 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025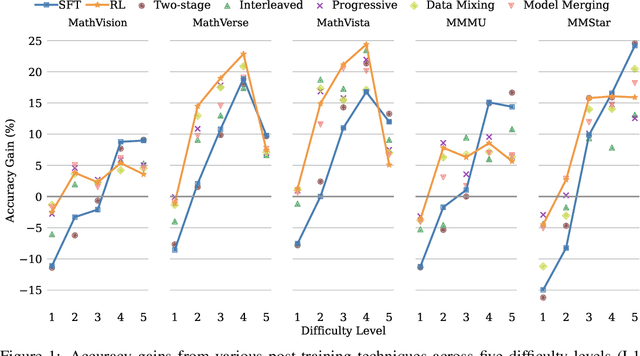
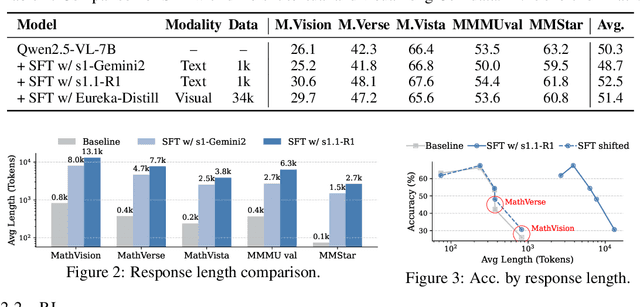
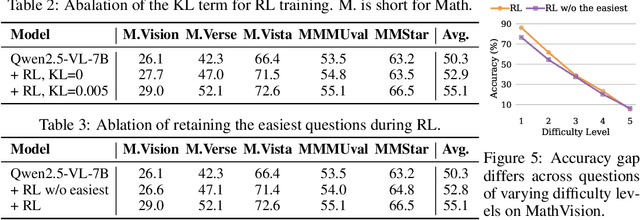
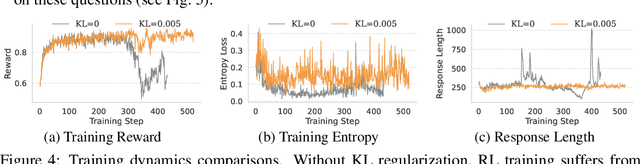
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
VisionLLM v2: An End-to-End Generalist Multimodal Large Language Model for Hundreds of Vision-Language Tasks
Jun 12, 2024We present VisionLLM v2, an end-to-end generalist multimodal large model (MLLM) that unifies visual perception, understanding, and generation within a single framework. Unlike traditional MLLMs limited to text output, VisionLLM v2 significantly broadens its application scope. It excels not only in conventional visual question answering (VQA) but also in open-ended, cross-domain vision tasks such as object localization, pose estimation, and image generation and editing. To this end, we propose a new information transmission mechanism termed "super link", as a medium to connect MLLM with task-specific decoders. It not only allows flexible transmission of task information and gradient feedback between the MLLM and multiple downstream decoders but also effectively resolves training conflicts in multi-tasking scenarios. In addition, to support the diverse range of tasks, we carefully collected and combed training data from hundreds of public vision and vision-language tasks. In this way, our model can be joint-trained end-to-end on hundreds of vision language tasks and generalize to these tasks using a set of shared parameters through different user prompts, achieving performance comparable to task-specific models. We believe VisionLLM v2 will offer a new perspective on the generalization of MLLMs.
Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models
Apr 19, 2024We introduce Groma, a Multimodal Large Language Model (MLLM) with grounded and fine-grained visual perception ability. Beyond holistic image understanding, Groma is adept at region-level tasks such as region captioning and visual grounding. Such capabilities are built upon a localized visual tokenization mechanism, where an image input is decomposed into regions of interest and subsequently encoded into region tokens. By integrating region tokens into user instructions and model responses, we seamlessly enable Groma to understand user-specified region inputs and ground its textual output to images. Besides, to enhance the grounded chat ability of Groma, we curate a visually grounded instruction dataset by leveraging the powerful GPT-4V and visual prompting techniques. Compared with MLLMs that rely on the language model or external module for localization, Groma consistently demonstrates superior performances in standard referring and grounding benchmarks, highlighting the advantages of embedding localization into image tokenization. Project page: https://groma-mllm.github.io/.
