 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining set cleansing of backdoor poisoning by self-supervised representation learning
Oct 19, 2022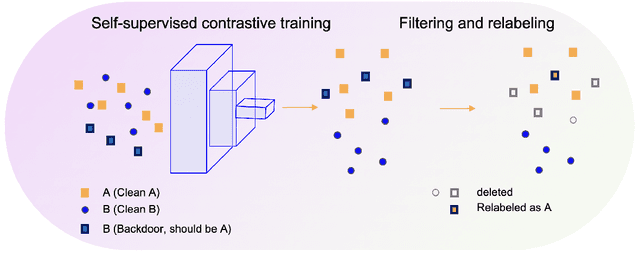
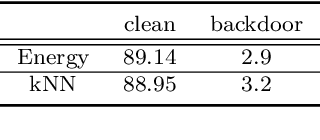
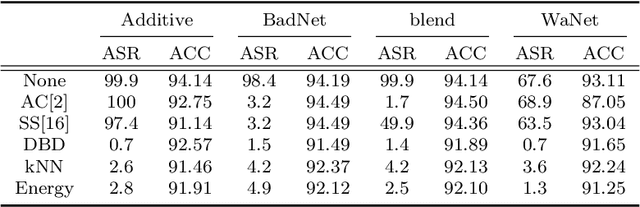
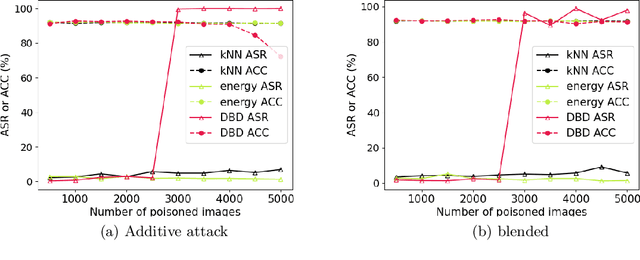
A backdoor or Trojan attack is an important type of data poisoning attack against deep neural network (DNN) classifiers, wherein the training dataset is poisoned with a small number of samples that each possess the backdoor pattern (usually a pattern that is either imperceptible or innocuous) and which are mislabeled to the attacker's target class. When trained on a backdoor-poisoned dataset, a DNN behaves normally on most benign test samples but makes incorrect predictions to the target class when the test sample has the backdoor pattern incorporated (i.e., contains a backdoor trigger). Here we focus on image classification tasks and show that supervised training may build stronger association between the backdoor pattern and the associated target class than that between normal features and the true class of origin. By contrast, self-supervised representation learning ignores the labels of samples and learns a feature embedding based on images' semantic content. %We thus propose to use unsupervised representation learning to avoid emphasising backdoor-poisoned training samples and learn a similar feature embedding for samples of the same class. Using a feature embedding found by self-supervised representation learning, a data cleansing method, which combines sample filtering and re-labeling, is developed. Experiments on CIFAR-10 benchmark datasets show that our method achieves state-of-the-art performance in mitigating backdoor attacks.
A QLP Decomposition via Randomization
Oct 03, 2021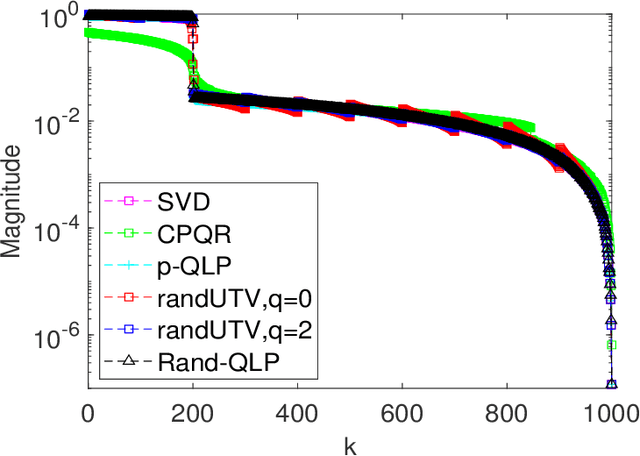
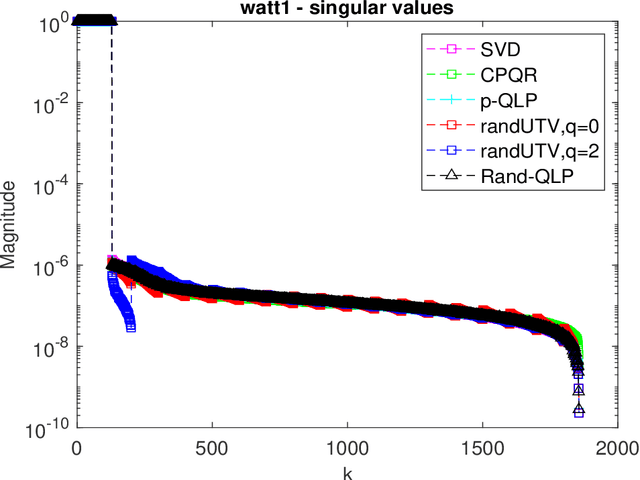
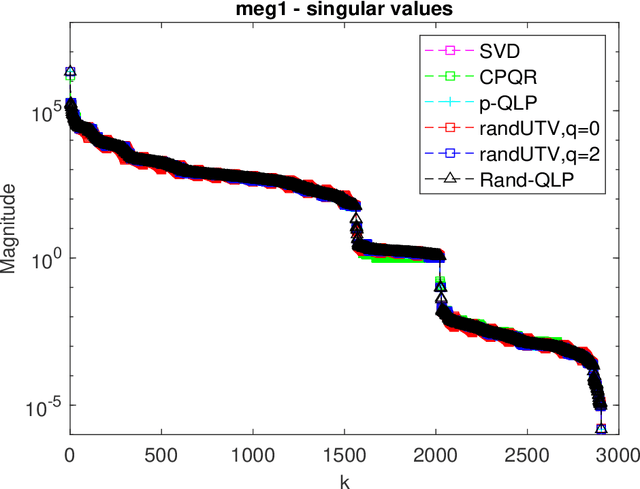
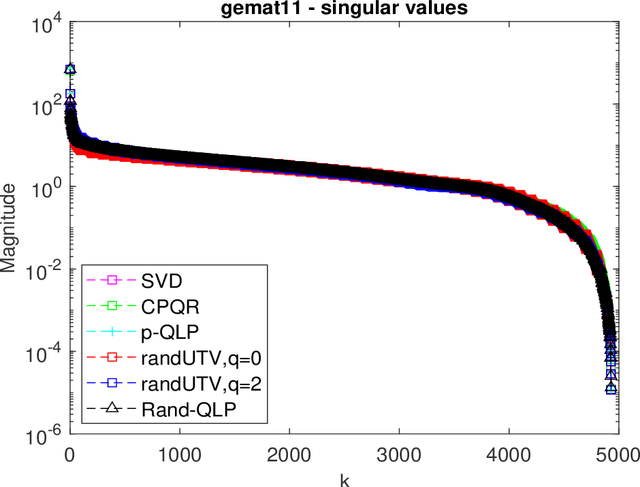
