 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Boost Test-Time Performance with Closed-Loop Inference
Mar 26, 2022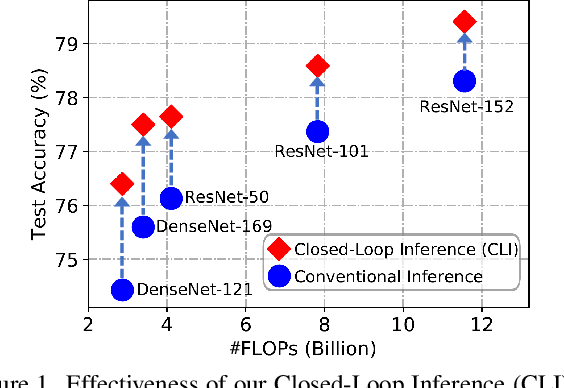
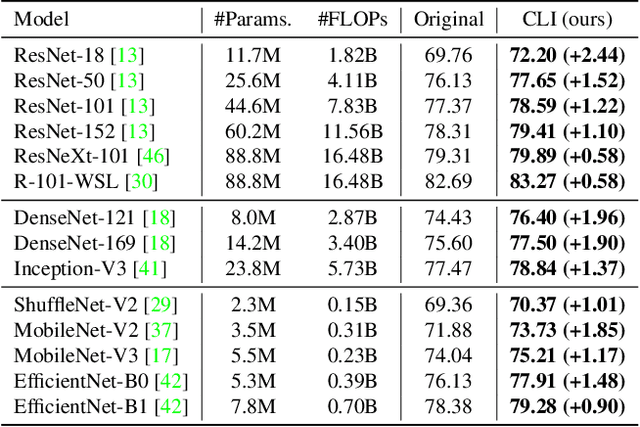
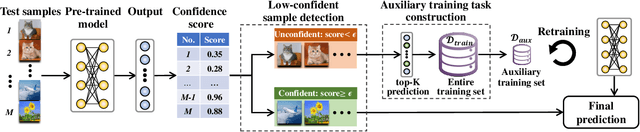
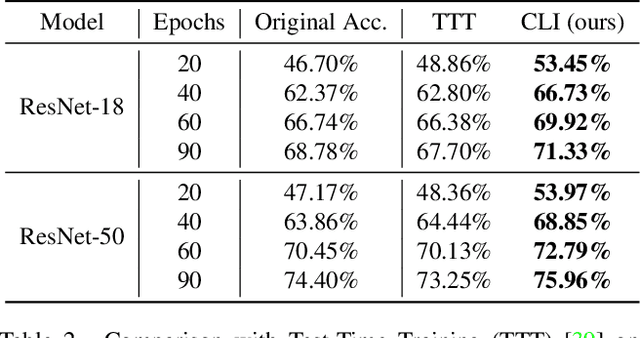
Conventional deep models predict a test sample with a single forward propagation, which, however, may not be sufficient for predicting hard-classified samples. On the contrary, we human beings may need to carefully check the sample many times before making a final decision. During the recheck process, one may refine/adjust the prediction by referring to related samples. Motivated by this, we propose to predict those hard-classified test samples in a looped manner to boost the model performance. However, this idea may pose a critical challenge: how to construct looped inference, so that the original erroneous predictions on these hard test samples can be corrected with little additional effort. To address this, we propose a general Closed-Loop Inference (CLI) method. Specifically, we first devise a filtering criterion to identify those hard-classified test samples that need additional inference loops. For each hard sample, we construct an additional auxiliary learning task based on its original top-$K$ predictions to calibrate the model, and then use the calibrated model to obtain the final prediction. Promising results on ImageNet (in-distribution test samples) and ImageNet-C (out-of-distribution test samples) demonstrate the effectiveness of CLI in improving the performance of any pre-trained model.
