 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Pretraining Model based on Multi-Scale Local Visual Field Feature Reconstruction for PCB CT Image Element Segmentation
May 09, 2024



Element segmentation is a key step in nondestructive testing of Printed Circuit Boards (PCB) based on Computed Tomography (CT) technology. In recent years, the rapid development of self-supervised pretraining technology can obtain general image features without labeled samples, and then use a small amount of labeled samples to solve downstream tasks, which has a good potential in PCB element segmentation. At present, Masked Image Modeling (MIM) pretraining model has been initially applied in PCB CT image element segmentation. However, due to the small and regular size of PCB elements such as vias, wires, and pads, the global visual field has redundancy for a single element reconstruction, which may damage the performance of the model. Based on this issue, we propose an efficient pretraining model based on multi-scale local visual field feature reconstruction for PCB CT image element segmentation (EMLR-seg). In this model, the teacher-guided MIM pretraining model is introduced into PCB CT image element segmentation for the first time, and a multi-scale local visual field extraction (MVE) module is proposed to reduce redundancy by focusing on local visual fields. At the same time, a simple 4-Transformer-blocks decoder is used. Experiments show that EMLR-seg can achieve 88.6% mIoU on the PCB CT image dataset we proposed, which exceeds 1.2% by the baseline model, and the training time is reduced by 29.6 hours, a reduction of 17.4% under the same experimental condition, which reflects the advantage of EMLR-seg in terms of performance and efficiency.
Muti-scale Graph Neural Network with Signed-attention for Social Bot Detection: A Frequency Perspective
Jul 05, 2023



The presence of a large number of bots on social media has adverse effects. The graph neural network (GNN) can effectively leverage the social relationships between users and achieve excellent results in detecting bots. Recently, more and more GNN-based methods have been proposed for bot detection. However, the existing GNN-based bot detection methods only focus on low-frequency information and seldom consider high-frequency information, which limits the representation ability of the model. To address this issue, this paper proposes a Multi-scale with Signed-attention Graph Filter for social bot detection called MSGS. MSGS could effectively utilize both high and low-frequency information in the social graph. Specifically, MSGS utilizes a multi-scale structure to produce representation vectors at different scales. These representations are then combined using a signed-attention mechanism. Finally, multi-scale representations via MLP after polymerization to produce the final result. We analyze the frequency response and demonstrate that MSGS is a more flexible and expressive adaptive graph filter. MSGS can effectively utilize high-frequency information to alleviate the over-smoothing problem of deep GNNs. Experimental results on real-world datasets demonstrate that our method achieves better performance compared with several state-of-the-art social bot detection methods.
