 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Denoising Diffusion Model for Blind Image Quality Assessment
Jan 22, 2024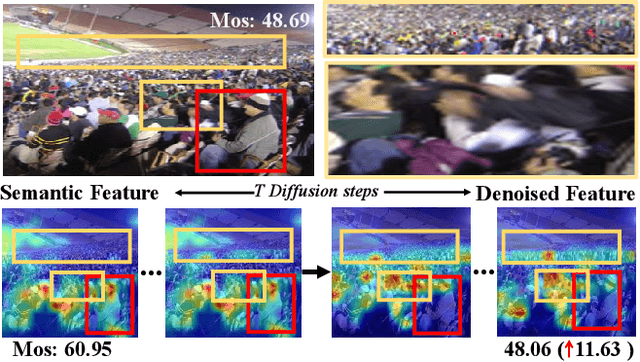
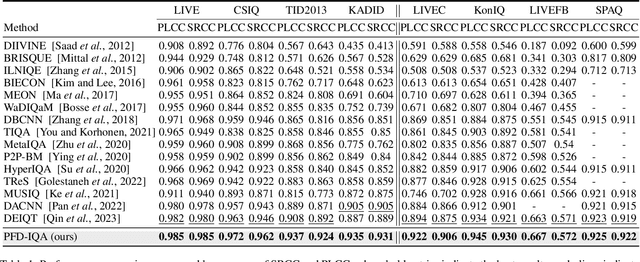
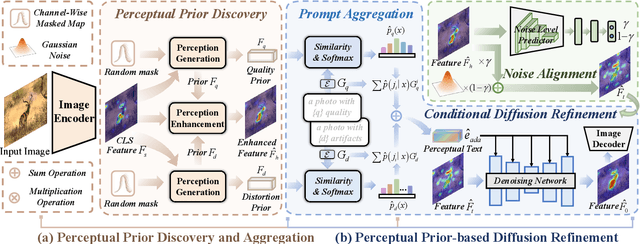
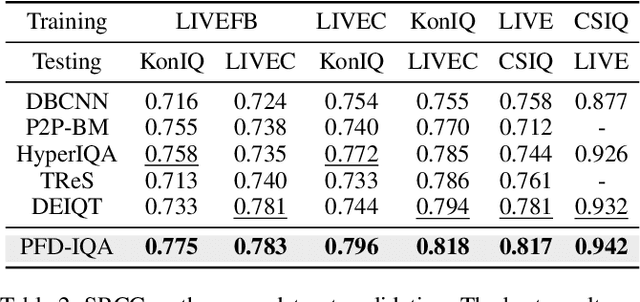
Blind Image Quality Assessment (BIQA) aims to evaluate image quality in line with human perception, without reference benchmarks. Currently, deep learning BIQA methods typically depend on using features from high-level tasks for transfer learning. However, the inherent differences between BIQA and these high-level tasks inevitably introduce noise into the quality-aware features. In this paper, we take an initial step towards exploring the diffusion model for feature denoising in BIQA, namely Perceptual Feature Diffusion for IQA (PFD-IQA), which aims to remove noise from quality-aware features. Specifically, (i) We propose a {Perceptual Prior Discovery and Aggregation module to establish two auxiliary tasks to discover potential low-level features in images that are used to aggregate perceptual text conditions for the diffusion model. (ii) We propose a Perceptual Prior-based Feature Refinement strategy, which matches noisy features to predefined denoising trajectories and then performs exact feature denoising based on text conditions. Extensive experiments on eight standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods, i.e., achieving the PLCC values of 0.935 ( vs. 0.905 in KADID) and 0.922 ( vs. 0.894 in LIVEC).
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 19, 2022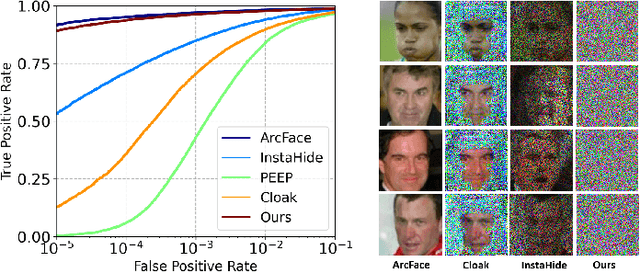

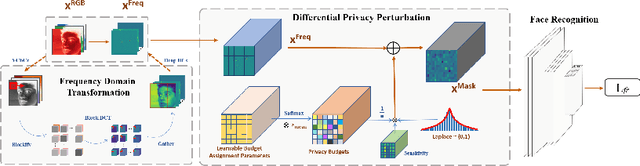
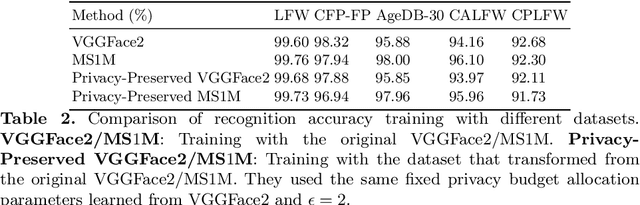
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
ISTR: End-to-End Instance Segmentation with Transformers
May 06, 2021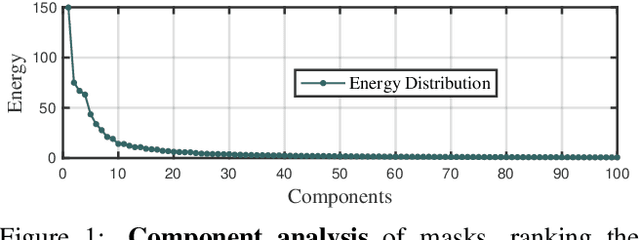