AdaXpert: Adapting Neural Architecture for Growing Data
Jul 01, 2021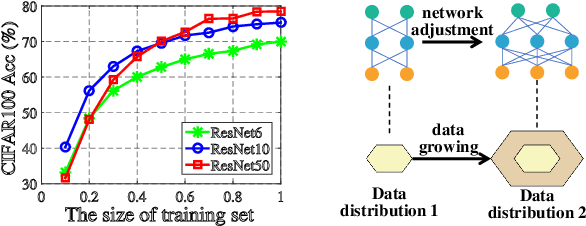
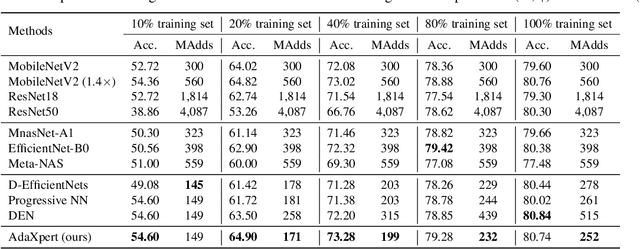
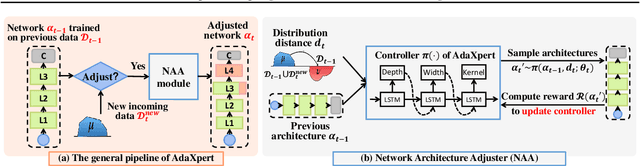
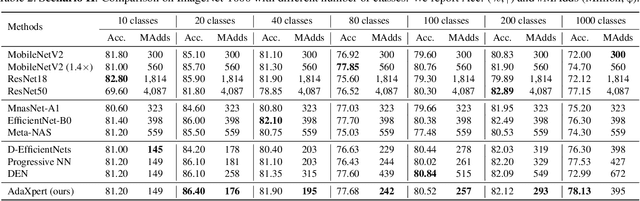
In real-world applications, data often come in a growing manner, where the data volume and the number of classes may increase dynamically. This will bring a critical challenge for learning: given the increasing data volume or the number of classes, one has to instantaneously adjust the neural model capacity to obtain promising performance. Existing methods either ignore the growing nature of data or seek to independently search an optimal architecture for a given dataset, and thus are incapable of promptly adjusting the architectures for the changed data. To address this, we present a neural architecture adaptation method, namely Adaptation eXpert (AdaXpert), to efficiently adjust previous architectures on the growing data. Specifically, we introduce an architecture adjuster to generate a suitable architecture for each data snapshot, based on the previous architecture and the different extent between current and previous data distributions. Furthermore, we propose an adaptation condition to determine the necessity of adjustment, thereby avoiding unnecessary and time-consuming adjustments. Extensive experiments on two growth scenarios (increasing data volume and number of classes) demonstrate the effectiveness of the proposed method.
Towards Accurate Text-based Image Captioning with Content Diversity Exploration
Apr 23, 2021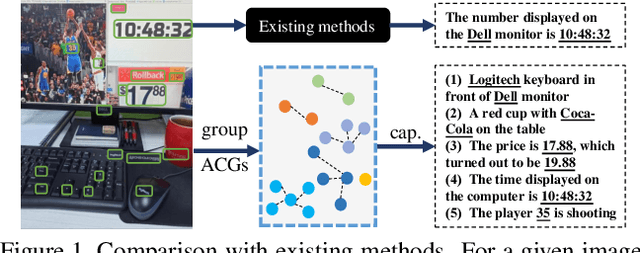
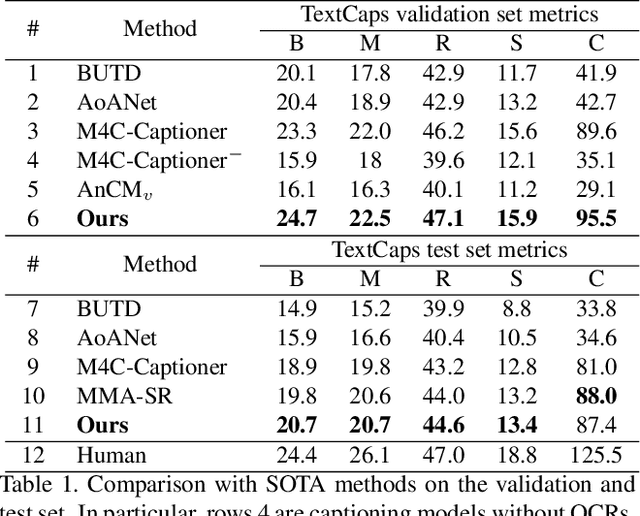
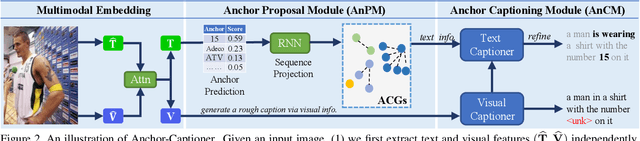
