 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Artificial Intelligence Methods in Combating Pandemics: A Systematic Review
Dec 25, 2021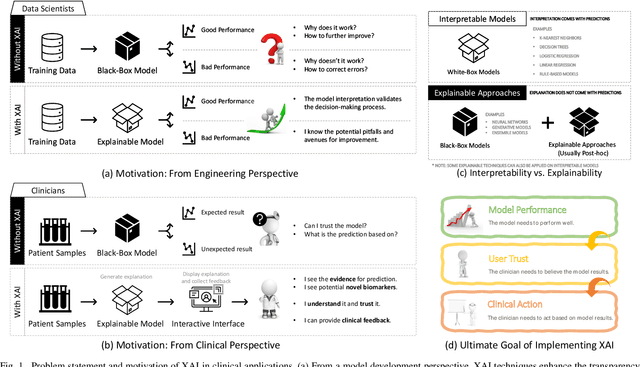
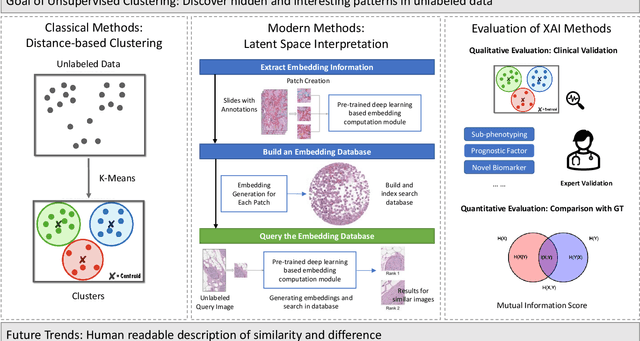
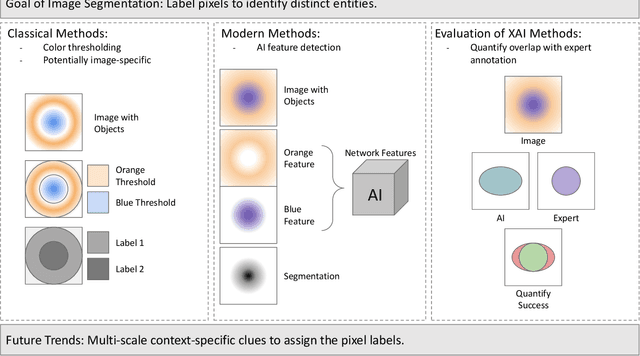
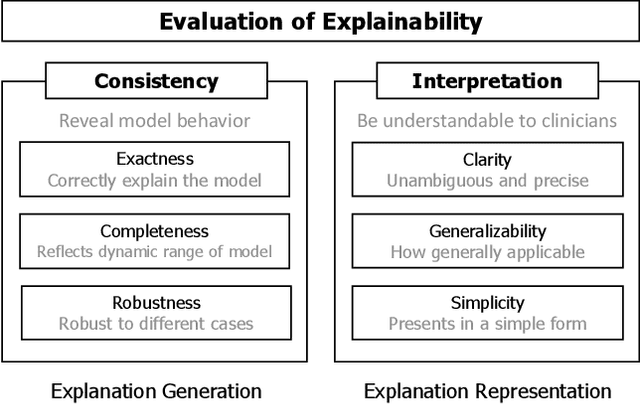
Despite the myriad peer-reviewed papers demonstrating novel Artificial Intelligence (AI)-based solutions to COVID-19 challenges during the pandemic, few have made significant clinical impact. The impact of artificial intelligence during the COVID-19 pandemic was greatly limited by lack of model transparency. This systematic review examines the use of Explainable Artificial Intelligence (XAI) during the pandemic and how its use could overcome barriers to real-world success. We find that successful use of XAI can improve model performance, instill trust in the end-user, and provide the value needed to affect user decision-making. We introduce the reader to common XAI techniques, their utility, and specific examples of their application. Evaluation of XAI results is also discussed as an important step to maximize the value of AI-based clinical decision support systems. We illustrate the classical, modern, and potential future trends of XAI to elucidate the evolution of novel XAI techniques. Finally, we provide a checklist of suggestions during the experimental design process supported by recent publications. Common challenges during the implementation of AI solutions are also addressed with specific examples of potential solutions. We hope this review may serve as a guide to improve the clinical impact of future AI-based solutions.