RF-GNN: Random Forest Boosted Graph Neural Network for Social Bot Detection
Apr 14, 2023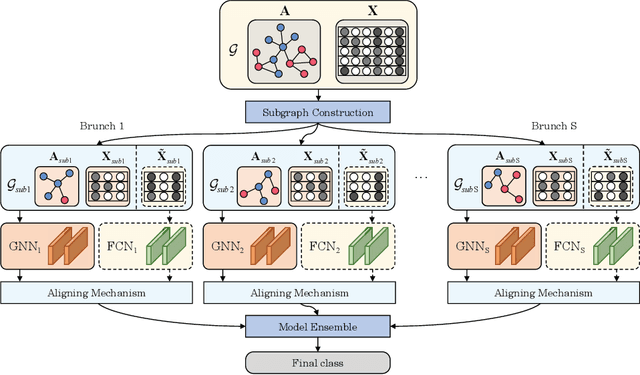
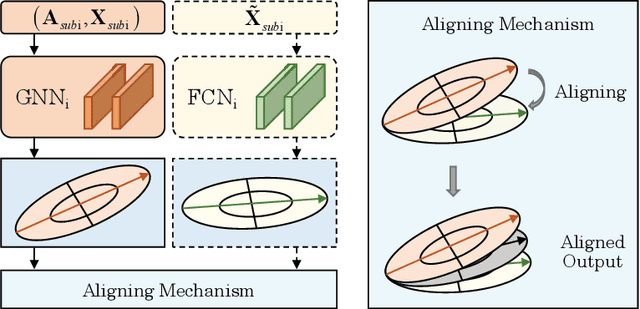
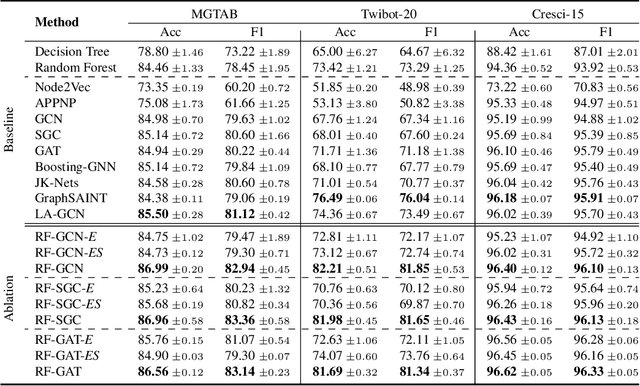
The presence of a large number of bots on social media leads to adverse effects. Although Random forest algorithm is widely used in bot detection and can significantly enhance the performance of weak classifiers, it cannot utilize the interaction between accounts. This paper proposes a Random Forest boosted Graph Neural Network for social bot detection, called RF-GNN, which employs graph neural networks (GNNs) as the base classifiers to construct a random forest, effectively combining the advantages of ensemble learning and GNNs to improve the accuracy and robustness of the model. Specifically, different subgraphs are constructed as different training sets through node sampling, feature selection, and edge dropout. Then, GNN base classifiers are trained using various subgraphs, and the remaining features are used for training Fully Connected Netural Network (FCN). The outputs of GNN and FCN are aligned in each branch. Finally, the outputs of all branches are aggregated to produce the final result. Moreover, RF-GNN is compatible with various widely-used GNNs for node classification. Extensive experimental results demonstrate that the proposed method obtains better performance than other state-of-the-art methods.
Over-Sampling Strategy in Feature Space for Graphs based Class-imbalanced Bot Detection
Feb 14, 2023The presence of a large number of bots in Online Social Networks (OSN) leads to undesirable social effects. Graph neural networks (GNNs) have achieved state-of-the-art performance in bot detection since they can effectively utilize user interaction. In most scenarios, the distribution of bots and humans is imbalanced, resulting in under-represent minority class samples and sub-optimal performance. However, previous GNN-based methods for bot detection seldom consider the impact of class-imbalanced issues. In this paper, we propose an over-sampling strategy for GNN (OS-GNN) that can mitigate the effect of class imbalance in bot detection. Compared with previous over-sampling methods for GNNs, OS-GNN does not call for edge synthesis, eliminating the noise inevitably introduced during the edge construction. Specifically, node features are first mapped to a feature space through neighborhood aggregation and then generated samples for the minority class in the feature space. Finally, the augmented features are fed into GNNs to train the classifiers. This framework is general and can be easily extended into different GNN architectures. The proposed framework is evaluated using three real-world bot detection benchmark datasets, and it consistently exhibits superiority over the baselines.