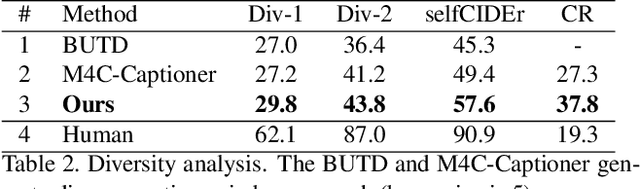
Text-based image captioning (TextCap) which aims to read and reason images with texts is crucial for a machine to understand a detailed and complex scene environment, considering that texts are omnipresent in daily life. This task, however, is very challenging because an image often contains complex texts and visual information that is hard to be described comprehensively. Existing methods attempt to extend the traditional image captioning methods to solve this task, which focus on describing the overall scene of images by one global caption. This is infeasible because the complex text and visual information cannot be described well within one caption. To resolve this difficulty, we seek to generate multiple captions that accurately describe different parts of an image in detail. To achieve this purpose, there are three key challenges: 1) it is hard to decide which parts of the texts of images to copy or paraphrase; 2) it is non-trivial to capture the complex relationship between diverse texts in an image; 3) how to generate multiple captions with diverse content is still an open problem. To conquer these, we propose a novel Anchor-Captioner method. Specifically, we first find the important tokens which are supposed to be paid more attention to and consider them as anchors. Then, for each chosen anchor, we group its relevant texts to construct the corresponding anchor-centred graph (ACG). Last, based on different ACGs, we conduct multi-view caption generation to improve the content diversity of generated captions. Experimental results show that our method not only achieves SOTA performance but also generates diverse captions to describe images.
