 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable and Sparse Linear Attention with Decoupled Membership-Subspace Modeling via MCR2 Objective
Jan 20, 2026Maximal Coding Rate Reduction (MCR2)-driven white-box transformer, grounded in structured representation learning, unifies interpretability and efficiency, providing a reliable white-box solution for visual modeling. However, in existing designs, tight coupling between "membership matrix" and "subspace matrix U" in MCR2 causes redundant coding under incorrect token projection. To this end, we decouple the functional relationship between the "membership matrix" and "subspaces U" in the MCR2 objective and derive an interpretable sparse linear attention operator from unrolled gradient descent of the optimized objective. Specifically, we propose to directly learn the membership matrix from inputs and subsequently derive sparse subspaces from the fullspace S. Consequently, gradient unrolling of the optimized MCR2 objective yields an interpretable sparse linear attention operator: Decoupled Membership-Subspace Attention (DMSA). Experimental results on visual tasks show that simply replacing the attention module in Token Statistics Transformer (ToST) with DMSA (we refer to as DMST) not only achieves a faster coding reduction rate but also outperforms ToST by 1.08%-1.45% in top-1 accuracy on the ImageNet-1K dataset. Compared with vanilla Transformer architectures, DMST exhibits significantly higher computational efficiency and interpretability.
A one-step generation model with a Single-Layer Transformer: Layer number re-distillation of FreeFlow
Jan 14, 2026Currently, Flow matching methods aim to compress the iterative generation process of diffusion models into a few or even a single step, with MeanFlow and FreeFlow being representative achievements of one-step generation based on Ordinary Differential Equations (ODEs). We observe that the 28-layer Transformer architecture of FreeFlow can be characterized as an Euler discretization scheme for an ODE along the depth axis, where the layer index serves as the discrete time step. Therefore, we distill the number of layers of the FreeFlow model, following the same derivation logic as FreeFlow, and propose SLT (Single-Layer Transformer), which uses a single shared DiT block to approximate the depth-wise feature evolution of the 28-layer teacher. During training, it matches the teacher's intermediate features at several depth patches, fuses those patch-level representations, and simultaneously aligns the teacher's final velocity prediction. Through distillation training, we compress the 28 independent Transformer Blocks of the teacher model DiT-XL/2 into a single Transformer Block, reducing the parameter count from 675M to 4.3M. Furthermore, leveraging its minimal parameters and rapid sampling speed, SLT can screen more candidate points in the noise space within the same timeframe, thereby selecting higher-quality initial points for the teacher model FreeFlow and ultimately enhancing the quality of generated images. Experimental results demonstrate that within a time budget comparable to two random samplings of the teacher model, our method performs over 100 noise screenings and produces a high-quality sample through the teacher model using the selected points. Quality fluctuations caused by low-quality initial noise under a limited number of FreeFlow sampling calls are effectively avoided, substantially improving the stability and average generation quality of one-step generation.
Multi-Text Guided Few-Shot Semantic Segmentation
Nov 19, 2025Recent CLIP-based few-shot semantic segmentation methods introduce class-level textual priors to assist segmentation by typically using a single prompt (e.g., a photo of class). However, these approaches often result in incomplete activation of target regions, as a single textual description cannot fully capture the semantic diversity of complex categories. Moreover, they lack explicit cross-modal interaction and are vulnerable to noisy support features, further degrading visual prior quality. To address these issues, we propose the Multi-Text Guided Few-Shot Semantic Segmentation Network (MTGNet), a dual-branch framework that enhances segmentation performance by fusing diverse textual prompts to refine textual priors and guide the cross-modal optimization of visual priors. Specifically, we design a Multi-Textual Prior Refinement (MTPR) module that suppresses interference and aggregates complementary semantic cues to enhance foreground activation and expand semantic coverage for structurally complex objects. We introduce a Text Anchor Feature Fusion (TAFF) module, which leverages multi-text embeddings as semantic anchors to facilitate the transfer of discriminative local prototypes from support images to query images, thereby improving semantic consistency and alleviating intra-class variations. Furthermore, a Foreground Confidence-Weighted Attention (FCWA) module is presented to enhance visual prior robustness by leveraging internal self-similarity within support foreground features. It adaptively down-weights inconsistent regions and effectively suppresses interference in the query segmentation process. Extensive experiments on standard FSS benchmarks validate the effectiveness of MTGNet. In the 1-shot setting, it achieves 76.8% mIoU on PASCAL-5i and 57.4% on COCO-20i, with notable improvements in folds exhibiting high intra-class variations.