MGTAB: A Multi-Relational Graph-Based Twitter Account Detection Benchmark
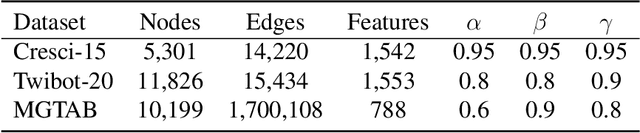
Jan 03, 2023The development of social media user stance detection and bot detection methods rely heavily on large-scale and high-quality benchmarks. However, in addition to low annotation quality, existing benchmarks generally have incomplete user relationships, suppressing graph-based account detection research. To address these issues, we propose a Multi-Relational Graph-Based Twitter Account Detection Benchmark (MGTAB), the first standardized graph-based benchmark for account detection. To our knowledge, MGTAB was built based on the largest original data in the field, with over 1.55 million users and 130 million tweets. MGTAB contains 10,199 expert-annotated users and 7 types of relationships, ensuring high-quality annotation and diversified relations. In MGTAB, we extracted the 20 user property features with the greatest information gain and user tweet features as the user features. In addition, we performed a thorough evaluation of MGTAB and other public datasets. Our experiments found that graph-based approaches are generally more effective than feature-based approaches and perform better when introducing multiple relations. By analyzing experiment results, we identify effective approaches for account detection and provide potential future research directions in this field. Our benchmark and standardized evaluation procedures are freely available at: https://github.com/GraphDetec/MGTAB.
Select and Calibrate the Low-confidence: Dual-Channel Consistency based Graph Convolutional Networks
May 08, 2022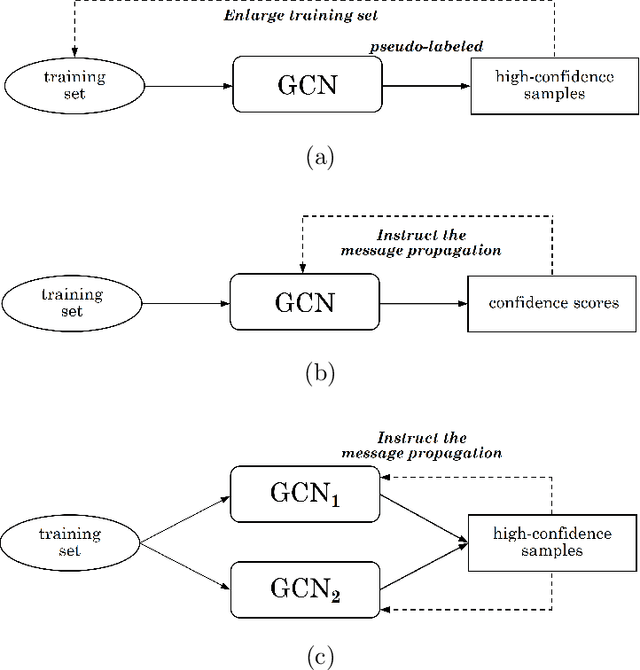
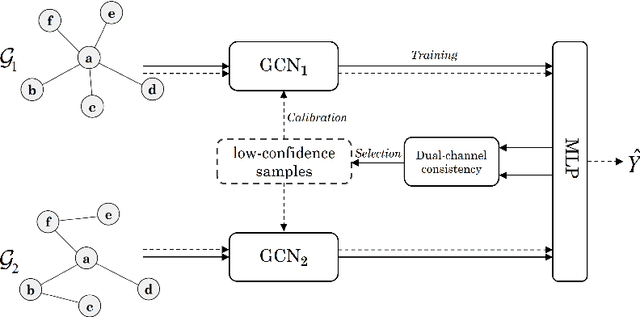
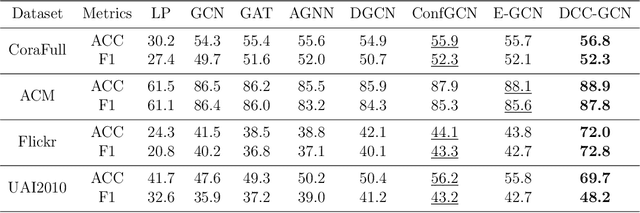
The Graph Convolutional Networks (GCNs) have achieved excellent results in node classification tasks, but the model's performance at low label rates is still unsatisfactory. Previous studies in Semi-Supervised Learning (SSL) for graph have focused on using network predictions to generate soft pseudo-labels or instructing message propagation, which inevitably contains the incorrect prediction due to the over-confident in the predictions. Our proposed Dual-Channel Consistency based Graph Convolutional Networks (DCC-GCN) uses dual-channel to extract embeddings from node features and topological structures, and then achieves reliable low-confidence and high-confidence samples selection based on dual-channel consistency. We further confirmed that the low-confidence samples obtained based on dual-channel consistency were low in accuracy, constraining the model's performance. Unlike previous studies ignoring low-confidence samples, we calibrate the feature embeddings of the low-confidence samples by using the neighborhood's high-confidence samples. Our experiments have shown that the DCC-GCN can more accurately distinguish between low-confidence and high-confidence samples, and can also significantly improve the accuracy of low-confidence samples. We conducted extensive experiments on the benchmark datasets and demonstrated that DCC-GCN is significantly better than state-of-the-art baselines at different label rates.