Neural encoding and interpretation for high-level visual cortices based on fMRI using image caption features
Mar 26, 2020

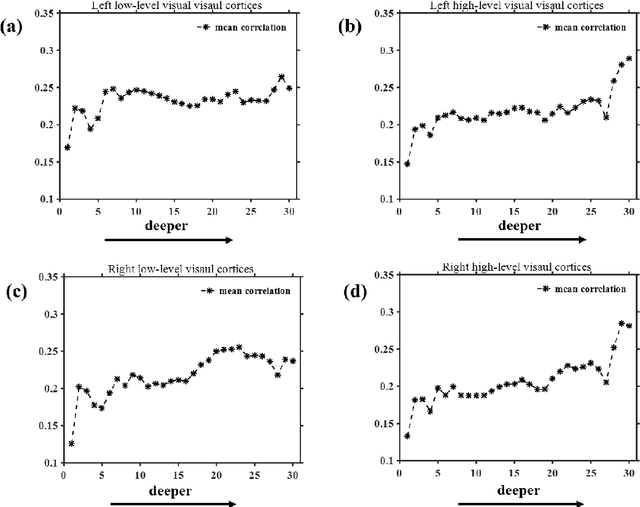

On basis of functional magnetic resonance imaging (fMRI), researchers are devoted to designing visual encoding models to predict the neuron activity of human in response to presented image stimuli and analyze inner mechanism of human visual cortices. Deep network structure composed of hierarchical processing layers forms deep network models by learning features of data on specific task through big dataset. Deep network models have powerful and hierarchical representation of data, and have brought about breakthroughs for visual encoding, while revealing hierarchical structural similarity with the manner of information processing in human visual cortices. However, previous studies almost used image features of those deep network models pre-trained on classification task to construct visual encoding models. Except for deep network structure, the task or corresponding big dataset is also important for deep network models, but neglected by previous studies. Because image classification is a relatively fundamental task, it is difficult to guide deep network models to master high-level semantic representations of data, which causes into that encoding performance for high-level visual cortices is limited. In this study, we introduced one higher-level vision task: image caption (IC) task and proposed the visual encoding model based on IC features (ICFVEM) to encode voxels of high-level visual cortices. Experiment demonstrated that ICFVEM obtained better encoding performance than previous deep network models pre-trained on classification task. In addition, the interpretation of voxels was realized to explore the detailed characteristics of voxels based on the visualization of semantic words, and comparative analysis implied that high-level visual cortices behaved the correlative representation of image content.
BigGAN-based Bayesian reconstruction of natural images from human brain activity
Mar 13, 2020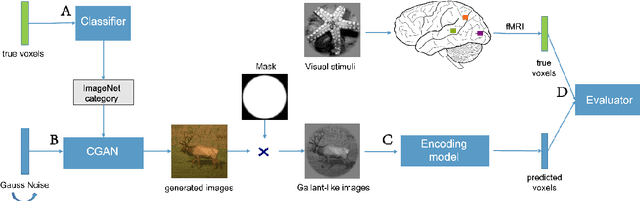



In the visual decoding domain, visually reconstructing presented images given the corresponding human brain activity monitored by functional magnetic resonance imaging (fMRI) is difficult, especially when reconstructing viewed natural images. Visual reconstruction is a conditional image generation on fMRI data and thus generative adversarial network (GAN) for natural image generation is recently introduced for this task. Although GAN-based methods have greatly improved, the fidelity and naturalness of reconstruction are still unsatisfactory due to the small number of fMRI data samples and the instability of GAN training. In this study, we proposed a new GAN-based Bayesian visual reconstruction method (GAN-BVRM) that includes a classifier to decode categories from fMRI data, a pre-trained conditional generator to generate natural images of specified categories, and a set of encoding models and evaluator to evaluate generated images. GAN-BVRM employs the pre-trained generator of the prevailing BigGAN to generate masses of natural images, and selects the images that best matches with the corresponding brain activity through the encoding models as the reconstruction of the image stimuli. In this process, the semantic and detailed contents of reconstruction are controlled by decoded categories and encoding models, respectively. GAN-BVRM used the Bayesian manner to avoid contradiction between naturalness and fidelity from current GAN-based methods and thus can improve the advantages of GAN. Experimental results revealed that GAN-BVRM improves the fidelity and naturalness, that is, the reconstruction is natural and similar to the presented image stimuli.
