 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Adaptive Subgradient Algorithms and Their Applications
Paper and Code
Aug 11, 2022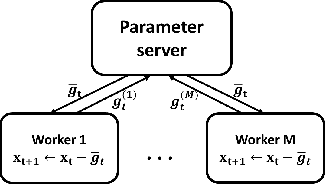
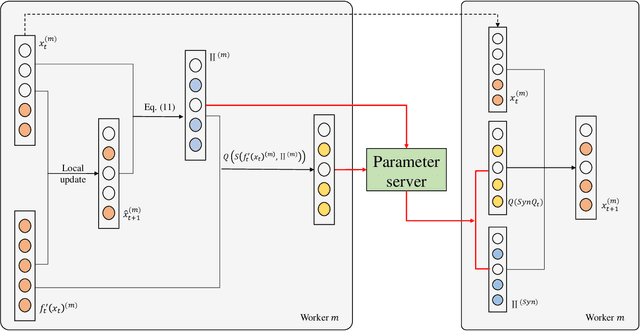

Data explosion and an increase in model size drive the remarkable advances in large-scale machine learning, but also make model training time-consuming and model storage difficult. To address the above issues in the distributed model training setting which has high computation efficiency and less device limitation, there are still two main difficulties. On one hand, the communication costs for exchanging information, e.g., stochastic gradients among different workers, is a key bottleneck for distributed training efficiency. On the other hand, less parameter model is easy for storage and communication, but the risk of damaging the model performance. To balance the communication costs, model capacity and model performance simultaneously, we propose quantized composite mirror descent adaptive subgradient (QCMD adagrad) and quantized regularized dual average adaptive subgradient (QRDA adagrad) for distributed training. To be specific, we explore the combination of gradient quantization and sparse model to reduce the communication cost per iteration in distributed training. A quantized gradient-based adaptive learning rate matrix is constructed to achieve a balance between communication costs, accuracy, and model sparsity. Moreover, we theoretically find that a large quantization error brings in extra noise, which influences the convergence and sparsity of the model. Therefore, a threshold quantization strategy with a relatively small error is adopted in QCMD adagrad and QRDA adagrad to improve the signal-to-noise ratio and preserve the sparsity of the model. Both theoretical analyses and empirical results demonstrate the efficacy and efficiency of the proposed algorithms.