How to Train Your Agent to Read and Write
Jan 04, 2021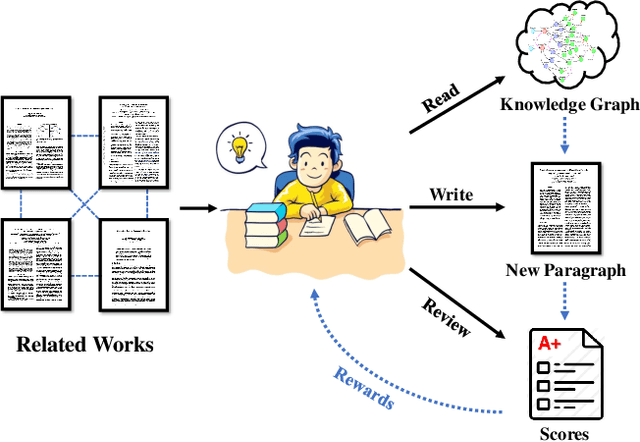
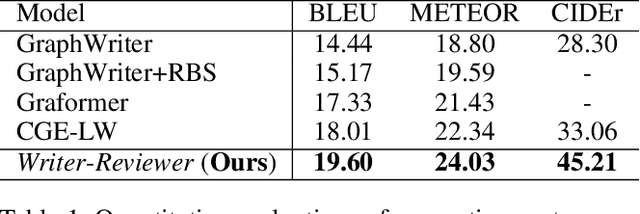
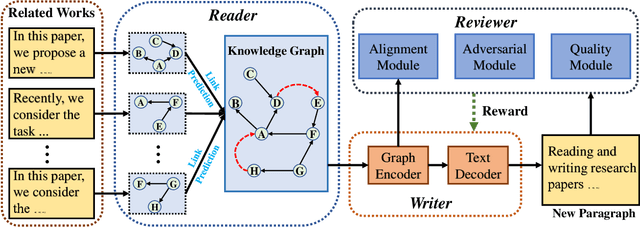

Reading and writing research papers is one of the most privileged abilities that a qualified researcher should master. However, it is difficult for new researchers (\eg{students}) to fully {grasp} this ability. It would be fascinating if we could train an intelligent agent to help people read and summarize papers, and perhaps even discover and exploit the potential knowledge clues to write novel papers. Although there have been existing works focusing on summarizing (\emph{i.e.}, reading) the knowledge in a given text or generating (\emph{i.e.}, writing) a text based on the given knowledge, the ability of simultaneously reading and writing is still under development. Typically, this requires an agent to fully understand the knowledge from the given text materials and generate correct and fluent novel paragraphs, which is very challenging in practice. In this paper, we propose a Deep ReAder-Writer (DRAW) network, which consists of a \textit{Reader} that can extract knowledge graphs (KGs) from input paragraphs and discover potential knowledge, a graph-to-text \textit{Writer} that generates a novel paragraph, and a \textit{Reviewer} that reviews the generated paragraph from three different aspects. Extensive experiments show that our DRAW network outperforms considered baselines and several state-of-the-art methods on AGENDA and M-AGENDA datasets. Our code and supplementary are released at https://github.com/menggehe/DRAW.