Improve Model Generalization and Robustness to Dataset Bias with Bias-regularized Learning and Domain-guided Augmentation
Nov 13, 2019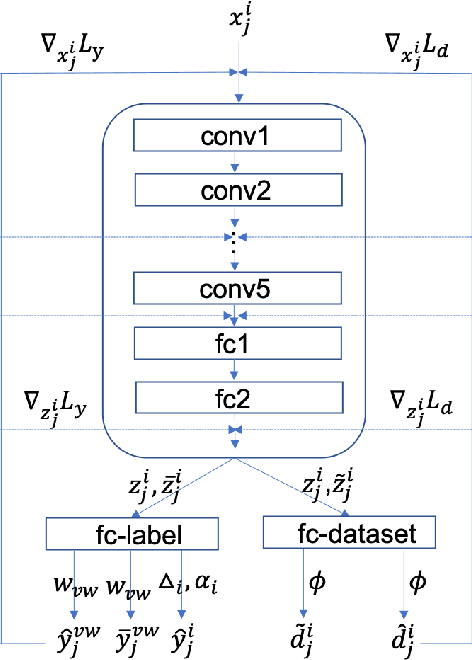
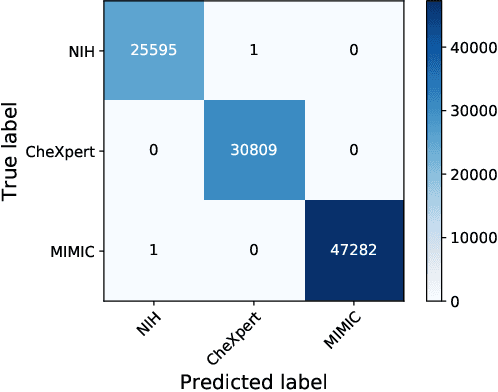

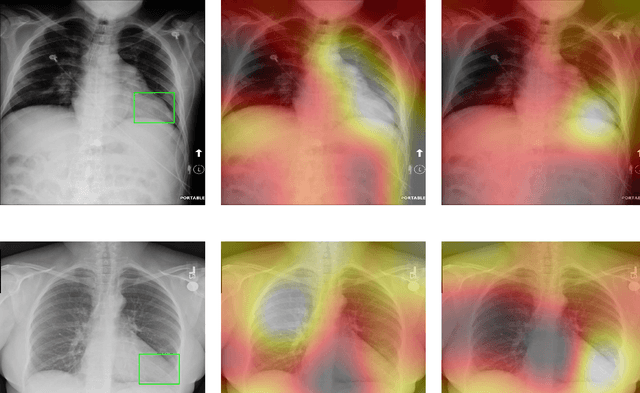
Deep Learning has thrived on the emergence of biomedical big data. However, medical datasets acquired at different institutions have inherent bias caused by various confounding factors such as operation policies, machine protocols, treatment preference and etc. As the result, models trained on one dataset, regardless of volume, cannot be confidently utilized for the others. In this study, we investigated model robustness to dataset bias using three large-scale Chest X-ray datasets: first, we assessed the dataset bias using vanilla training baseline; second, we proposed a novel multi-source domain generalization model by (a) designing a new bias-regularized loss function; and (b) synthesizing new data for domain augmentation. We showed that our model significantly outperformed the baseline and other approaches on data from unseen domain in terms of accuracy and various bias measures, without retraining or finetuning. Our method is generally applicable to other biomedical data, providing new algorithms for training models robust to bias for big data analysis and applications. Demo training code is publicly available.