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Jan 15, 2024The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces
Dec 25, 2023The reference-based object segmentation tasks, namely referring image segmentation (RIS), few-shot image segmentation (FSS), referring video object segmentation (RVOS), and video object segmentation (VOS), aim to segment a specific object by utilizing either language or annotated masks as references. Despite significant progress in each respective field, current methods are task-specifically designed and developed in different directions, which hinders the activation of multi-task capabilities for these tasks. In this work, we end the current fragmented situation and propose UniRef++ to unify the four reference-based object segmentation tasks with a single architecture. At the heart of our approach is the proposed UniFusion module which performs multiway-fusion for handling different tasks with respect to their specified references. And a unified Transformer architecture is then adopted for achieving instance-level segmentation. With the unified designs, UniRef++ can be jointly trained on a broad range of benchmarks and can flexibly complete multiple tasks at run-time by specifying the corresponding references. We evaluate our unified models on various benchmarks. Extensive experimental results indicate that our proposed UniRef++ achieves state-of-the-art performance on RIS and RVOS, and performs competitively on FSS and VOS with a parameter-shared network. Moreover, we showcase that the proposed UniFusion module could be easily incorporated into the current advanced foundation model SAM and obtain satisfactory results with parameter-efficient finetuning. Codes and models are available at \url{https://github.com/FoundationVision/UniRef}.
Exploring Transformers for Open-world Instance Segmentation
Aug 08, 2023



Open-world instance segmentation is a rising task, which aims to segment all objects in the image by learning from a limited number of base-category objects. This task is challenging, as the number of unseen categories could be hundreds of times larger than that of seen categories. Recently, the DETR-like models have been extensively studied in the closed world while stay unexplored in the open world. In this paper, we utilize the Transformer for open-world instance segmentation and present SWORD. Firstly, we introduce to attach the stop-gradient operation before classification head and further add IoU heads for discovering novel objects. We demonstrate that a simple stop-gradient operation not only prevents the novel objects from being suppressed as background, but also allows the network to enjoy the merit of heuristic label assignment. Secondly, we propose a novel contrastive learning framework to enlarge the representations between objects and background. Specifically, we maintain a universal object queue to obtain the object center, and dynamically select positive and negative samples from the object queries for contrastive learning. While the previous works only focus on pursuing average recall and neglect average precision, we show the prominence of SWORD by giving consideration to both criteria. Our models achieve state-of-the-art performance in various open-world cross-category and cross-dataset generalizations. Particularly, in VOC to non-VOC setup, our method sets new state-of-the-art results of 40.0% on ARb100 and 34.9% on ARm100. For COCO to UVO generalization, SWORD significantly outperforms the previous best open-world model by 5.9% on APm and 8.1% on ARm100.
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
May 25, 2023