Adaptive Multi-layer Contrastive Graph Neural Networks
Sep 29, 2021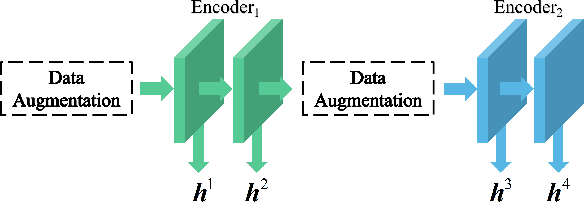
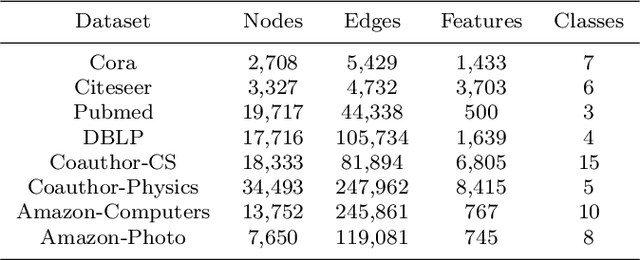


We present Adaptive Multi-layer Contrastive Graph Neural Networks (AMC-GNN), a self-supervised learning framework for Graph Neural Network, which learns feature representations of sample data without data labels. AMC-GNN generates two graph views by data augmentation and compares different layers' output embeddings of Graph Neural Network encoders to obtain feature representations, which could be used for downstream tasks. AMC-GNN could learn the importance weights of embeddings in different layers adaptively through the attention mechanism, and an auxiliary encoder is introduced to train graph contrastive encoders better. The accuracy is improved by maximizing the representation's consistency of positive pairs in the early layers and the final embedding space. Our experiments show that the results can be consistently improved by using the AMC-GNN framework, across four established graph benchmarks: Cora, Citeseer, Pubmed, DBLP citation network datasets, as well as four newly proposed datasets: Co-author-CS, Co-author-Physics, Amazon-Computers, Amazon-Photo.
ShapeEditer: a StyleGAN Encoder for Face Swapping
Jun 26, 2021
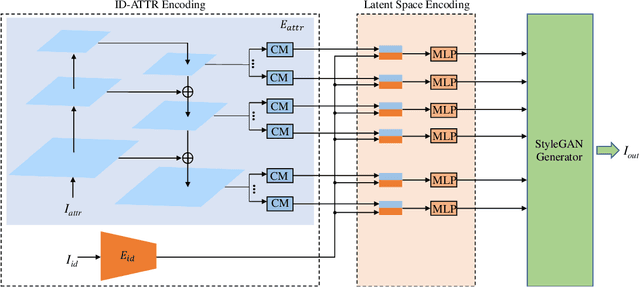

In this paper, we propose a novel encoder, called ShapeEditor, for high-resolution, realistic and high-fidelity face exchange. First of all, in order to ensure sufficient clarity and authenticity, our key idea is to use an advanced pretrained high-quality random face image generator, i.e. StyleGAN, as backbone. Secondly, we design ShapeEditor, a two-step encoder, to make the swapped face integrate the identity and attribute of the input faces. In the first step, we extract the identity vector of the source image and the attribute vector of the target image respectively; in the second step, we map the concatenation of identity vector and attribute vector into the $\mathcal{W+}$ potential space. In addition, for learning to map into the latent space of StyleGAN, we propose a set of self-supervised loss functions with which the training data do not need to be labeled manually. Extensive experiments on the test dataset show that the results of our method not only have a great advantage in clarity and authenticity than other state-of-the-art methods, but also reflect the sufficient integration of identity and attribute.