Effective and efficient ROI-wise visual encoding using an end-to-end CNN regression model and selective optimization
Jul 27, 2019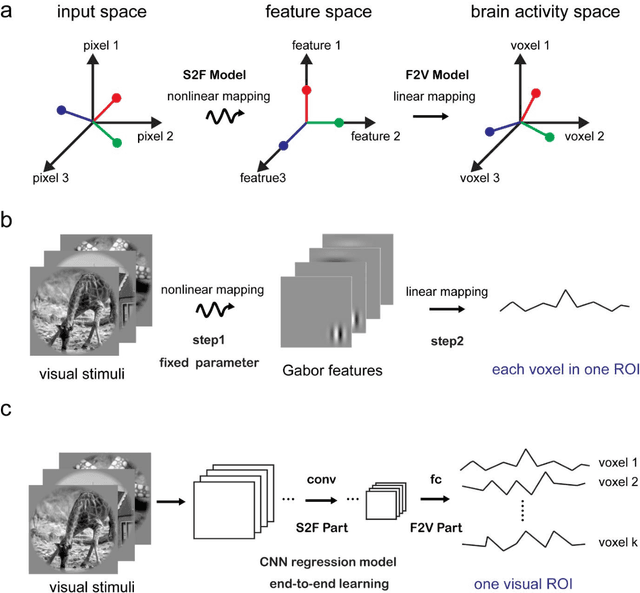

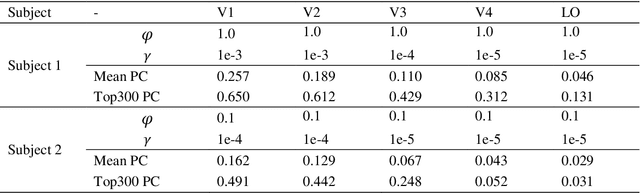
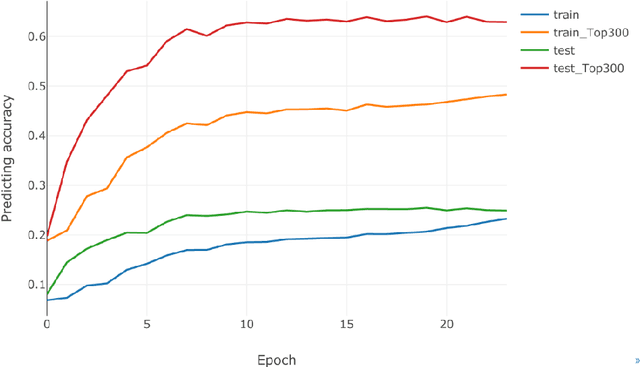
Recently, visual encoding based on functional magnetic resonance imaging (fMRI) have realized many achievements with the rapid development of deep network computation. Visual encoding model is aimed at predicting brain activity in response to presented image stimuli. Currently, visual encoding is accomplished mainly by firstly extracting image features through convolutional neural network (CNN) model pre-trained on computer vision task, and secondly training a linear regression model to map specific layer of CNN features to each voxel, namely voxel-wise encoding. However, the two-step manner model, essentially, is hard to determine which kind of well features are well linearly matched for beforehand unknown fMRI data with little understanding of human visual representation. Analogizing computer vision mostly related human vision, we proposed the end-to-end convolution regression model (ETECRM) in the region of interest (ROI)-wise manner to accomplish effective and efficient visual encoding. The end-to-end manner was introduced to make the model automatically learn better matching features to improve encoding performance. The ROI-wise manner was used to improve the encoding efficiency for many voxels. In addition, we designed the selective optimization including self-adapting weight learning and weighted correlation loss, noise regularization to avoid interfering of ineffective voxels in ROI-wise encoding. Experiment demonstrated that the proposed model obtained better predicting accuracy than the two-step manner of encoding models. Comparative analysis implied that end-to-end manner and large volume of fMRI data may drive the future development of visual encoding.
