 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Video Representation Learning with Motion-Aware Masked Autoencoders
Oct 09, 2022
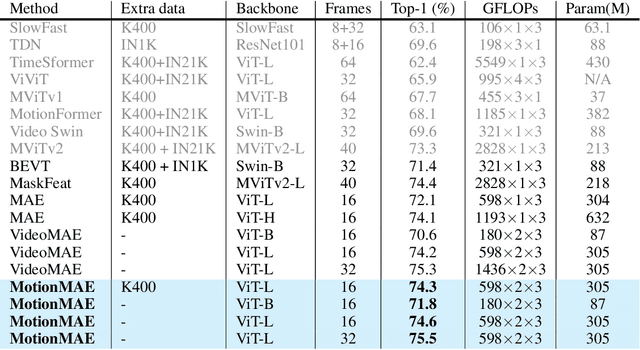

Masked autoencoders (MAEs) have emerged recently as art self-supervised spatiotemporal representation learners. Inheriting from the image counterparts, however, existing video MAEs still focus largely on static appearance learning whilst are limited in learning dynamic temporal information hence less effective for video downstream tasks. To resolve this drawback, in this work we present a motion-aware variant -- MotionMAE. Apart from learning to reconstruct individual masked patches of video frames, our model is designed to additionally predict the corresponding motion structure information over time. This motion information is available at the temporal difference of nearby frames. As a result, our model can extract effectively both static appearance and dynamic motion spontaneously, leading to superior spatiotemporal representation learning capability. Extensive experiments show that our MotionMAE outperforms significantly both supervised learning baseline and state-of-the-art MAE alternatives, under both domain-specific and domain-generic pretraining-then-finetuning settings. In particular, when using ViT-B as the backbone our MotionMAE surpasses the prior art model by a margin of 1.2% on Something-Something V2 and 3.2% on UCF101 in domain-specific pretraining setting. Encouragingly, it also surpasses the competing MAEs by a large margin of over 3% on the challenging video object segmentation task. The code is available at https://github.com/happy-hsy/MotionMAE.
ASCNet: Self-supervised Video Representation Learning with Appearance-Speed Consistency
Jun 04, 2021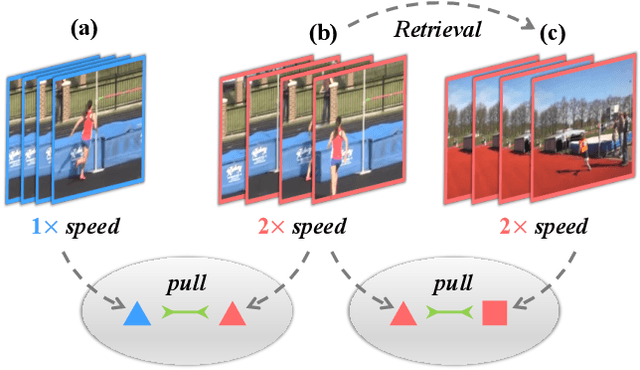

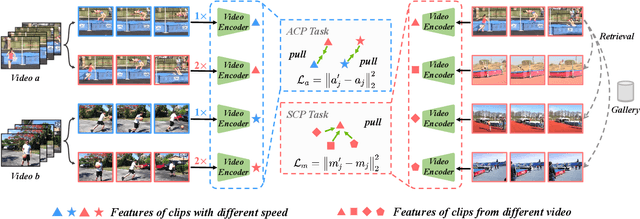

We study self-supervised video representation learning, which is a challenging task due to 1) a lack of labels for explicit supervision and 2) unstructured and noisy visual information. Existing methods mainly use contrastive loss with video clips as the instances and learn visual representation by discriminating instances from each other, but they require careful treatment of negative pairs by relying on large batch sizes, memory banks, extra modalities, or customized mining strategies, inevitably including noisy data. In this paper, we observe that the consistency between positive samples is the key to learn robust video representations. Specifically, we propose two tasks to learn the appearance and speed consistency, separately. The appearance consistency task aims to maximize the similarity between two clips of the same video with different playback speeds. The speed consistency task aims to maximize the similarity between two clips with the same playback speed but different appearance information. We show that joint optimization of the two tasks consistently improves the performance on downstream tasks, e.g., action recognition and video retrieval. Remarkably, for action recognition on the UCF-101 dataset, we achieve 90.8% accuracy without using any additional modalities or negative pairs for unsupervised pretraining, outperforming the ImageNet supervised pre-trained model. Codes and models will be available.
Location-aware Graph Convolutional Networks for Video Question Answering
Aug 07, 2020