This paper is concerned with full matrix decomposition of matrices, primarily low-rank matrices. It develops a QLP-like decomposition algorithm such that when operating on a matrix A, gives A = QLP^T , where Q and P are orthonormal, and L is lower-triangular. The proposed algorithm, termed Rand-QLP, utilizes randomization and the unpivoted QR decomposition. This in turn enables Rand-QLP to leverage modern computational architectures, thus addressing a serious bottleneck associated with classical and most recent matrix decomposition algorithms. We derive several error bounds for Rand- QLP: bounds for the first k approximate singular values as well as the trailing block of the middle factor, which show that Rand-QLP is rank-revealing; and bounds for the distance between approximate subspaces and the exact ones for all four fundamental subspaces of a given matrix. We assess the speed and approximation quality of Rand-QLP on synthetic and real matrices with different dimensions and characteristics, and compare our results with those of multiple existing algorithms.
Nonlinear Autoregression with Convergent Dynamics on Novel Computational Platforms
Aug 18, 2021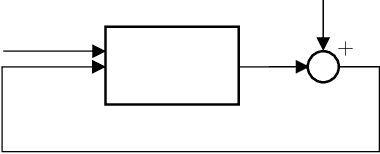

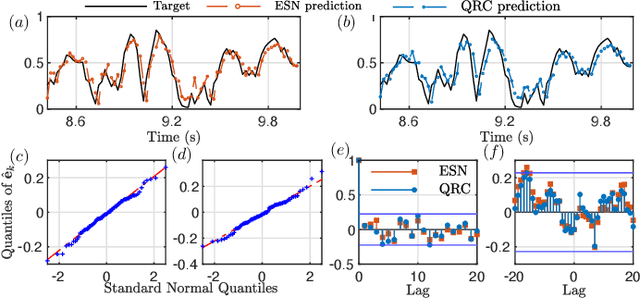
Nonlinear stochastic modeling is useful for describing complex engineering systems. Meanwhile, neuromorphic (brain-inspired) computing paradigms are developing to tackle tasks that are challenging and resource intensive on digital computers. An emerging scheme is reservoir computing which exploits nonlinear dynamical systems for temporal information processing. This paper introduces reservoir computers with output feedback as stationary and ergodic infinite-order nonlinear autoregressive models. We highlight the versatility of this approach by employing classical and quantum reservoir computers to model synthetic and real data sets, further exploring their potential for control applications.
