 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt in the Wild: Test-Time Entropy Minimization with Sharpness and Feature Regularization
Sep 05, 2025Test-time adaptation (TTA) may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, 3) online imbalanced label distribution shifts. This is often a key obstacle preventing existing TTA methods from being deployed in the real world. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, i.e., group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases, i.e., the model collapses into trivial solutions by assigning the same class label for all samples. By digging into this, we find that, during the collapse process: 1) the model gradients often undergo an initial explosion followed by rapid degradation, suggesting that certain noisy test samples with large gradients may disrupt adaptation; and 2) the model representations tend to exhibit high correlations and classification bias. To address this, we first propose a sharpness-aware and reliable entropy minimization method, called SAR, for stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Based on SAR, we further introduce SAR^2 to prevent representation collapse with two regularizers: 1) a redundancy regularizer to reduce inter-dimensional correlations among centroid-invariant features; and 2) an inequity regularizer to maximize the prediction entropy of a prototype centroid, thereby penalizing biased representations toward any specific class. Promising results demonstrate that our methods perform more stably over prior methods and are computationally efficient under the above wild test scenarios.
Uncertainty-Calibrated Test-Time Model Adaptation without Forgetting
Mar 18, 2024Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and test data by adapting a given model w.r.t. any test sample. Although recent TTA has shown promising performance, we still face two key challenges: 1) prior methods perform backpropagation for each test sample, resulting in unbearable optimization costs to many applications; 2) while existing TTA can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as forgetting). To this end, we have proposed an Efficient Anti-Forgetting Test-Time Adaptation (EATA) method which develops an active sample selection criterion to identify reliable and non-redundant samples for test-time entropy minimization. To alleviate forgetting, EATA introduces a Fisher regularizer estimated from test samples to constrain important model parameters from drastic changes. However, in EATA, the adopted entropy loss consistently assigns higher confidence to predictions even for samples that are underlying uncertain, leading to overconfident predictions. To tackle this, we further propose EATA with Calibration (EATA-C) to separately exploit the reducible model uncertainty and the inherent data uncertainty for calibrated TTA. Specifically, we measure the model uncertainty by the divergence between predictions from the full network and its sub-networks, on which we propose a divergence loss to encourage consistent predictions instead of overconfident ones. To further recalibrate prediction confidence, we utilize the disagreement among predicted labels as an indicator of the data uncertainty, and then devise a min-max entropy regularizer to selectively increase and decrease prediction confidence for different samples. Experiments on image classification and semantic segmentation verify the effectiveness of our methods.
A Synchronized Layer-by-layer Growing Approach for Plausible Neuronal Morphology Generation
Jan 17, 2024



Neuronal morphology is essential for studying brain functioning and understanding neurodegenerative disorders. As the acquiring of real-world morphology data is expensive, computational approaches especially learning-based ones e.g. MorphVAE for morphology generation were recently studied, which are often conducted in a way of randomly augmenting a given authentic morphology to achieve plausibility. Under such a setting, this paper proposes \textbf{MorphGrower} which aims to generate more plausible morphology samples by mimicking the natural growth mechanism instead of a one-shot treatment as done in MorphVAE. Specifically, MorphGrower generates morphologies layer by layer synchronously and chooses a pair of sibling branches as the basic generation block, and the generation of each layer is conditioned on the morphological structure of previous layers and then generate morphologies via a conditional variational autoencoder with spherical latent space. Extensive experimental results on four real-world datasets demonstrate that MorphGrower outperforms MorphVAE by a notable margin. Our code will be publicly available to facilitate future research.