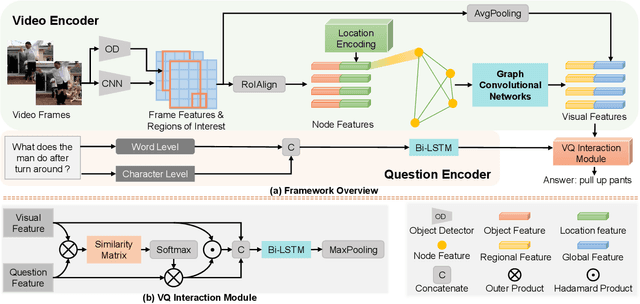
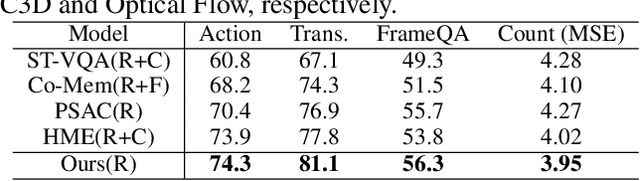
We addressed the challenging task of video question answering, which requires machines to answer questions about videos in a natural language form. Previous state-of-the-art methods attempt to apply spatio-temporal attention mechanism on video frame features without explicitly modeling the location and relations among object interaction occurred in videos. However, the relations between object interaction and their location information are very critical for both action recognition and question reasoning. In this work, we propose to represent the contents in the video as a location-aware graph by incorporating the location information of an object into the graph construction. Here, each node is associated with an object represented by its appearance and location features. Based on the constructed graph, we propose to use graph convolution to infer both the category and temporal locations of an action. As the graph is built on objects, our method is able to focus on the foreground action contents for better video question answering. Lastly, we leverage an attention mechanism to combine the output of graph convolution and encoded question features for final answer reasoning. Extensive experiments demonstrate the effectiveness of the proposed methods. Specifically, our method significantly outperforms state-of-the-art methods on TGIF-QA, Youtube2Text-QA, and MSVD-QA datasets. Code and pre-trained models are publicly available at: https://github.com/SunDoge/L-GCN
Foley Music: Learning to Generate Music from Videos
Jul 21, 2020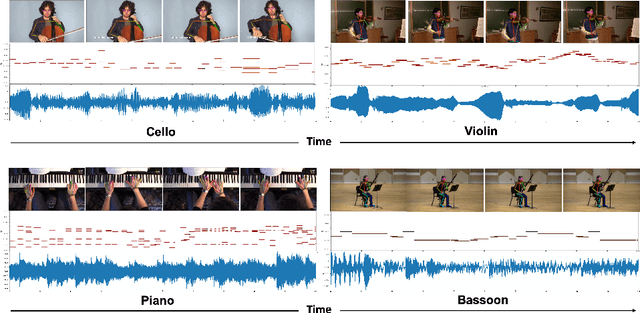
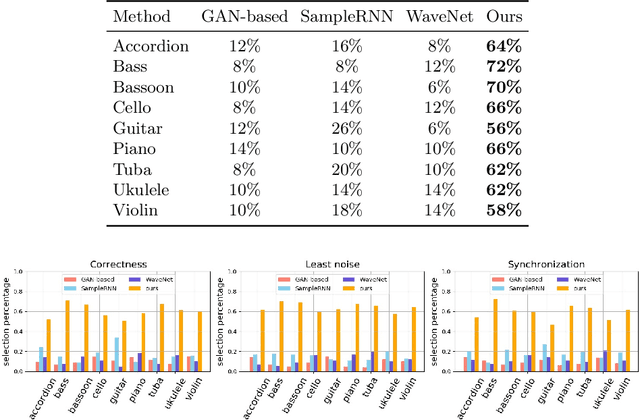
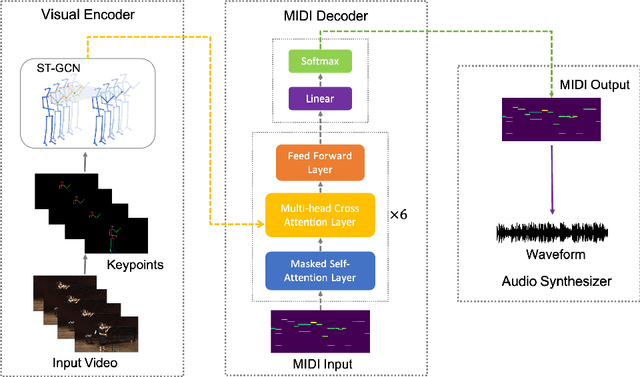

In this paper, we introduce Foley Music, a system that can synthesize plausible music for a silent video clip about people playing musical instruments. We first identify two key intermediate representations for a successful video to music generator: body keypoints from videos and MIDI events from audio recordings. We then formulate music generation from videos as a motion-to-MIDI translation problem. We present a Graph$-$Transformer framework that can accurately predict MIDI event sequences in accordance with the body movements. The MIDI event can then be converted to realistic music using an off-the-shelf music synthesizer tool. We demonstrate the effectiveness of our models on videos containing a variety of music performances. Experimental results show that our model outperforms several existing systems in generating music that is pleasant to listen to. More importantly, the MIDI representations are fully interpretable and transparent, thus enabling us to perform music editing flexibly. We encourage the readers to watch the demo video with audio turned on to experience the results.
Generating Visually Aligned Sound from Videos
Jul 14, 2020
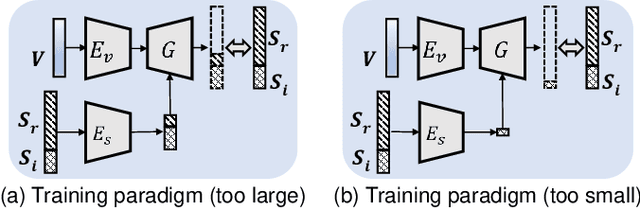