AdaGCN:Adaptive Boosting Algorithm for Graph Convolutional Networks on Imbalanced Node Classification
May 25, 2021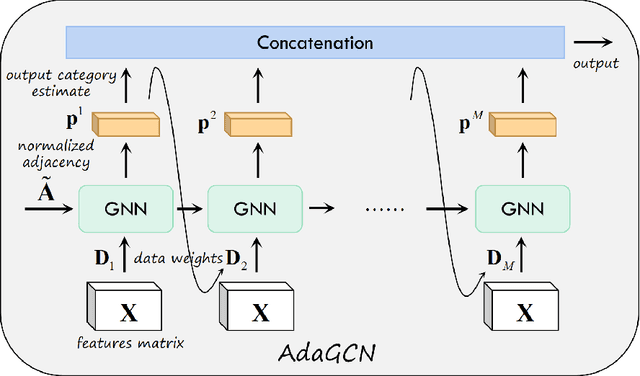
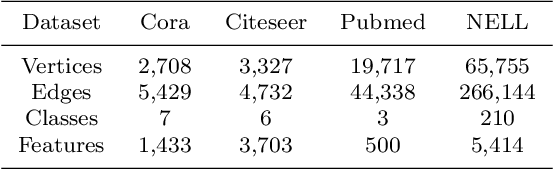
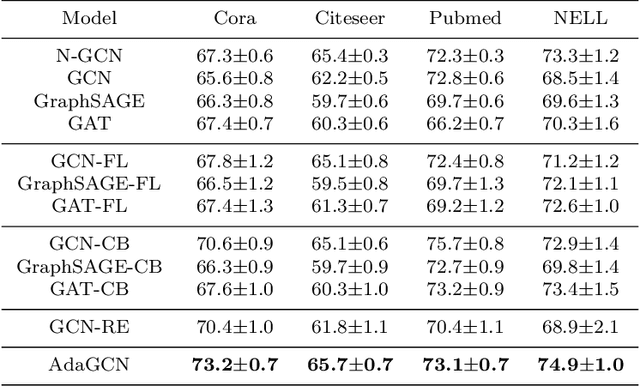
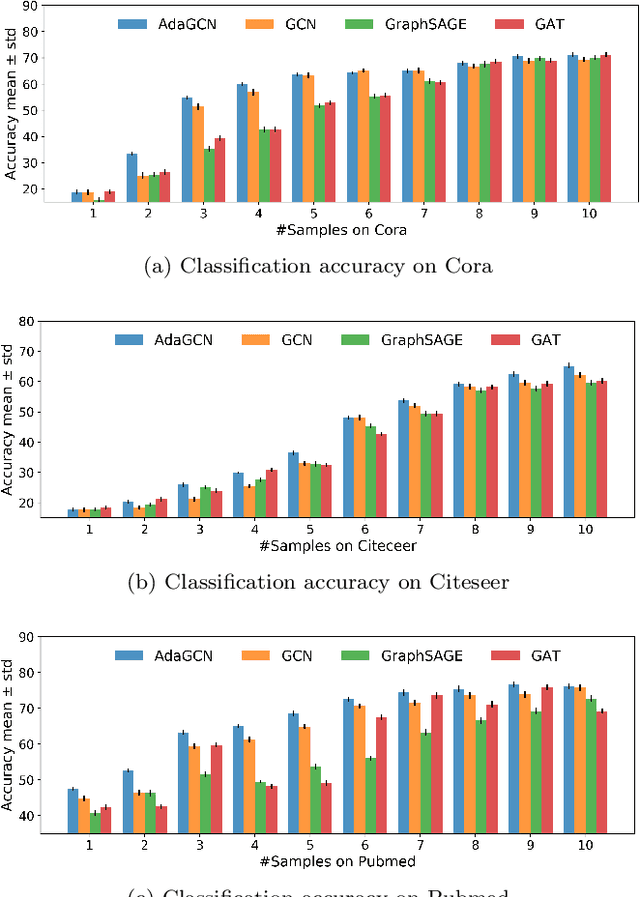
The Graph Neural Network (GNN) has achieved remarkable success in graph data representation. However, the previous work only considered the ideal balanced dataset, and the practical imbalanced dataset was rarely considered, which, on the contrary, is of more significance for the application of GNN. Traditional methods such as resampling, reweighting and synthetic samples that deal with imbalanced datasets are no longer applicable in GNN. Ensemble models can handle imbalanced datasets better compared with single estimator. Besides, ensemble learning can achieve higher estimation accuracy and has better reliability compared with the single estimator. In this paper, we propose an ensemble model called AdaGCN, which uses a Graph Convolutional Network (GCN) as the base estimator during adaptive boosting. In AdaGCN, a higher weight will be set for the training samples that are not properly classified by the previous classifier, and transfer learning is used to reduce computational cost and increase fitting capability. Experiments show that the AdaGCN model we proposed achieves better performance than GCN, GraphSAGE, GAT, N-GCN and the most of advanced reweighting and resampling methods on synthetic imbalanced datasets, with an average improvement of 4.3%. Our model also improves state-of-the-art baselines on all of the challenging node classification tasks we consider: Cora, Citeseer, Pubmed, and NELL.