MFI-ResNet: Efficient ResNet Architecture Optimization via MeanFlow Compression and Selective Incubation
Nov 16, 2025ResNet has achieved tremendous success in computer vision through its residual connection mechanism. ResNet can be viewed as a discretized form of ordinary differential equations (ODEs). From this perspective, the multiple residual blocks within a single ResNet stage essentially perform multi-step discrete iterations of the feature transformation for that stage. The recently proposed flow matching model, MeanFlow, enables one-step generative modeling by learning the mean velocity field to transform distributions. Inspired by this, we propose MeanFlow-Incubated ResNet (MFI-ResNet), which employs a compression-expansion strategy to jointly improve parameter efficiency and discriminative performance. In the compression phase, we simplify the multi-layer structure within each ResNet stage to one or two MeanFlow modules to construct a lightweight meta model. In the expansion phase, we apply a selective incubation strategy to the first three stages, expanding them to match the residual block configuration of the baseline ResNet model, while keeping the last stage in MeanFlow form, and fine-tune the incubated model. Experimental results show that on CIFAR-10 and CIFAR-100 datasets, MFI-ResNet achieves remarkable parameter efficiency, reducing parameters by 46.28% and 45.59% compared to ResNet-50, while still improving accuracy by 0.23% and 0.17%, respectively. This demonstrates that generative flow-fields can effectively characterize the feature transformation process in ResNet, providing a new perspective for understanding the relationship between generative modeling and discriminative learning.
InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation
Nov 06, 2025We introduce InfinityStar, a unified spacetime autoregressive framework for high-resolution image and dynamic video synthesis. Building on the recent success of autoregressive modeling in both vision and language, our purely discrete approach jointly captures spatial and temporal dependencies within a single architecture. This unified design naturally supports a variety of generation tasks such as text-to-image, text-to-video, image-to-video, and long interactive video synthesis via straightforward temporal autoregression. Extensive experiments demonstrate that InfinityStar scores 83.74 on VBench, outperforming all autoregressive models by large margins, even surpassing some diffusion competitors like HunyuanVideo. Without extra optimizations, our model generates a 5s, 720p video approximately 10x faster than leading diffusion-based methods. To our knowledge, InfinityStar is the first discrete autoregressive video generator capable of producing industrial level 720p videos. We release all code and models to foster further research in efficient, high-quality video generation.
Bridging Generative and Discriminative Learning: Few-Shot Relation Extraction via Two-Stage Knowledge-Guided Pre-training
May 18, 2025Few-Shot Relation Extraction (FSRE) remains a challenging task due to the scarcity of annotated data and the limited generalization capabilities of existing models. Although large language models (LLMs) have demonstrated potential in FSRE through in-context learning (ICL), their general-purpose training objectives often result in suboptimal performance for task-specific relation extraction. To overcome these challenges, we propose TKRE (Two-Stage Knowledge-Guided Pre-training for Relation Extraction), a novel framework that synergistically integrates LLMs with traditional relation extraction models, bridging generative and discriminative learning paradigms. TKRE introduces two key innovations: (1) leveraging LLMs to generate explanation-driven knowledge and schema-constrained synthetic data, addressing the issue of data scarcity; and (2) a two-stage pre-training strategy combining Masked Span Language Modeling (MSLM) and Span-Level Contrastive Learning (SCL) to enhance relational reasoning and generalization. Together, these components enable TKRE to effectively tackle FSRE tasks. Comprehensive experiments on benchmark datasets demonstrate the efficacy of TKRE, achieving new state-of-the-art performance in FSRE and underscoring its potential for broader application in low-resource scenarios. \footnote{The code and data are released on https://github.com/UESTC-GQJ/TKRE.
SD-ReID: View-aware Stable Diffusion for Aerial-Ground Person Re-Identification
Apr 13, 2025Aerial-Ground Person Re-IDentification (AG-ReID) aims to retrieve specific persons across cameras with different viewpoints. Previous works focus on designing discriminative ReID models to maintain identity consistency despite drastic changes in camera viewpoints. The core idea behind these methods is quite natural, but designing a view-robust network is a very challenging task. Moreover, they overlook the contribution of view-specific features in enhancing the model's capability to represent persons. To address these issues, we propose a novel two-stage feature learning framework named SD-ReID for AG-ReID, which takes advantage of the powerful understanding capacity of generative models, e.g., Stable Diffusion (SD), to generate view-specific features between different viewpoints. In the first stage, we train a simple ViT-based model to extract coarse-grained representations and controllable conditions. Then, in the second stage, we fine-tune the SD model to learn complementary representations guided by the controllable conditions. Furthermore, we propose the View-Refine Decoder (VRD) to obtain additional controllable conditions to generate missing cross-view features. Finally, we use the coarse-grained representations and all-view features generated by SD to retrieve target persons. Extensive experiments on the AG-ReID benchmarks demonstrate the effectiveness of our proposed SD-ReID. The source code will be available upon acceptance.
