 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Compressing Prompts for Efficient Inference of Large Language Models
Apr 15, 2025Large Language Models (LLMs) have shown outstanding performance across a variety of tasks, partly due to advanced prompting techniques. However, these techniques often require lengthy prompts, which increase computational costs and can hinder performance because of the limited context windows of LLMs. While prompt compression is a straightforward solution, existing methods confront the challenges of retaining essential information, adapting to context changes, and remaining effective across different tasks. To tackle these issues, we propose a task-agnostic method called Dynamic Compressing Prompts (LLM-DCP). Our method reduces the number of prompt tokens while aiming to preserve the performance as much as possible. We model prompt compression as a Markov Decision Process (MDP), enabling the DCP-Agent to sequentially remove redundant tokens by adapting to dynamic contexts and retaining crucial content. We develop a reward function for training the DCP-Agent that balances the compression rate, the quality of the LLM output, and the retention of key information. This allows for prompt token reduction without needing an external black-box LLM. Inspired by the progressive difficulty adjustment in curriculum learning, we introduce a Hierarchical Prompt Compression (HPC) training strategy that gradually increases the compression difficulty, enabling the DCP-Agent to learn an effective compression method that maintains information integrity. Experiments demonstrate that our method outperforms state-of-the-art techniques, especially at higher compression rates. The code for our approach will be available at https://github.com/Fhujinwu/DCP.
Rethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
Dec 17, 2024Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
MAGIC: Map-Guided Few-Shot Audio-Visual Acoustics Modeling
May 22, 2024Few-shot audio-visual acoustics modeling seeks to synthesize the room impulse response in arbitrary locations with few-shot observations. To sufficiently exploit the provided few-shot data for accurate acoustic modeling, we present a *map-guided* framework by constructing acoustic-related visual semantic feature maps of the scenes. Visual features preserve semantic details related to sound and maps provide explicit structural regularities of sound propagation, which are valuable for modeling environment acoustics. We thus extract pixel-wise semantic features derived from observations and project them into a top-down map, namely the **observation semantic map**. This map contains the relative positional information among points and the semantic feature information associated with each point. Yet, limited information extracted by few-shot observations on the map is not sufficient for understanding and modeling the whole scene. We address the challenge by generating a **scene semantic map** via diffusing features and anticipating the observation semantic map. The scene semantic map then interacts with echo encoding by a transformer-based encoder-decoder to predict RIR for arbitrary speaker-listener query pairs. Extensive experiments on Matterport3D and Replica dataset verify the efficacy of our framework.
AlphaFin: Benchmarking Financial Analysis with Retrieval-Augmented Stock-Chain Framework
Mar 19, 2024
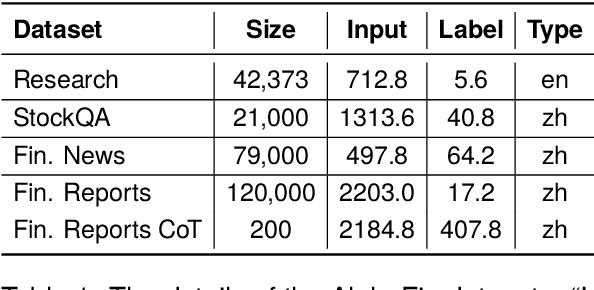