PsyCoT: Psychological Questionnaire as Powerful Chain-of-Thought for Personality Detection
Nov 05, 2023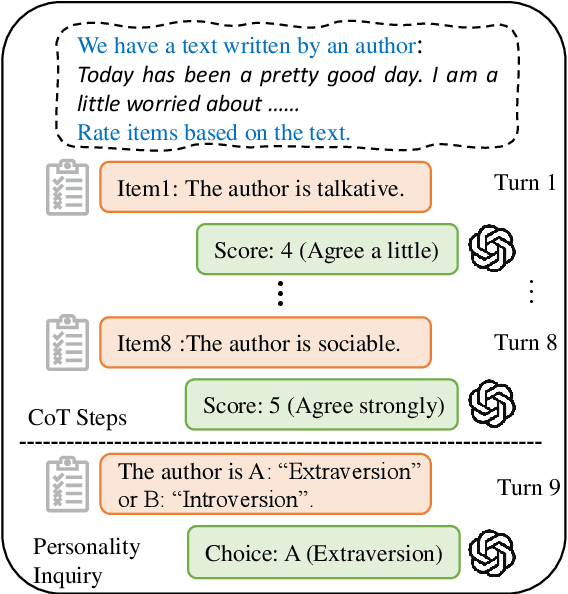
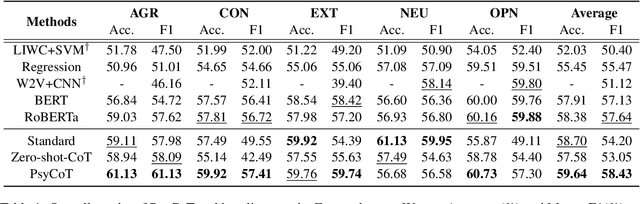

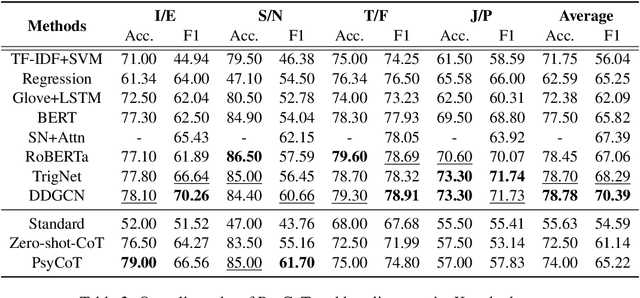
Recent advances in large language models (LLMs), such as ChatGPT, have showcased remarkable zero-shot performance across various NLP tasks. However, the potential of LLMs in personality detection, which involves identifying an individual's personality from their written texts, remains largely unexplored. Drawing inspiration from Psychological Questionnaires, which are carefully designed by psychologists to evaluate individual personality traits through a series of targeted items, we argue that these items can be regarded as a collection of well-structured chain-of-thought (CoT) processes. By incorporating these processes, LLMs can enhance their capabilities to make more reasonable inferences on personality from textual input. In light of this, we propose a novel personality detection method, called PsyCoT, which mimics the way individuals complete psychological questionnaires in a multi-turn dialogue manner. In particular, we employ a LLM as an AI assistant with a specialization in text analysis. We prompt the assistant to rate individual items at each turn and leverage the historical rating results to derive a conclusive personality preference. Our experiments demonstrate that PsyCoT significantly improves the performance and robustness of GPT-3.5 in personality detection, achieving an average F1 score improvement of 4.23/10.63 points on two benchmark datasets compared to the standard prompting method. Our code is available at https://github.com/TaoYang225/PsyCoT.
Privacy-Preserving Face Recognition Using Random Frequency Components
Aug 21, 2023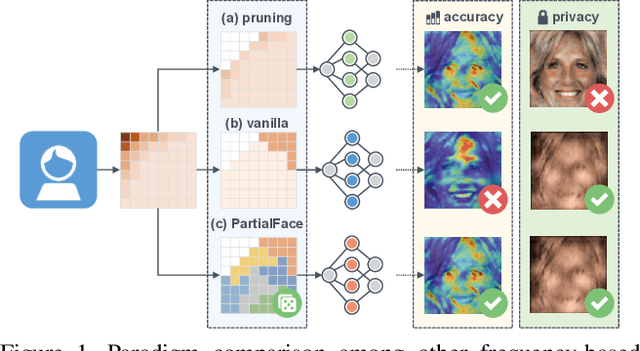
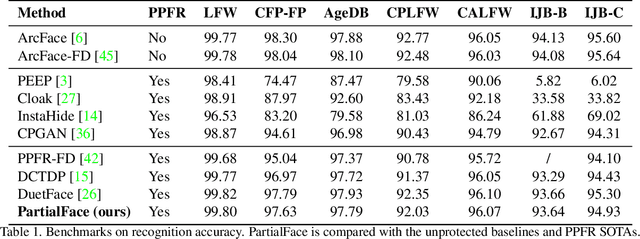
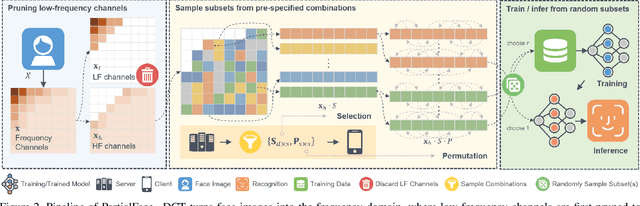

The ubiquitous use of face recognition has sparked increasing privacy concerns, as unauthorized access to sensitive face images could compromise the information of individuals. This paper presents an in-depth study of the privacy protection of face images' visual information and against recovery. Drawing on the perceptual disparity between humans and models, we propose to conceal visual information by pruning human-perceivable low-frequency components. For impeding recovery, we first elucidate the seeming paradox between reducing model-exploitable information and retaining high recognition accuracy. Based on recent theoretical insights and our observation on model attention, we propose a solution to the dilemma, by advocating for the training and inference of recognition models on randomly selected frequency components. We distill our findings into a novel privacy-preserving face recognition method, PartialFace. Extensive experiments demonstrate that PartialFace effectively balances privacy protection goals and recognition accuracy. Code is available at: https://github.com/Tencent/TFace.
