 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFuse: Fusing Transformers and CNNs for Medical Image Segmentation
Feb 16, 2021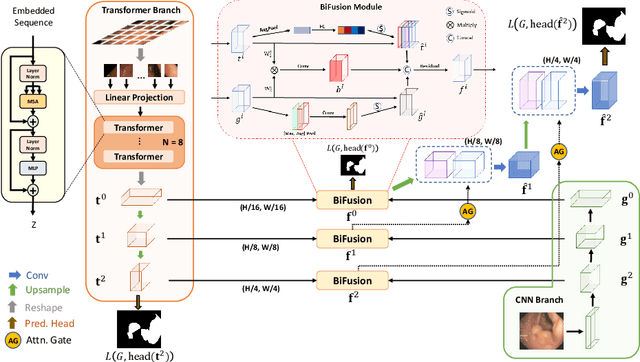
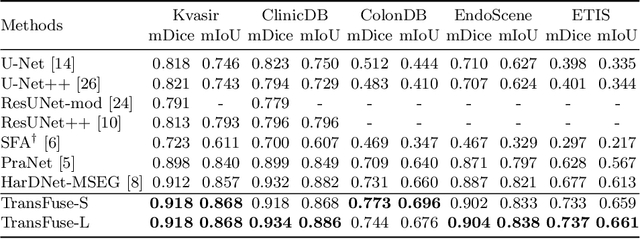


U-Net based convolutional neural networks with deep feature representation and skip-connections have significantly boosted the performance of medical image segmentation. In this paper, we study the more challenging problem of improving efficiency in modeling global contexts without losing localization ability for low-level details. TransFuse, a novel two-branch architecture is proposed, which combines Transformers and CNNs in a parallel style. With TransFuse, both global dependency and low-level spatial details can be efficiently captured in a much shallower manner. Besides, a novel fusion technique - BiFusion module is proposed to fuse the multi-level features from each branch. TransFuse achieves the newest state-of-the-arts on polyp segmentation task, with 20\% fewer parameters and the fastest inference speed at about 98.7 FPS.
Improve Model Generalization and Robustness to Dataset Bias with Bias-regularized Learning and Domain-guided Augmentation
Nov 13, 2019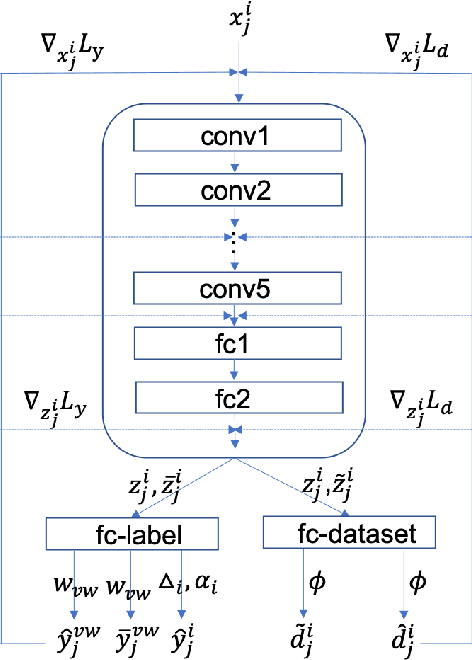
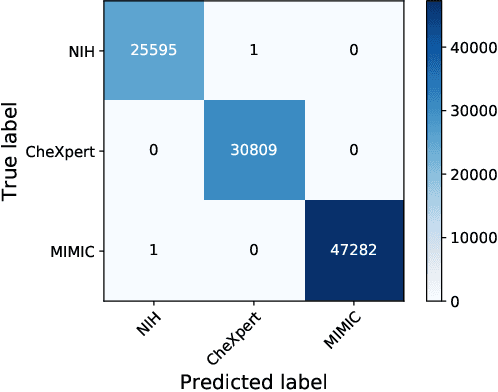