A visual encoding model based on deep neural networks and transfer learning
Feb 23, 2019



Background: Building visual encoding models to accurately predict visual responses is a central challenge for current vision-based brain-machine interface techniques. To achieve high prediction accuracy on neural signals, visual encoding models should include precise visual features and appropriate prediction algorithms. Most existing visual encoding models employ hand-craft visual features (e.g., Gabor wavelets or semantic labels) or data-driven features (e.g., features extracted from deep neural networks (DNN)). They also assume a linear mapping between feature representation to brain activity. However, it remains unknown whether such linear mapping is sufficient for maximizing prediction accuracy. New Method: We construct a new visual encoding framework to predict cortical responses in a benchmark functional magnetic resonance imaging (fMRI) dataset. In this framework, we employ the transfer learning technique to incorporate a pre-trained DNN (i.e., AlexNet) and train a nonlinear mapping from visual features to brain activity. This nonlinear mapping replaces the conventional linear mapping and is supposed to improve prediction accuracy on brain activity. Results: The proposed framework can significantly predict responses of over 20% voxels in early visual areas (i.e., V1-lateral occipital region, LO) and achieve unprecedented prediction accuracy. Comparison with Existing Methods: Comparing to two conventional visual encoding models, we find that the proposed encoding model shows consistent higher prediction accuracy in all early visual areas, especially in relatively anterior visual areas (i.e., V4 and LO). Conclusions: Our work proposes a new framework to utilize pre-trained visual features and train non-linear mappings from visual features to brain activity.
Dissociable neural representations of adversarially perturbed images in deep neural networks and the human brain
Dec 22, 2018
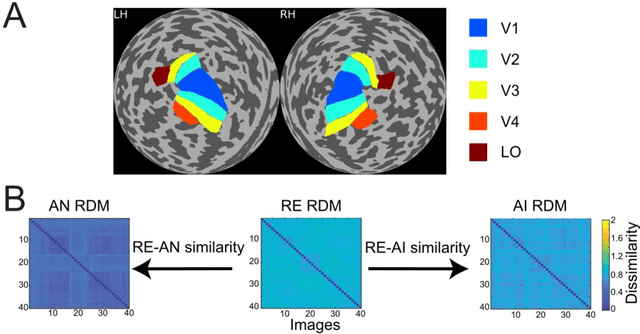
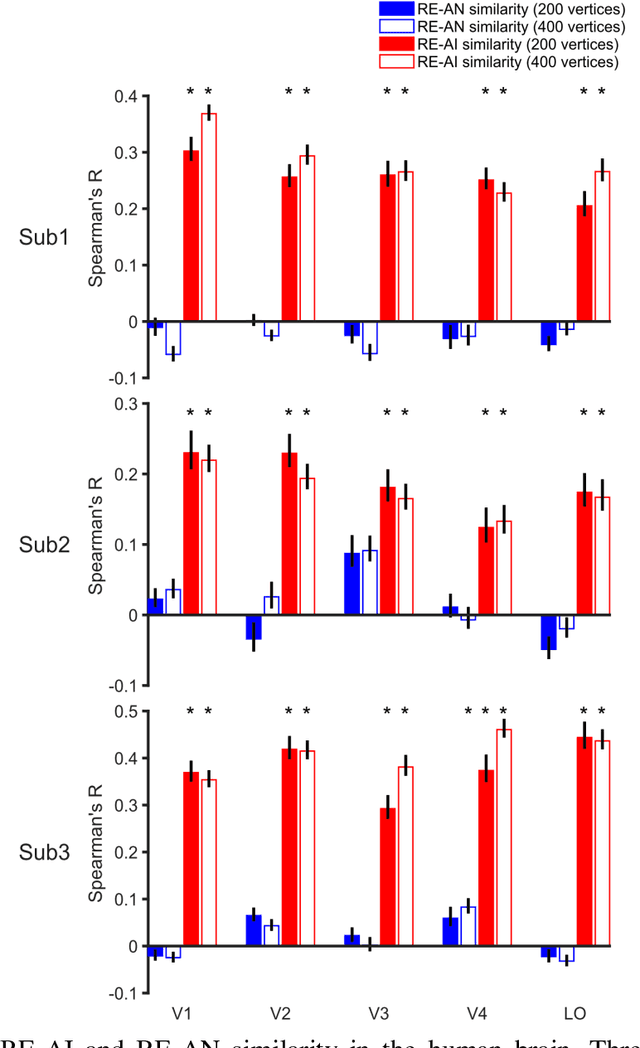
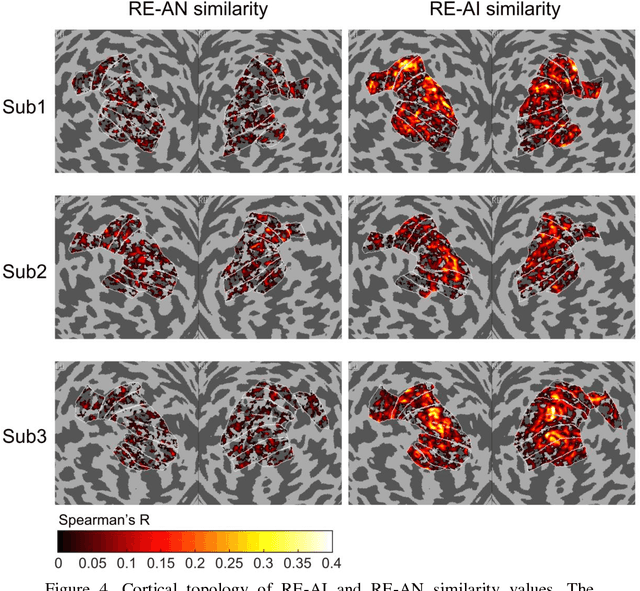