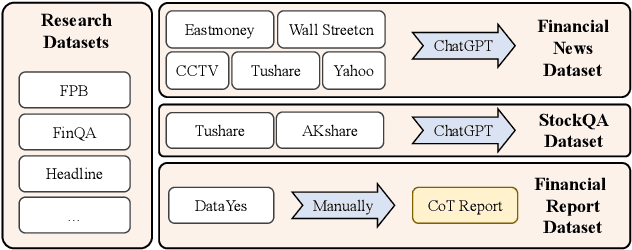
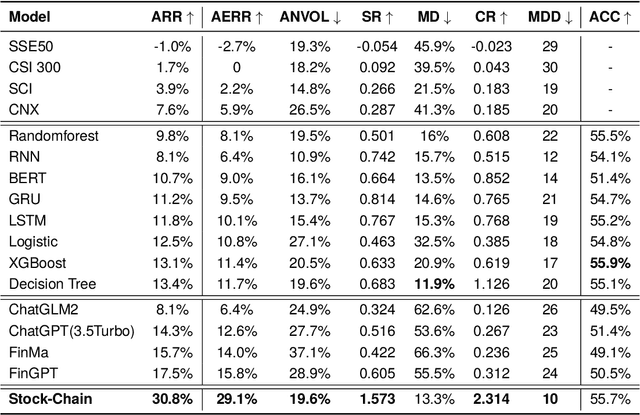
The task of financial analysis primarily encompasses two key areas: stock trend prediction and the corresponding financial question answering. Currently, machine learning and deep learning algorithms (ML&DL) have been widely applied for stock trend predictions, leading to significant progress. However, these methods fail to provide reasons for predictions, lacking interpretability and reasoning processes. Also, they can not integrate textual information such as financial news or reports. Meanwhile, large language models (LLMs) have remarkable textual understanding and generation ability. But due to the scarcity of financial training datasets and limited integration with real-time knowledge, LLMs still suffer from hallucinations and are unable to keep up with the latest information. To tackle these challenges, we first release AlphaFin datasets, combining traditional research datasets, real-time financial data, and handwritten chain-of-thought (CoT) data. It has a positive impact on training LLMs for completing financial analysis. We then use AlphaFin datasets to benchmark a state-of-the-art method, called Stock-Chain, for effectively tackling the financial analysis task, which integrates retrieval-augmented generation (RAG) techniques. Extensive experiments are conducted to demonstrate the effectiveness of our framework on financial analysis.
Imbalance-Agnostic Source-Free Domain Adaptation via Avatar Prototype Alignment
May 22, 2023



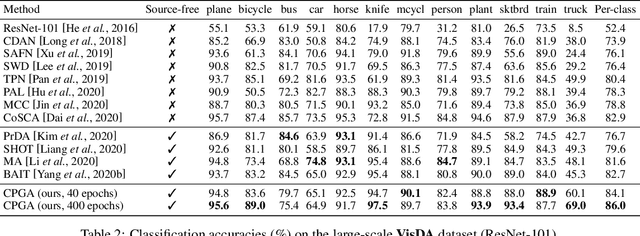
Source-free Unsupervised Domain Adaptation (SF-UDA) aims to adapt a well-trained source model to an unlabeled target domain without access to the source data. One key challenge is the lack of source data during domain adaptation. To handle this, we propose to mine the hidden knowledge of the source model and exploit it to generate source avatar prototypes. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. CPGA consists of two stages: Prototype generation and Prototype adaptation. Extensive experiments on three UDA benchmark datasets demonstrate the superiority of CPGA. However, existing SF.UDA studies implicitly assume balanced class distributions for both the source and target domains, which hinders their real applications. To address this issue, we study a more practical SF-UDA task, termed imbalance-agnostic SF-UDA, where the class distributions of both the unseen source domain and unlabeled target domain are unknown and could be arbitrarily skewed. This task is much more challenging than vanilla SF-UDA due to the co-occurrence of covariate shifts and unidentified class distribution shifts between the source and target domains. To address this task, we extend CPGA and propose a new Target-aware Contrastive Prototype Generation and Adaptation (T-CPGA) method. Specifically, for better prototype adaptation in the imbalance-agnostic scenario, T-CPGA applies a new pseudo label generation strategy to identify unknown target class distribution and generate accurate pseudo labels, by utilizing the collective intelligence of the source model and an additional contrastive language-image pre-trained model. Meanwhile, we further devise a target label-distribution-aware classifier to adapt the model to the unknown target class distribution. We empirically show that T-CPGA significantly outperforms CPGA and other SF-UDA methods in imbalance-agnostic SF-UDA.