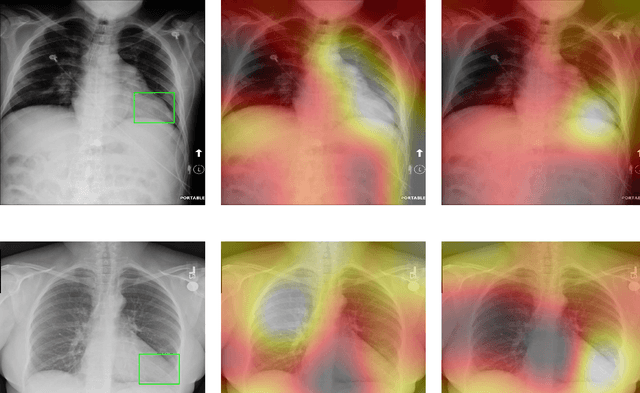
Deep Learning has thrived on the emergence of biomedical big data. However, medical datasets acquired at different institutions have inherent bias caused by various confounding factors such as operation policies, machine protocols, treatment preference and etc. As the result, models trained on one dataset, regardless of volume, cannot be confidently utilized for the others. In this study, we investigated model robustness to dataset bias using three large-scale Chest X-ray datasets: first, we assessed the dataset bias using vanilla training baseline; second, we proposed a novel multi-source domain generalization model by (a) designing a new bias-regularized loss function; and (b) synthesizing new data for domain augmentation. We showed that our model significantly outperformed the baseline and other approaches on data from unseen domain in terms of accuracy and various bias measures, without retraining or finetuning. Our method is generally applicable to other biomedical data, providing new algorithms for training models robust to bias for big data analysis and applications. Demo training code is publicly available.
Robust and High Performance Face Detector
Jan 06, 2019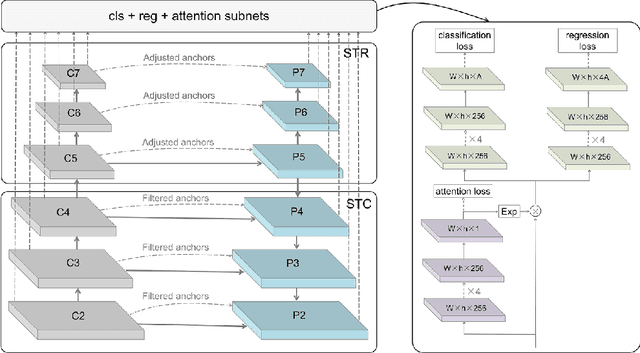
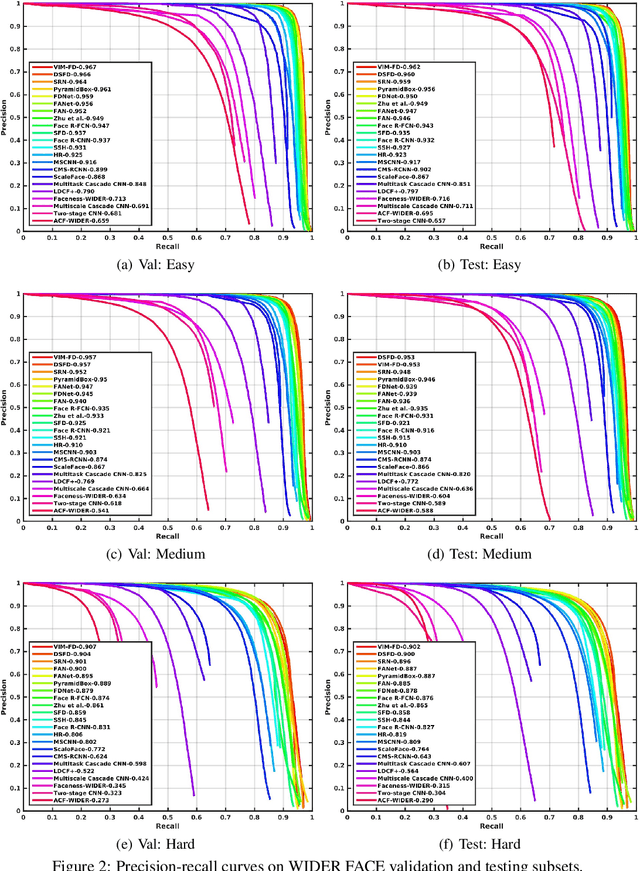