Improving Prosody Modelling with Cross-Utterance BERT Embeddings for End-to-end Speech Synthesis
Nov 06, 2020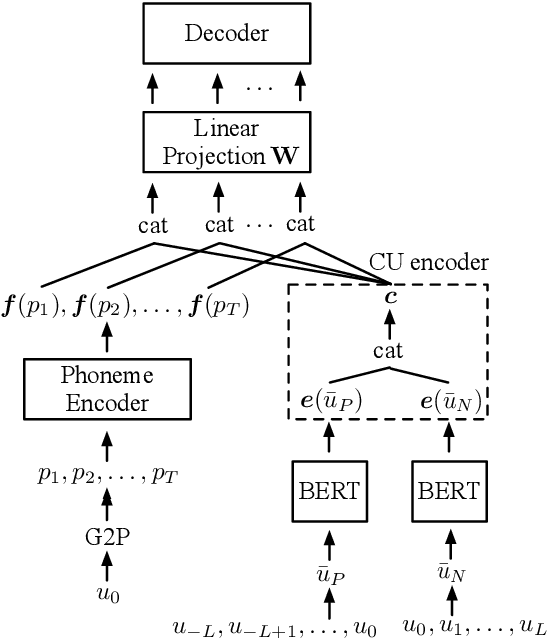
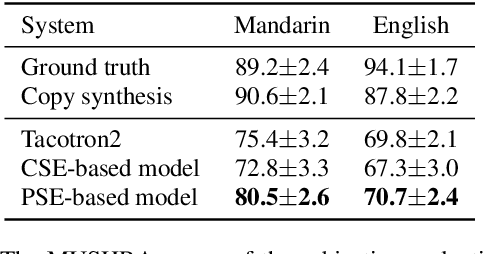
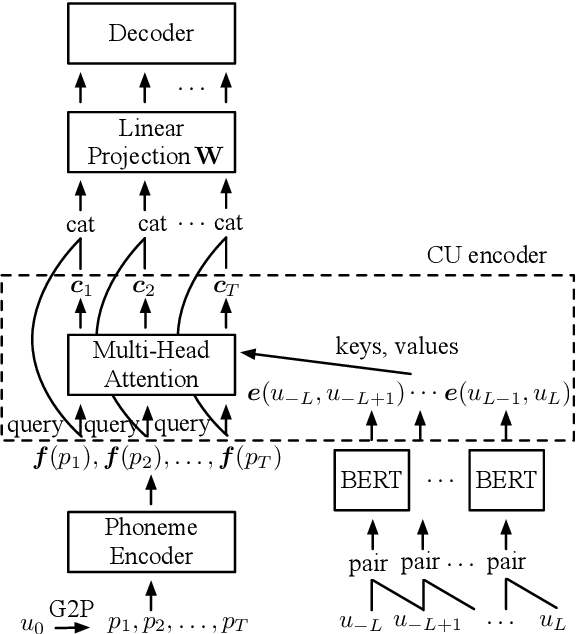
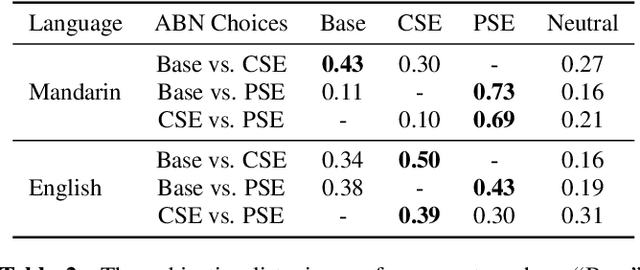
Despite prosody is related to the linguistic information up to the discourse structure, most text-to-speech (TTS) systems only take into account that within each sentence, which makes it challenging when converting a paragraph of texts into natural and expressive speech. In this paper, we propose to use the text embeddings of the neighboring sentences to improve the prosody generation for each utterance of a paragraph in an end-to-end fashion without using any explicit prosody features. More specifically, cross-utterance (CU) context vectors, which are produced by an additional CU encoder based on the sentence embeddings extracted by a pre-trained BERT model, are used to augment the input of the Tacotron2 decoder. Two types of BERT embeddings are investigated, which leads to the use of different CU encoder structures. Experimental results on a Mandarin audiobook dataset and the LJ-Speech English audiobook dataset demonstrate the use of CU information can improve the naturalness and expressiveness of the synthesized speech. Subjective listening testing shows most of the participants prefer the voice generated using the CU encoder over that generated using standard Tacotron2. It is also found that the prosody can be controlled indirectly by changing the neighbouring sentences.
REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
Oct 08, 2019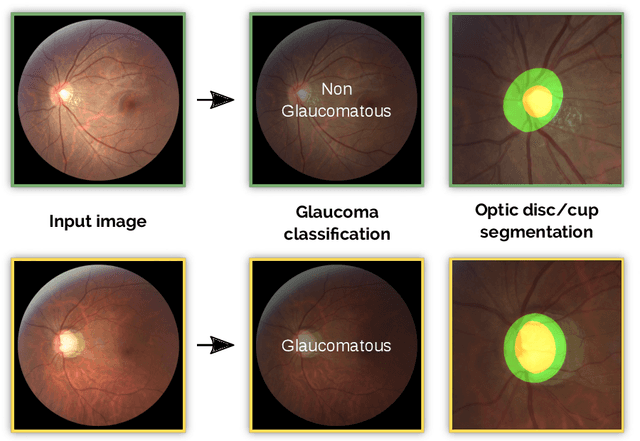
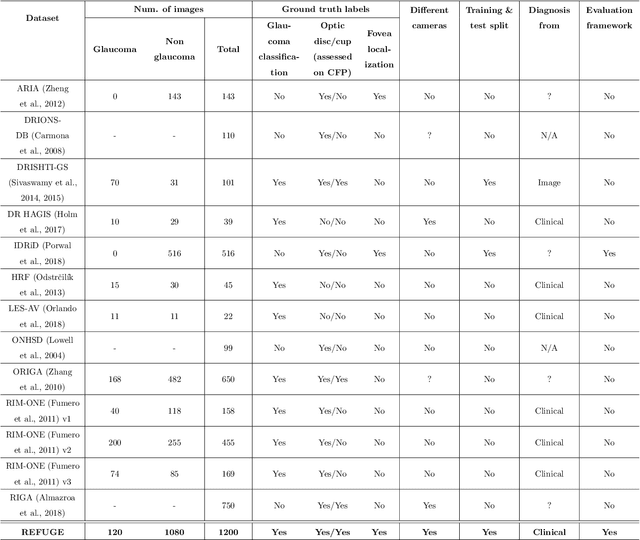