Improving the Transferability of Adversarial Examples with New Iteration Framework and Input Dropout
Jun 22, 2021

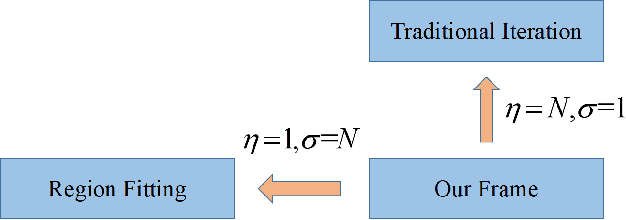
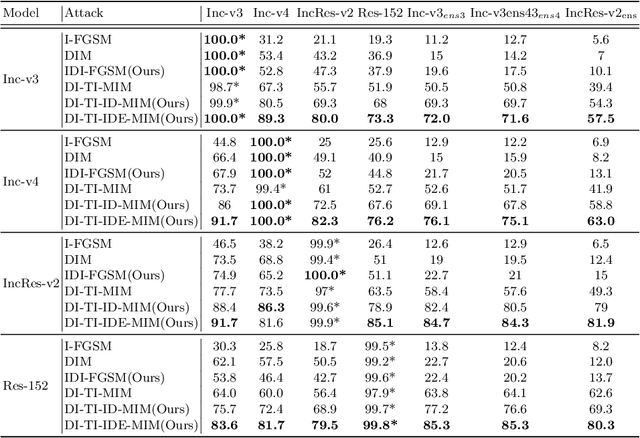
Deep neural networks(DNNs) is vulnerable to be attacked by adversarial examples. Black-box attack is the most threatening attack. At present, black-box attack methods mainly adopt gradient-based iterative attack methods, which usually limit the relationship between the iteration step size, the number of iterations, and the maximum perturbation. In this paper, we propose a new gradient iteration framework, which redefines the relationship between the above three. Under this framework, we easily improve the attack success rate of DI-TI-MIM. In addition, we propose a gradient iterative attack method based on input dropout, which can be well combined with our framework. We further propose a multi dropout rate version of this method. Experimental results show that our best method can achieve attack success rate of 96.2\% for defense model on average, which is higher than the state-of-the-art gradient-based attacks.
AdaGCN:Adaptive Boosting Algorithm for Graph Convolutional Networks on Imbalanced Node Classification
May 25, 2021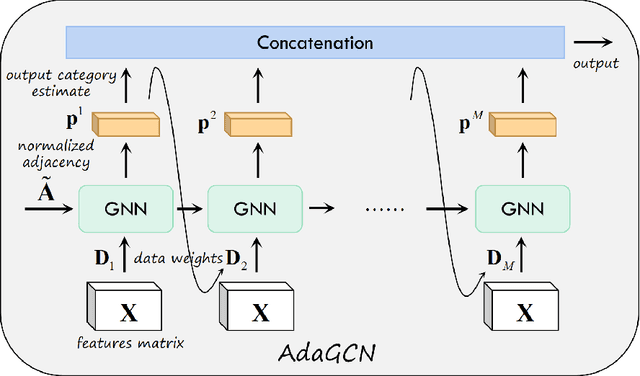
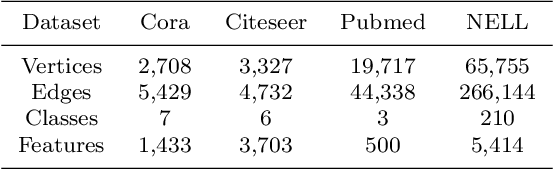
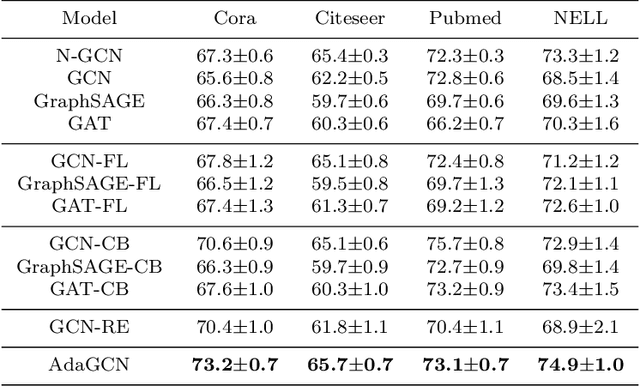
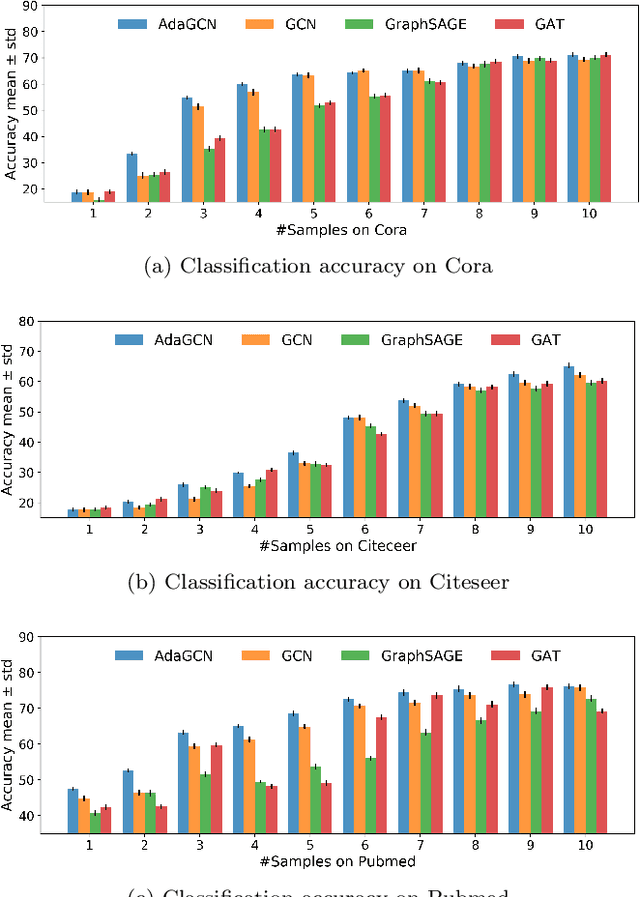
The Graph Neural Network (GNN) has achieved remarkable success in graph data representation. However, the previous work only considered the ideal balanced dataset, and the practical imbalanced dataset was rarely considered, which, on the contrary, is of more significance for the application of GNN. Traditional methods such as resampling, reweighting and synthetic samples that deal with imbalanced datasets are no longer applicable in GNN. Ensemble models can handle imbalanced datasets better compared with single estimator. Besides, ensemble learning can achieve higher estimation accuracy and has better reliability compared with the single estimator. In this paper, we propose an ensemble model called AdaGCN, which uses a Graph Convolutional Network (GCN) as the base estimator during adaptive boosting. In AdaGCN, a higher weight will be set for the training samples that are not properly classified by the previous classifier, and transfer learning is used to reduce computational cost and increase fitting capability. Experiments show that the AdaGCN model we proposed achieves better performance than GCN, GraphSAGE, GAT, N-GCN and the most of advanced reweighting and resampling methods on synthetic imbalanced datasets, with an average improvement of 4.3%. Our model also improves state-of-the-art baselines on all of the challenging node classification tasks we consider: Cora, Citeseer, Pubmed, and NELL.