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023



Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
Beyond Fixation: Dynamic Window Visual Transformer
Apr 08, 2022

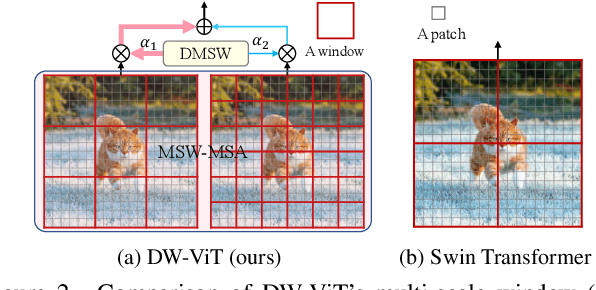

Recently, a surge of interest in visual transformers is to reduce the computational cost by limiting the calculation of self-attention to a local window. Most current work uses a fixed single-scale window for modeling by default, ignoring the impact of window size on model performance. However, this may limit the modeling potential of these window-based models for multi-scale information. In this paper, we propose a novel method, named Dynamic Window Vision Transformer (DW-ViT). The dynamic window strategy proposed by DW-ViT goes beyond the model that employs a fixed single window setting. To the best of our knowledge, we are the first to use dynamic multi-scale windows to explore the upper limit of the effect of window settings on model performance. In DW-ViT, multi-scale information is obtained by assigning windows of different sizes to different head groups of window multi-head self-attention. Then, the information is dynamically fused by assigning different weights to the multi-scale window branches. We conducted a detailed performance evaluation on three datasets, ImageNet-1K, ADE20K, and COCO. Compared with related state-of-the-art (SoTA) methods, DW-ViT obtains the best performance. Specifically, compared with the current SoTA Swin Transformers \cite{liu2021swin}, DW-ViT has achieved consistent and substantial improvements on all three datasets with similar parameters and computational costs. In addition, DW-ViT exhibits good scalability and can be easily inserted into any window-based visual transformers.
Source-free Domain Adaptation via Avatar Prototype Generation and Adaptation
Jun 18, 2021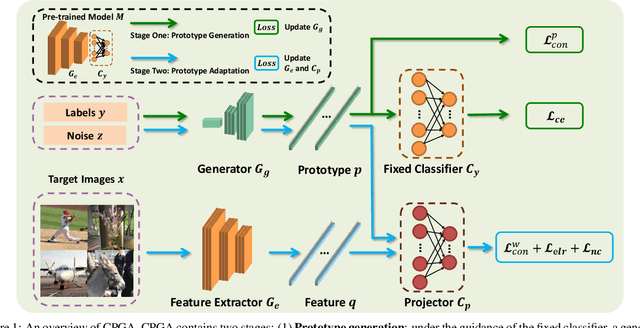
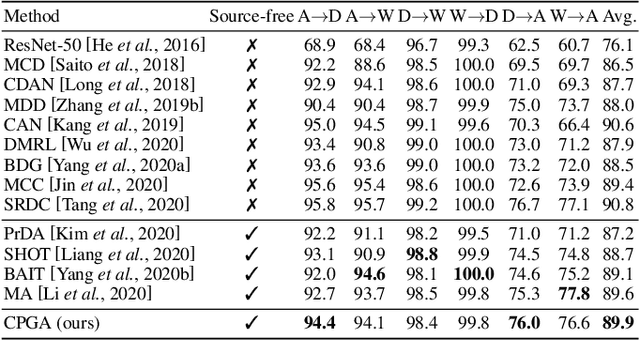
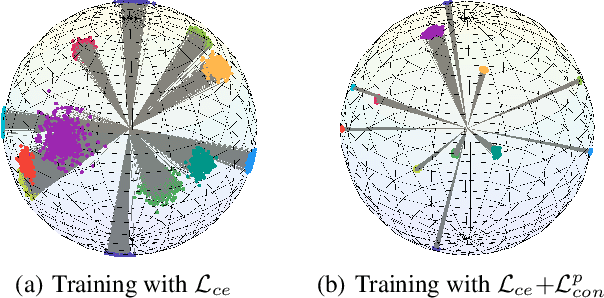