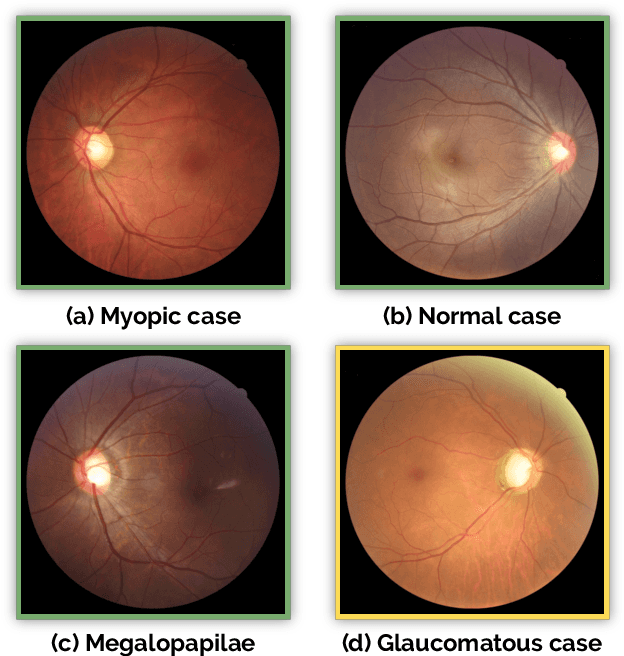
Glaucoma is one of the leading causes of irreversible but preventable blindness in working age populations. Color fundus photography (CFP) is the most cost-effective imaging modality to screen for retinal disorders. However, its application to glaucoma has been limited to the computation of a few related biomarkers such as the vertical cup-to-disc ratio. Deep learning approaches, although widely applied for medical image analysis, have not been extensively used for glaucoma assessment due to the limited size of the available data sets. Furthermore, the lack of a standardize benchmark strategy makes difficult to compare existing methods in a uniform way. In order to overcome these issues we set up the Retinal Fundus Glaucoma Challenge, REFUGE (\url{https://refuge.grand-challenge.org}), held in conjunction with MICCAI 2018. The challenge consisted of two primary tasks, namely optic disc/cup segmentation and glaucoma classification. As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one. We have also built an evaluation framework to ease and ensure fairness in the comparison of different models, encouraging the development of novel techniques in the field. 12 teams qualified and participated in the online challenge. This paper summarizes their methods and analyzes their corresponding results. In particular, we observed that two of the top-ranked teams outperformed two human experts in the glaucoma classification task. Furthermore, the segmentation results were in general consistent with the ground truth annotations, with complementary outcomes that can be further exploited by ensembling the results.