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
Dec 05, 2024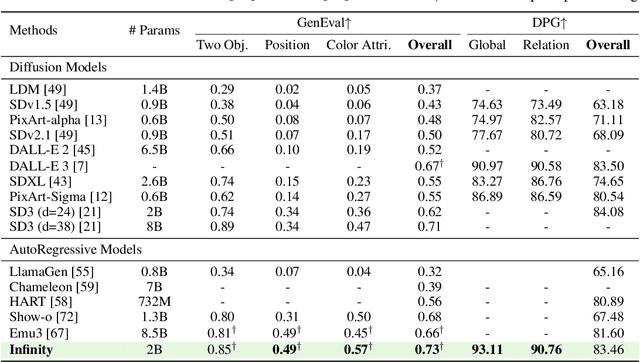

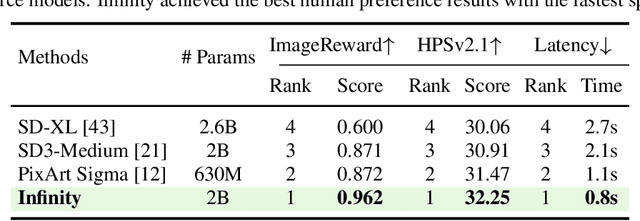

We present Infinity, a Bitwise Visual AutoRegressive Modeling capable of generating high-resolution, photorealistic images following language instruction. Infinity redefines visual autoregressive model under a bitwise token prediction framework with an infinite-vocabulary tokenizer & classifier and bitwise self-correction mechanism, remarkably improving the generation capacity and details. By theoretically scaling the tokenizer vocabulary size to infinity and concurrently scaling the transformer size, our method significantly unleashes powerful scaling capabilities compared to vanilla VAR. Infinity sets a new record for autoregressive text-to-image models, outperforming top-tier diffusion models like SD3-Medium and SDXL. Notably, Infinity surpasses SD3-Medium by improving the GenEval benchmark score from 0.62 to 0.73 and the ImageReward benchmark score from 0.87 to 0.96, achieving a win rate of 66%. Without extra optimization, Infinity generates a high-quality 1024x1024 image in 0.8 seconds, making it 2.6x faster than SD3-Medium and establishing it as the fastest text-to-image model. Models and codes will be released to promote further exploration of Infinity for visual generation and unified tokenizer modeling.
Towards Real-Time Open-Vocabulary Video Instance Segmentation
Dec 05, 2024In this paper, we address the challenge of performing open-vocabulary video instance segmentation (OV-VIS) in real-time. We analyze the computational bottlenecks of state-of-the-art foundation models that performs OV-VIS, and propose a new method, TROY-VIS, that significantly improves processing speed while maintaining high accuracy. We introduce three key techniques: (1) Decoupled Attention Feature Enhancer to speed up information interaction between different modalities and scales; (2) Flash Embedding Memory for obtaining fast text embeddings of object categories; and, (3) Kernel Interpolation for exploiting the temporal continuity in videos. Our experiments demonstrate that TROY-VIS achieves the best trade-off between accuracy and speed on two large-scale OV-VIS benchmarks, BURST and LV-VIS, running 20x faster than GLEE-Lite (25 FPS v.s. 1.25 FPS) with comparable or even better accuracy. These results demonstrate TROY-VIS's potential for real-time applications in dynamic environments such as mobile robotics and augmented reality. Code and model will be released at https://github.com/google-research/troyvis.
Signal Adversarial Examples Generation for Signal Detection Network via White-Box Attack
Oct 02, 2024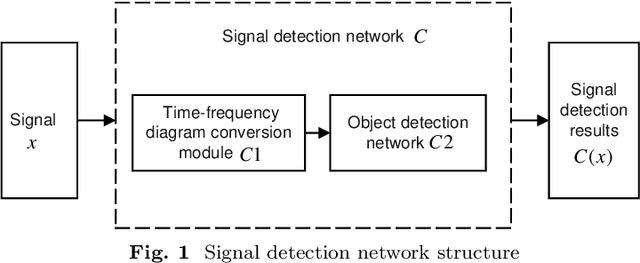



With the development and application of deep learning in signal detection tasks, the vulnerability of neural networks to adversarial attacks has also become a security threat to signal detection networks. This paper defines a signal adversarial examples generation model for signal detection network from the perspective of adding perturbations to the signal. The model uses the inequality relationship of L2-norm between time domain and time-frequency domain to constrain the energy of signal perturbations. Building upon this model, we propose a method for generating signal adversarial examples utilizing gradient-based attacks and Short-Time Fourier Transform. The experimental results show that under the constraint of signal perturbation energy ratio less than 3%, our adversarial attack resulted in a 28.1% reduction in the mean Average Precision (mAP), a 24.7% reduction in recall, and a 30.4% reduction in precision of the signal detection network. Compared to random noise perturbation of equivalent intensity, our adversarial attack demonstrates a significant attack effect.