Despite the remarkable similarities between deep neural networks (DNN) and the human brain as shown in previous studies, the fact that DNNs still fall behind humans in many visual tasks suggests that considerable differences still exist between the two systems. To probe their dissimilarities, we leverage adversarial noise (AN) and adversarial interference (AI) images that yield distinct recognition performance in a prototypical DNN (AlexNet) and human vision. The evoked activity by regular (RE) and adversarial images in both systems is thoroughly compared. We find that representational similarity between RE and adversarial images in the human brain resembles their perceptual similarity. However, such representation-perception association is disrupted in the DNN. Especially, the representational similarity between RE and AN images idiosyncratically increases from low- to high-level layers. Furthermore, forward encoding modeling reveals that the DNN-brain hierarchical correspondence proposed in previous studies only holds when the two systems process RE and AI images but not AN images. These results might be due to the deterministic modeling approach of current DNNs. Taken together, our results provide a complementary perspective on the comparison between DNNs and the human brain, and highlight the need to characterize their differences to further bridge artificial and human intelligence research.
Constraint-free Natural Image Reconstruction from fMRI Signals Based on Convolutional Neural Network
Jan 16, 2018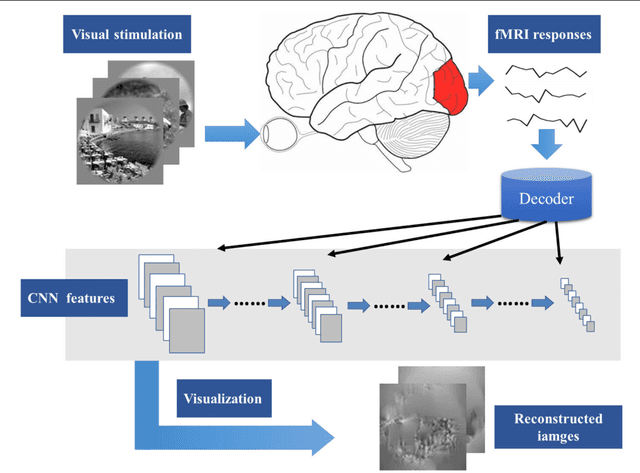


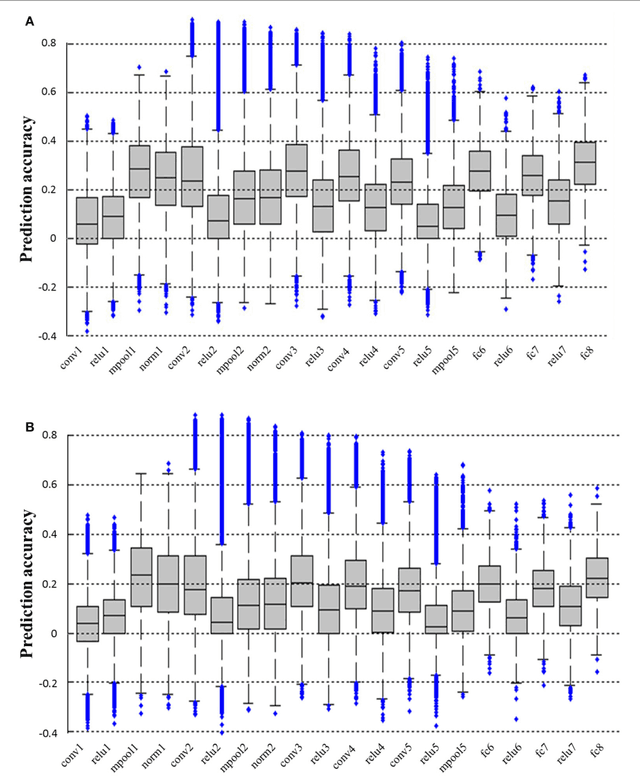
In recent years, research on decoding brain activity based on functional magnetic resonance imaging (fMRI) has made remarkable achievements. However, constraint-free natural image reconstruction from brain activity is still a challenge. The existing methods simplified the problem by using semantic prior information or just reconstructing simple images such as letters and digitals. Without semantic prior information, we present a novel method to reconstruct nature images from fMRI signals of human visual cortex based on the computation model of convolutional neural network (CNN). Firstly, we extracted the units output of viewed natural images in each layer of a pre-trained CNN as CNN features. Secondly, we transformed image reconstruction from fMRI signals into the problem of CNN feature visualizations by training a sparse linear regression to map from the fMRI patterns to CNN features. By iteratively optimization to find the matched image, whose CNN unit features become most similar to those predicted from the brain activity, we finally achieved the promising results for the challenging constraint-free natural image reconstruction. As there was no use of semantic prior information