In recent years, face detection has experienced significant performance improvement with the boost of deep convolutional neural networks. In this report, we reimplement the state-of-the-art detector SRN and apply some tricks proposed in the recent literatures to obtain an extremely strong face detector, named VIM-FD. In specific, we exploit more powerful backbone network like DenseNet-121, revisit the data augmentation based on data-anchor-sampling proposed in PyramidBox, and use the max-in-out label and anchor matching strategy in SFD. In addition, we also introduce the attention mechanism to provide additional supervision. Over the most popular and challenging face detection benchmark, i.e., WIDER FACE, the proposed VIM-FD achieves state-of-the-art performance.
Interpretable Visual Question Answering by Visual Grounding from Attention Supervision Mining
Aug 01, 2018

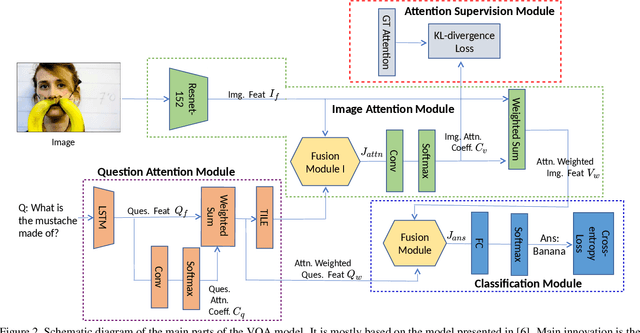
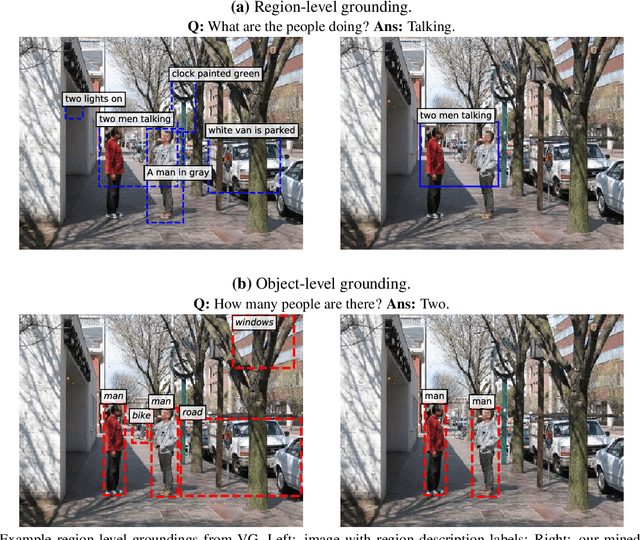
A key aspect of VQA models that are interpretable is their ability to ground their answers to relevant regions in the image. Current approaches with this capability rely on supervised learning and human annotated groundings to train attention mechanisms inside the VQA architecture. Unfortunately, obtaining human annotations specific for visual grounding is difficult and expensive. In this work, we demonstrate that we can effectively train a VQA architecture with grounding supervision that can be automatically obtained from available region descriptions and object annotations. We also show that our model trained with this mined supervision generates visual groundings that achieve a higher correlation with respect to manually-annotated groundings, meanwhile achieving state-of-the-art VQA accuracy.
Hello Edge: Keyword Spotting on Microcontrollers
Feb 14, 2018


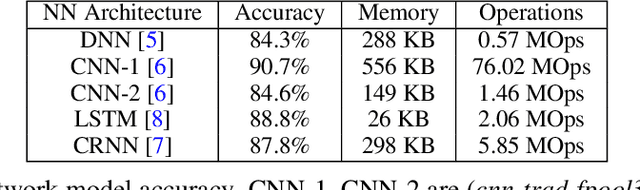
Keyword spotting (KWS) is a critical component for enabling speech based user interactions on smart devices. It requires real-time response and high accuracy for good user experience. Recently, neural networks have become an attractive choice for KWS architecture because of their superior accuracy compared to traditional speech processing algorithms. Due to its always-on nature, KWS application has highly constrained power budget and typically runs on tiny microcontrollers with limited memory and compute capability. The design of neural network architecture for KWS must consider these constraints. In this work, we perform neural network architecture evaluation and exploration for running KWS on resource-constrained microcontrollers. We train various neural network architectures for keyword spotting published in literature to compare their accuracy and memory/compute requirements. We show that it is possible to optimize these neural network architectures to fit within the memory and compute constraints of microcontrollers without sacrificing accuracy. We further explore the depthwise separable convolutional neural network (DS-CNN) and compare it against other neural network architectures. DS-CNN achieves an accuracy of 95.4%, which is ~10% higher than the DNN model with similar number of parameters.