Building a mixed-lingual neural TTS system with only monolingual data
Apr 12, 2019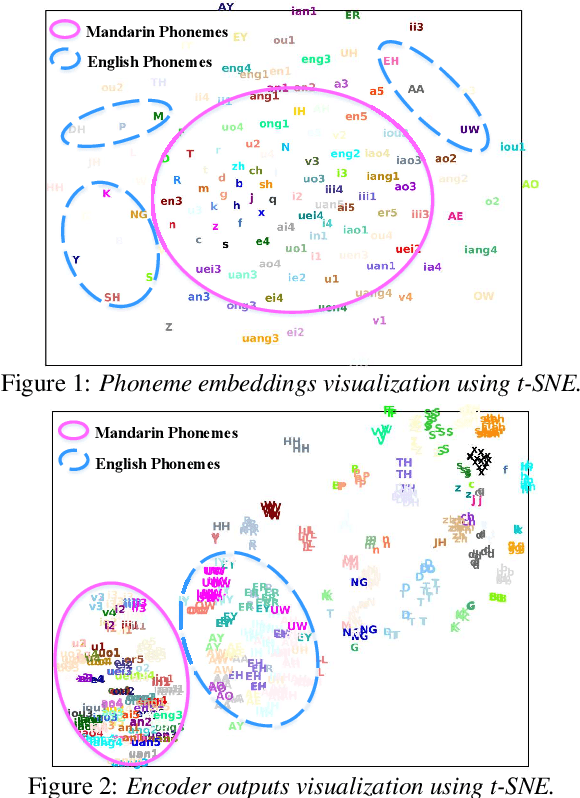
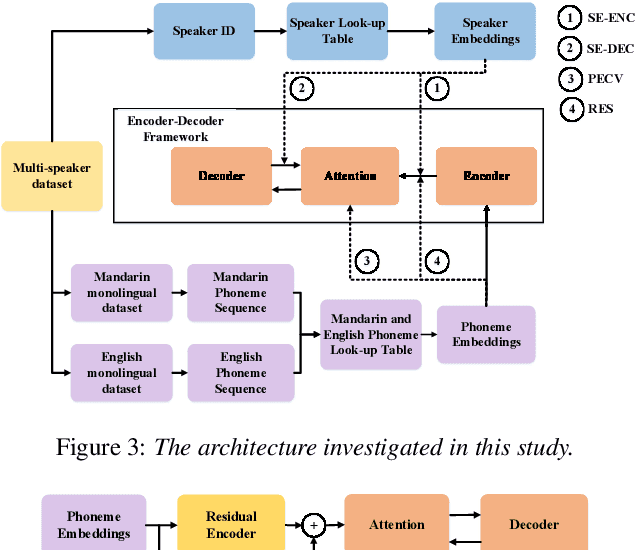

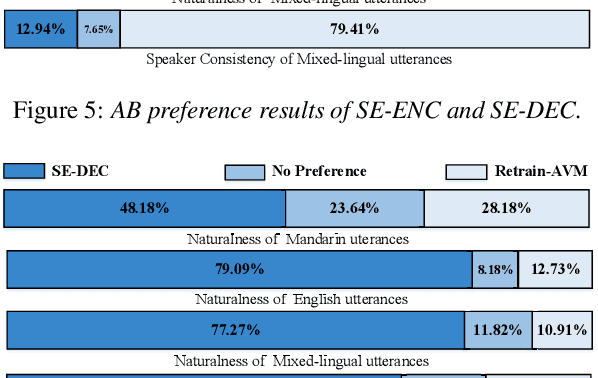
When deploying a Chinese neural text-to-speech (TTS) synthesis system, one of the challenges is to synthesize Chinese utterances with English phrases or words embedded. This paper looks into the problem in the encoder-decoder framework when only monolingual data from a target speaker is available. Specifically, we view the problem from two aspects: speaker consistency within an utterance and naturalness. We start the investigation with an Average Voice Model which is built from multi-speaker monolingual data, i.e. Mandarin and English data. On the basis of that, we look into speaker embedding for speaker consistency within an utterance and phoneme embedding for naturalness and intelligibility and study the choice of data for model training. We report the findings and discuss the challenges to build a mixed-lingual TTS system with only monolingual data.