Large language models (LLMs) have notably accelerated progress towards artificial general intelligence (AGI), with their impressive zero-shot capacity for user-tailored tasks, endowing them with immense potential across a range of applications. However, in the field of computer vision, despite the availability of numerous powerful vision foundation models (VFMs), they are still restricted to tasks in a pre-defined form, struggling to match the open-ended task capabilities of LLMs. In this work, we present an LLM-based framework for vision-centric tasks, termed VisionLLM. This framework provides a unified perspective for vision and language tasks by treating images as a foreign language and aligning vision-centric tasks with language tasks that can be flexibly defined and managed using language instructions. An LLM-based decoder can then make appropriate predictions based on these instructions for open-ended tasks. Extensive experiments show that the proposed VisionLLM can achieve different levels of task customization through language instructions, from fine-grained object-level to coarse-grained task-level customization, all with good results. It's noteworthy that, with a generalist LLM-based framework, our model can achieve over 60\% mAP on COCO, on par with detection-specific models. We hope this model can set a new baseline for generalist vision and language models. The demo shall be released based on https://github.com/OpenGVLab/InternGPT. The code shall be released at https://github.com/OpenGVLab/VisionLLM.
Multi-Level Contrastive Learning for Dense Prediction Task
Apr 04, 2023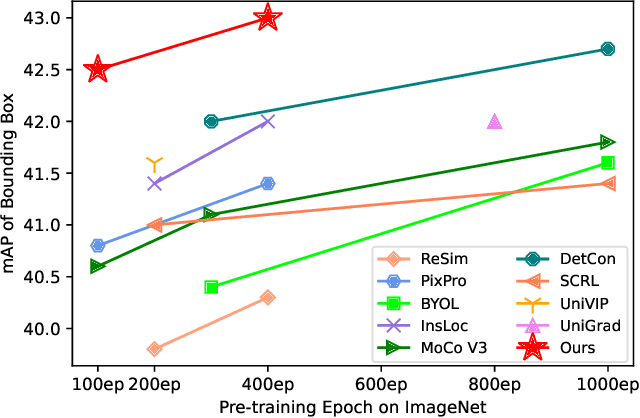
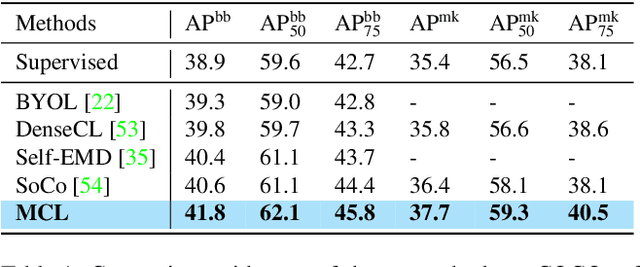
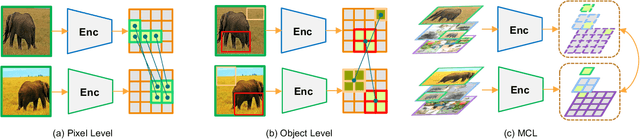
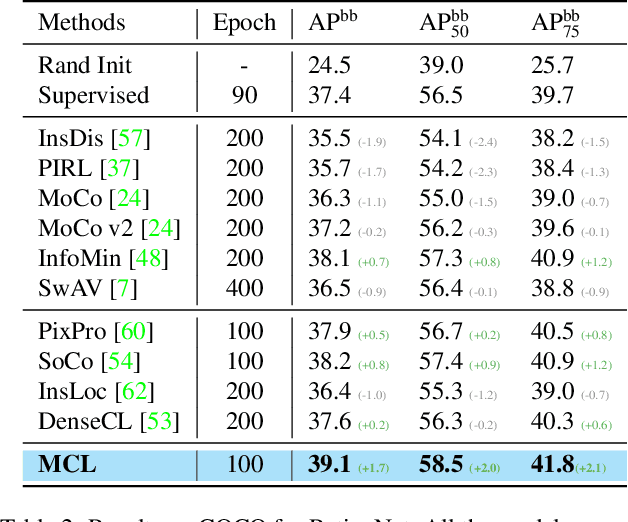
In this work, we present Multi-Level Contrastive Learning for Dense Prediction Task (MCL), an efficient self-supervised method for learning region-level feature representation for dense prediction tasks. Our method is motivated by the three key factors in detection: localization, scale consistency and recognition. To explicitly encode absolute position and scale information, we propose a novel pretext task that assembles multi-scale images in a montage manner to mimic multi-object scenarios. Unlike the existing image-level self-supervised methods, our method constructs a multi-level contrastive loss that considers each sub-region of the montage image as a singleton. Our method enables the neural network to learn regional semantic representations for translation and scale consistency while reducing pre-training epochs to the same as supervised pre-training. Extensive experiments demonstrate that MCL consistently outperforms the recent state-of-the-art methods on various datasets with significant margins. In particular, MCL obtains 42.5 AP$^\mathrm{bb}$ and 38.3 AP$^\mathrm{mk}$ on COCO with the 1x schedule fintuning, when using Mask R-CNN with R50-FPN backbone pre-trained with 100 epochs. In comparison to MoCo, our method surpasses their performance by 4.0 AP$^\mathrm{bb}$ and 3.1 AP$^\mathrm{mk}$. Furthermore, we explore the alignment between pretext task and downstream tasks. We extend our pretext task to supervised pre-training, which achieves a similar performance to self-supervised learning. This result demonstrates the importance of the alignment between pretext task and downstream tasks, indicating the potential for wider applicability of our method beyond self-supervised settings.
Universal Instance Perception as Object Discovery and Retrieval
Mar 12, 2023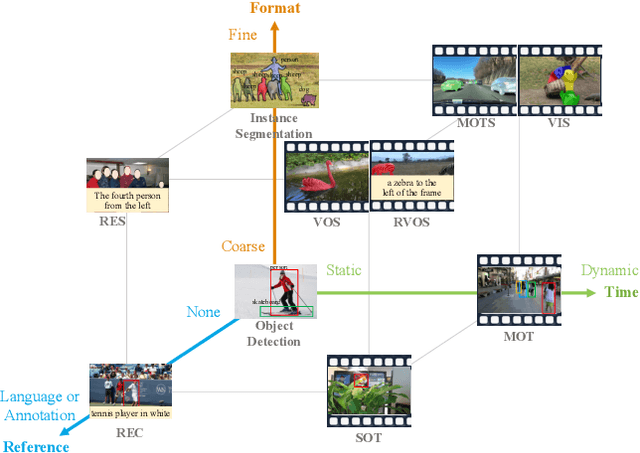



All instance perception tasks aim at finding certain objects specified by some queries such as category names, language expressions, and target annotations, but this complete field has been split into multiple independent subtasks. In this work, we present a universal instance perception model of the next generation, termed UNINEXT. UNINEXT reformulates diverse instance perception tasks into a unified object discovery and retrieval paradigm and can flexibly perceive different types of objects by simply changing the input prompts. This unified formulation brings the following benefits: (1) enormous data from different tasks and label vocabularies can be exploited for jointly training general instance-level representations, which is especially beneficial for tasks lacking in training data. (2) the unified model is parameter-efficient and can save redundant computation when handling multiple tasks simultaneously. UNINEXT shows superior performance on 20 challenging benchmarks from 10 instance-level tasks including classical image-level tasks (object detection and instance segmentation), vision-and-language tasks (referring expression comprehension and segmentation), and six video-level object tracking tasks. Code is available at https://github.com/MasterBin-IIAU/UNINEXT.