We study a practical domain adaptation task, called source-free unsupervised domain adaptation (UDA) problem, in which we cannot access source domain data due to data privacy issues but only a pre-trained source model and unlabeled target data are available. This task, however, is very difficult due to one key challenge: the lack of source data and target domain labels makes model adaptation very challenging. To address this, we propose to mine the hidden knowledge in the source model and exploit it to generate source avatar prototypes (i.e., representative features for each source class) as well as target pseudo labels for domain alignment. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. Specifically, CPGA consists of two stages: (1) prototype generation: by exploring the classification boundary information of the source model, we train a prototype generator to generate avatar prototypes via contrastive learning. (2) prototype adaptation: based on the generated source prototypes and target pseudo labels, we develop a new robust contrastive prototype adaptation strategy to align each pseudo-labeled target data to the corresponding source prototypes. Extensive experiments on three UDA benchmark datasets demonstrate the effectiveness and superiority of the proposed method.
Towards Accurate Text-based Image Captioning with Content Diversity Exploration
Apr 23, 2021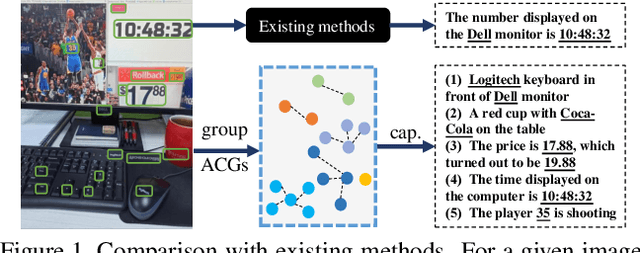
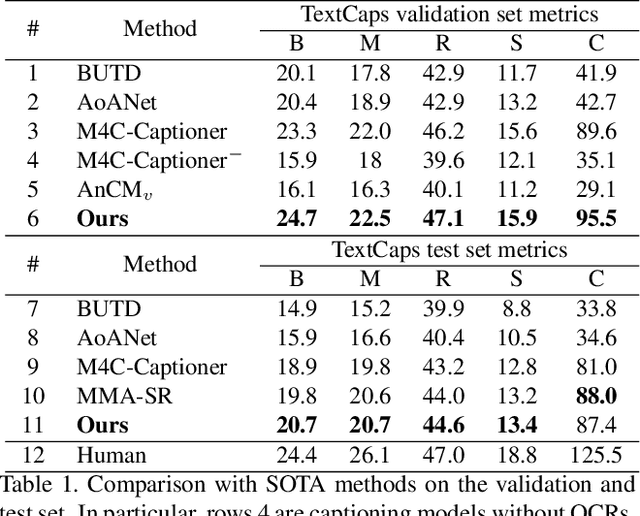
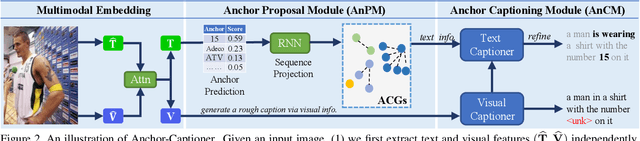
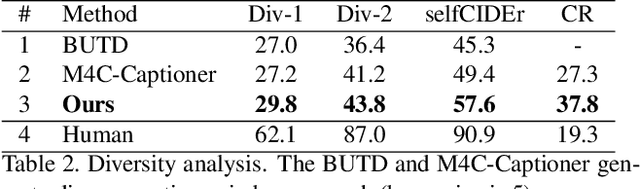
Text-based image captioning (TextCap) which aims to read and reason images with texts is crucial for a machine to understand a detailed and complex scene environment, considering that texts are omnipresent in daily life. This task, however, is very challenging because an image often contains complex texts and visual information that is hard to be described comprehensively. Existing methods attempt to extend the traditional image captioning methods to solve this task, which focus on describing the overall scene of images by one global caption. This is infeasible because the complex text and visual information cannot be described well within one caption. To resolve this difficulty, we seek to generate multiple captions that accurately describe different parts of an image in detail. To achieve this purpose, there are three key challenges: 1) it is hard to decide which parts of the texts of images to copy or paraphrase; 2) it is non-trivial to capture the complex relationship between diverse texts in an image; 3) how to generate multiple captions with