of the stimuli when training decoding model, any category of images (not constraint by the training set) could be reconstructed theoretically. We found that the reconstructed images resembled the natural stimuli, especially in position and shape. The experimental results suggest that hierarchical visual features can effectively express the visual perception process of human brain.
Accurate reconstruction of image stimuli from human fMRI based on the decoding model with capsule network architecture
Jan 02, 2018

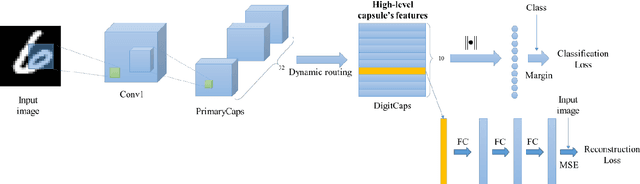

In neuroscience, all kinds of computation models were designed to answer the open question of how sensory stimuli are encoded by neurons and conversely, how sensory stimuli can be decoded from neuronal activities. Especially, functional Magnetic Resonance Imaging (fMRI) studies have made many great achievements with the rapid development of the deep network computation. However, comparing with the goal of decoding orientation, position and object category from activities in visual cortex, accurate reconstruction of image stimuli from human fMRI is a still challenging work. In this paper, the capsule network (CapsNet) architecture based visual reconstruction (CNAVR) method is developed to reconstruct image stimuli. The capsule means containing a group of neurons to perform the better organization of feature structure and representation, inspired by the structure of cortical mini column including several hundred neurons in primates. The high-level capsule features in the CapsNet includes diverse features of image stimuli such as semantic class, orientation, location and so on. We used these features to bridge between human fMRI and image stimuli. We firstly employed the CapsNet to train the nonlinear mapping from image stimuli to high-level capsule features, and from high-level capsule features to image stimuli again in an end-to-end manner. After estimating the serviceability of each voxel by encoding performance to accomplish the selecting of voxels, we secondly trained the nonlinear mapping from dimension-decreasing fMRI data to high-level capsule features. Finally, we can predict the high-level capsule features with fMRI data, and reconstruct image stimuli with the CapsNet. We evaluated the proposed CNAVR method on the dataset of handwritten digital images, and exceeded about 10% than the accuracy of all existing state-of-the-art methods on the structural similarity index (SSIM).