RPTQ: Reorder-based Post-training Quantization for Large Language Models
Apr 25, 2023Large-scale language models (LLMs) have demonstrated outstanding performance on various tasks, but their deployment poses challenges due to their enormous model size. In this paper, we identify that the main challenge in quantizing LLMs stems from the different activation ranges between the channels, rather than just the issue of outliers.We propose a novel reorder-based quantization approach, RPTQ, that addresses the issue of quantizing the activations of LLMs. RPTQ rearranges the channels in the activations and then quantizing them in clusters, thereby reducing the impact of range difference of channels. In addition, we reduce the storage and computation overhead by avoiding explicit reordering. By implementing this approach, we achieved a significant breakthrough by pushing LLM models to 3 bit activation for the first time.
Benchmarking the Reliability of Post-training Quantization: a Particular Focus on Worst-case Performance
Mar 23, 2023Post-training quantization (PTQ) is a popular method for compressing deep neural networks (DNNs) without modifying their original architecture or training procedures. Despite its effectiveness and convenience, the reliability of PTQ methods in the presence of some extrem cases such as distribution shift and data noise remains largely unexplored. This paper first investigates this problem on various commonly-used PTQ methods. We aim to answer several research questions related to the influence of calibration set distribution variations, calibration paradigm selection, and data augmentation or sampling strategies on PTQ reliability. A systematic evaluation process is conducted across a wide range of tasks and commonly-used PTQ paradigms. The results show that most existing PTQ methods are not reliable enough in term of the worst-case group performance, highlighting the need for more robust methods. Our findings provide insights for developing PTQ methods that can effectively handle distribution shift scenarios and enable the deployment of quantized DNNs in real-world applications.
Towards Stable Test-Time Adaptation in Dynamic Wild World
Feb 24, 2023Test-time adaptation (TTA) has shown to be effective at tackling distribution shifts between training and testing data by adapting a given model on test samples. However, the online model updating of TTA may be unstable and this is often a key obstacle preventing existing TTA methods from being deployed in the real world. Specifically, TTA may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, and 3) online imbalanced label distribution shifts, which are quite common in practice. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, \ie, group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases. By digging into the failure cases, we find that certain noisy test samples with large gradients may disturb the model adaption and result in collapsed trivial solutions, \ie, assigning the same class label for all samples. To address the above collapse issue, we propose a sharpness-aware and reliable entropy minimization method, called SAR, for further stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Promising results demonstrate that SAR performs more stably over prior methods and is computationally efficient under the above wild test scenarios.