diverse content is still an open problem. To conquer these, we propose a novel Anchor-Captioner method. Specifically, we first find the important tokens which are supposed to be paid more attention to and consider them as anchors. Then, for each chosen anchor, we group its relevant texts to construct the corresponding anchor-centred graph (ACG). Last, based on different ACGs, we conduct multi-view caption generation to improve the content diversity of generated captions. Experimental results show that our method not only achieves SOTA performance but also generates diverse captions to describe images.
Location-aware Graph Convolutional Networks for Video Question Answering
Aug 07, 2020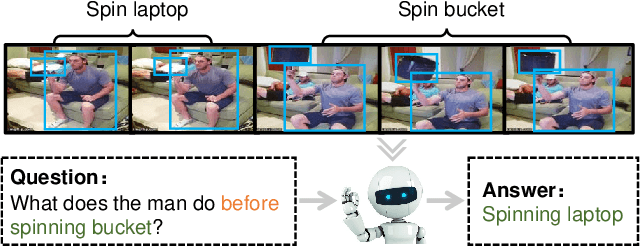

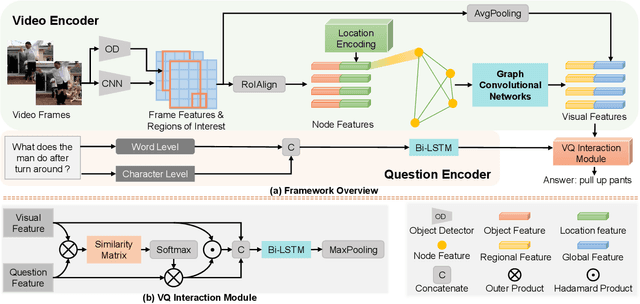
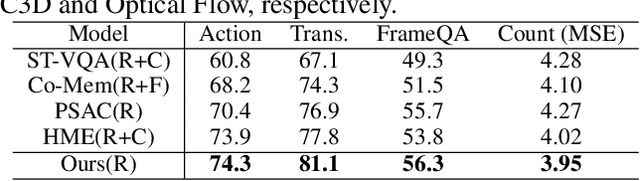
We addressed the challenging task of video question answering, which requires machines to answer questions about videos in a natural language form. Previous state-of-the-art methods attempt to apply spatio-temporal attention mechanism on video frame features without explicitly modeling the location and relations among object interaction occurred in videos. However, the relations between object interaction and their location information are very critical for both action recognition and question reasoning. In this work, we propose to represent the contents in the video as a location-aware graph by incorporating the location information of an object into the graph construction. Here, each node is associated with an object represented by its appearance and location features. Based on the constructed graph, we propose to use graph convolution to infer both the category and temporal locations of an action. As the graph is built on objects, our method is able to focus on the foreground action contents for better video question answering. Lastly, we leverage an attention mechanism to combine the output of graph convolution and encoded question features for final answer reasoning. Extensive experiments demonstrate the effectiveness of the proposed methods. Specifically, our method significantly outperforms state-of-the-art methods on TGIF-QA, Youtube2Text-QA, and MSVD-QA datasets. Code and pre-trained models are publicly available at: https://github.com/SunDoge/L-GCN