You Only Look & Listen Once: Towards Fast and Accurate Visual Grounding
Mar 17, 2019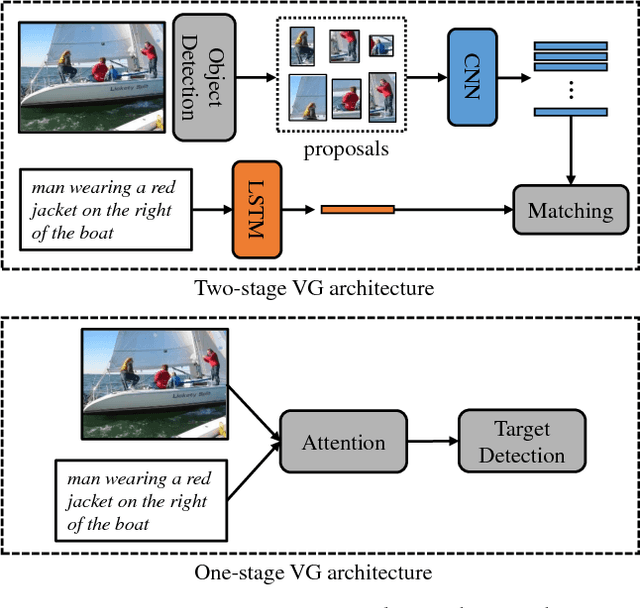
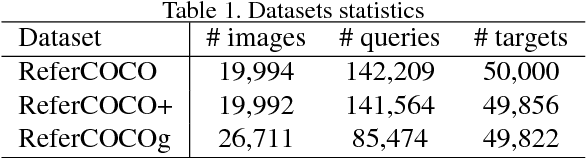
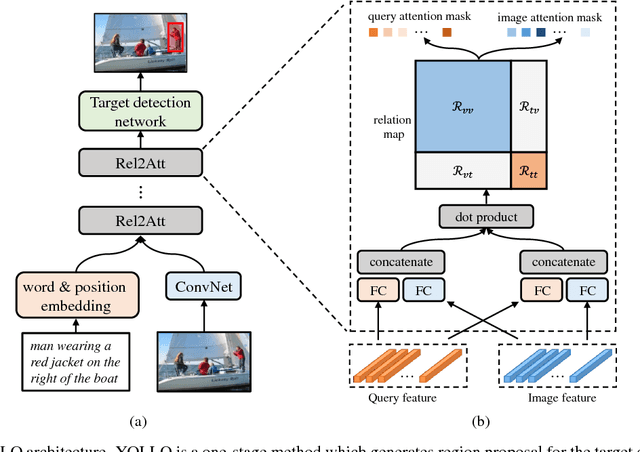
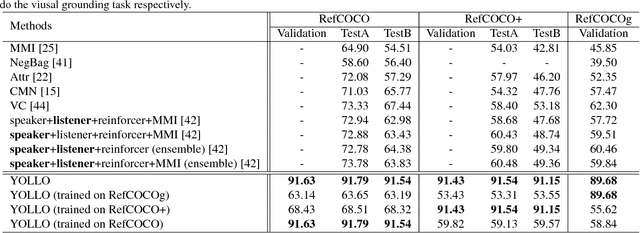
Visual Grounding (VG) aims to locate the most relevant region in an image, based on a flexible natural language query but not a pre-defined label, thus it can be a more useful technique than object detection in practice. Most state-of-the-art methods in VG operate in a two-stage manner, wherein the first stage an object detector is adopted to generate a set of object proposals from the input image and the second stage is simply formulated as a cross-modal matching problem that finds the best match between the language query and all region proposals. This is rather inefficient because there might be hundreds of proposals produced in the first stage that need to be compared in the second stage, not to mention this strategy performs inaccurately. In this paper, we propose an simple, intuitive and much more elegant one-stage detection based method that joints the region proposal and matching stage as a single detection network. The detection is conditioned on the input query with a stack of novel Relation-to-Attention modules that transform the image-to-query relationship to an relation map, which is used to predict the bounding box directly without proposing large numbers of useless region proposals. During the inference, our approach is about 20x ~ 30x faster than previous methods and, remarkably, it achieves 18% ~ 41% absolute performance improvement on top of the state-of-the-art results on several benchmark datasets. We release our code and all the pre-trained models at https://github.com/openblack/rvg.