Quantized Adaptive Subgradient Algorithms and Their Applications
Aug 11, 2022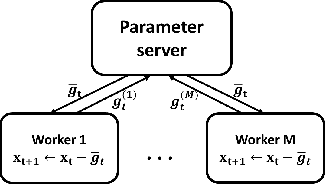
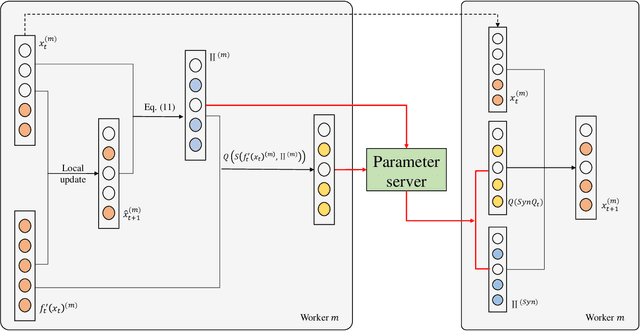
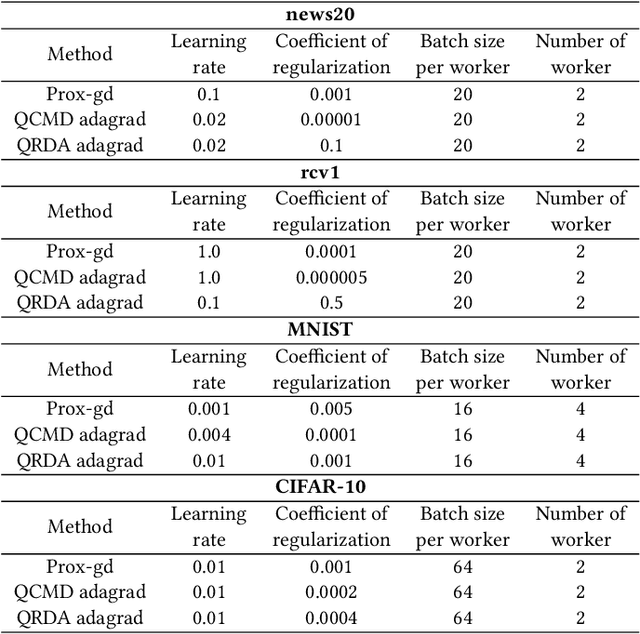

Data explosion and an increase in model size drive the remarkable advances in large-scale machine learning, but also make model training time-consuming and model storage difficult. To address the above issues in the distributed model training setting which has high computation efficiency and less device limitation, there are still two main difficulties. On one hand, the communication costs for exchanging information, e.g., stochastic gradients among different workers, is a key bottleneck for distributed training efficiency. On the other hand, less parameter model is easy for storage and communication, but the risk of damaging the model performance. To balance the communication costs, model capacity and model performance simultaneously, we propose quantized composite mirror descent adaptive subgradient (QCMD adagrad) and quantized regularized dual average adaptive subgradient (QRDA adagrad) for distributed training. To be specific, we explore the combination of gradient quantization and sparse model to reduce the communication cost per iteration in distributed training. A quantized gradient-based adaptive learning rate matrix is constructed to achieve a balance between communication costs, accuracy, and model sparsity. Moreover, we theoretically find that a large quantization error brings in extra noise, which influences the convergence and sparsity of the model. Therefore, a threshold quantization strategy with a relatively small error is adopted in QCMD adagrad and QRDA adagrad to improve the signal-to-noise ratio and preserve the sparsity of the model. Both theoretical analyses and empirical results demonstrate the efficacy and efficiency of the proposed algorithms.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 19, 2022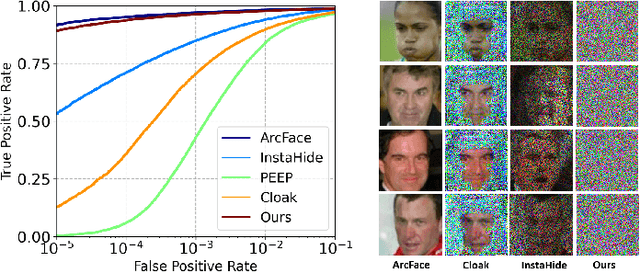

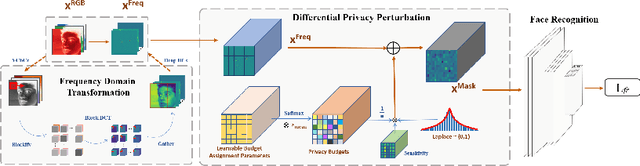
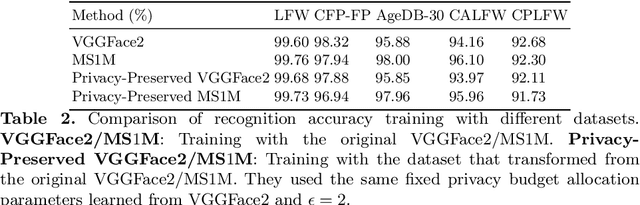
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.