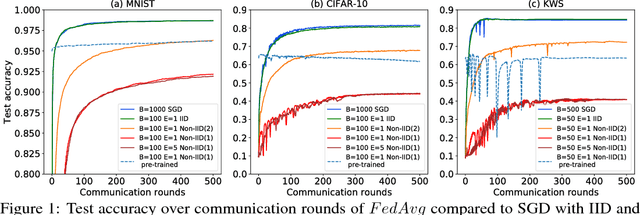
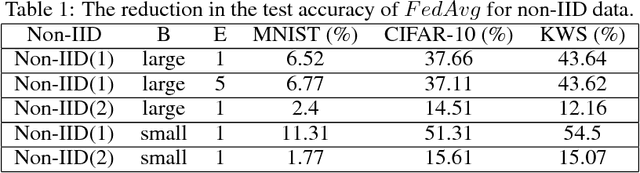
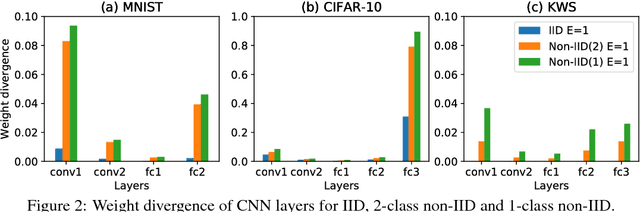
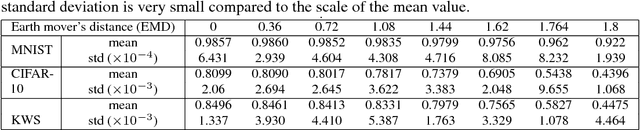
Federated learning enables resource-constrained edge compute devices, such as mobile phones and IoT devices, to learn a shared model for prediction, while keeping the training data local. This decentralized approach to train models provides privacy, security, regulatory and economic benefits. In this work, we focus on the statistical challenge of federated learning when local data is non-IID. We first show that the accuracy of federated learning reduces significantly, by up to 55% for neural networks trained for highly skewed non-IID data, where each client device trains only on a single class of data. We further show that this accuracy reduction can be explained by the weight divergence, which can be quantified by the earth mover's distance (EMD) between the distribution over classes on each device and the population distribution. As a solution, we propose a strategy to improve training on non-IID data by creating a small subset of data which is globally shared between all the edge devices. Experiments show that accuracy can be increased by 30% for the CIFAR-10 dataset with only 5% globally shared data.