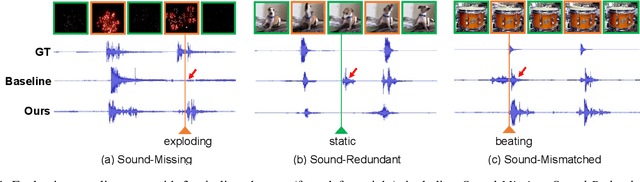
We focus on the task of generating sound from natural videos, and the sound should be both temporally and content-wise aligned with visual signals. This task is extremely challenging because some sounds generated \emph{outside} a camera can not be inferred from video content. The model may be forced to learn an incorrect mapping between visual content and these irrelevant sounds. To address this challenge, we propose a framework named REGNET. In this framework, we first extract appearance and motion features from video frames to better distinguish the object that emits sound from complex background information. We then introduce an innovative audio forwarding regularizer that directly considers the real sound as input and outputs bottlenecked sound features. Using both visual and bottlenecked sound features for sound prediction during training provides stronger supervision for the sound prediction. The audio forwarding regularizer can control the irrelevant sound component and thus prevent the model from learning an incorrect mapping between video frames and sound emitted by the object that is out of the screen. During testing, the audio forwarding regularizer is removed to ensure that REGNET can produce purely aligned sound only from visual features. Extensive evaluations based on Amazon Mechanical Turk demonstrate that our method significantly improves both temporal and content-wise alignment. Remarkably, our generated sound can fool the human with a 68.12% success rate. Code and pre-trained models are publicly available at https://github.com/PeihaoChen/regnet
Music Gesture for Visual Sound Separation
Apr 20, 2020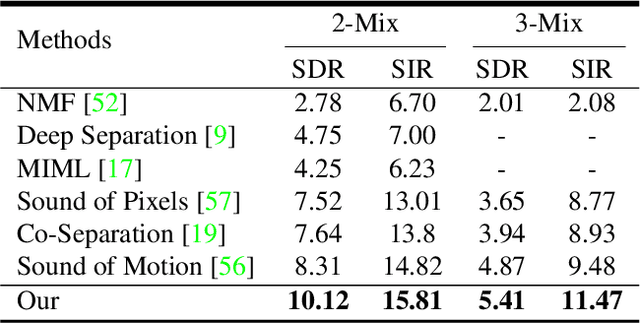
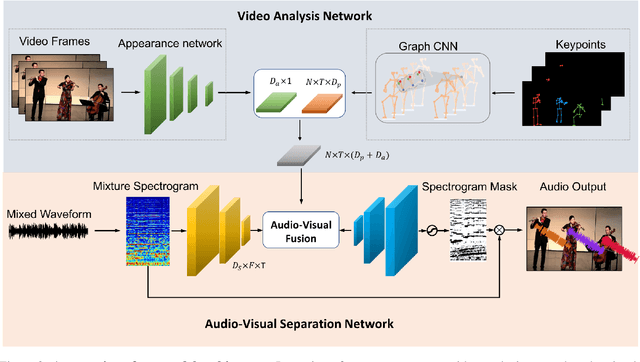

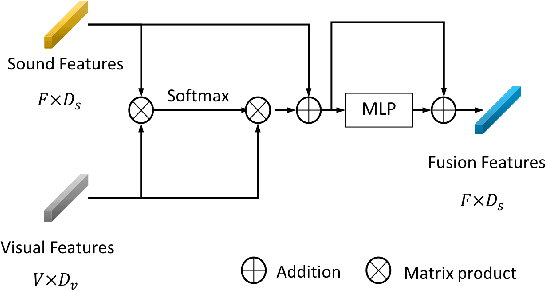
Recent deep learning approaches have achieved impressive performance on visual sound separation tasks. However, these approaches are mostly built on appearance and optical flow like motion feature representations, which exhibit limited abilities to find the correlations between audio signals and visual points, especially when separating multiple instruments of the same types, such as multiple violins in a scene. To address this, we propose "Music Gesture," a keypoint-based structured representation to explicitly model the body and finger movements of musicians when they perform music. We first adopt a context-aware graph network to integrate visual semantic context with body dynamics, and then apply an audio-visual fusion model to associate body movements with the corresponding audio signals. Experimental results on three music performance datasets show: 1) strong improvements upon benchmark metrics for hetero-musical separation tasks (i.e. different instruments); 2) new ability for effective homo-musical separation for piano, flute, and trumpet duets, which to our best knowledge has never been achieved with alternative methods. Project page: http://music-gesture.csail.mit.edu.