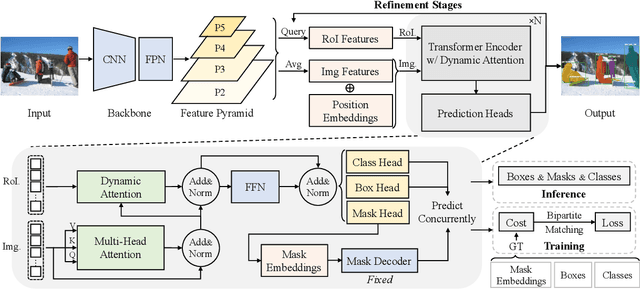

End-to-end paradigms significantly improve the accuracy of various deep-learning-based computer vision models. To this end, tasks like object detection have been upgraded by replacing non-end-to-end components, such as removing non-maximum suppression by training with a set loss based on bipartite matching. However, such an upgrade is not applicable to instance segmentation, due to its significantly higher output dimensions compared to object detection. In this paper, we propose an instance segmentation Transformer, termed ISTR, which is the first end-to-end framework of its kind. ISTR predicts low-dimensional mask embeddings, and matches them with ground truth mask embeddings for the set loss. Besides, ISTR concurrently conducts detection and segmentation with a recurrent refinement strategy, which provides a new way to achieve instance segmentation compared to the existing top-down and bottom-up frameworks. Benefiting from the proposed end-to-end mechanism, ISTR demonstrates state-of-the-art performance even with approximation-based suboptimal embeddings. Specifically, ISTR obtains a 46.8/38.6 box/mask AP using ResNet50-FPN, and a 48.1/39.9 box/mask AP using ResNet101-FPN, on the MS COCO dataset. Quantitative and qualitative results reveal the promising potential of ISTR as a solid baseline for instance-level recognition. Code has been made available at: https://github.com/hujiecpp/ISTR.
Architecture Disentanglement for Deep Neural Networks
Mar 30, 2020
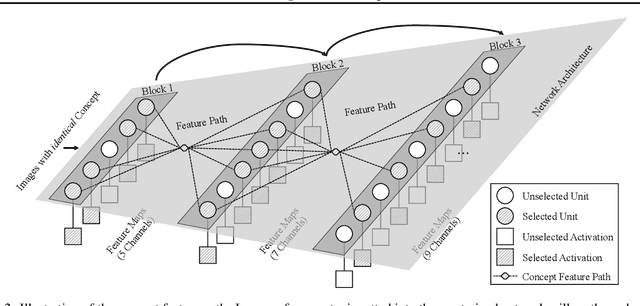
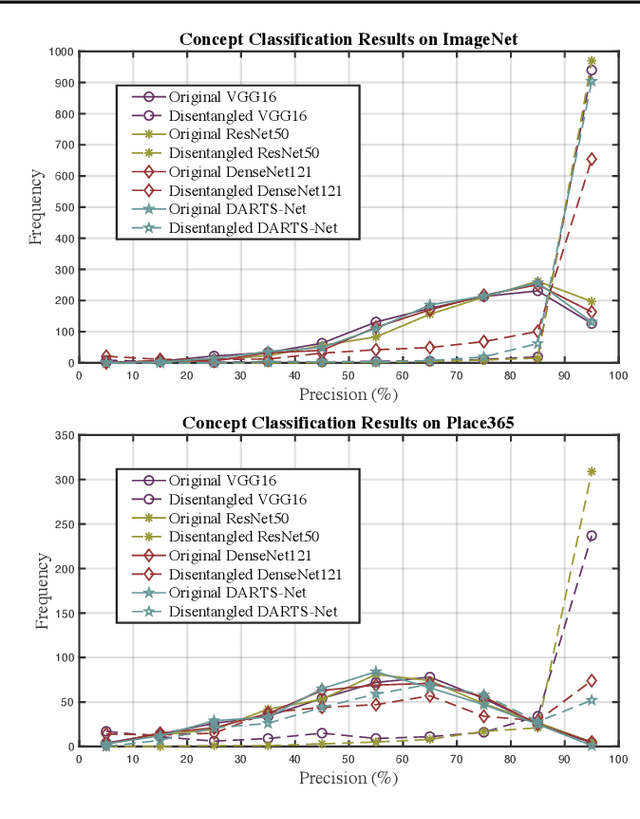
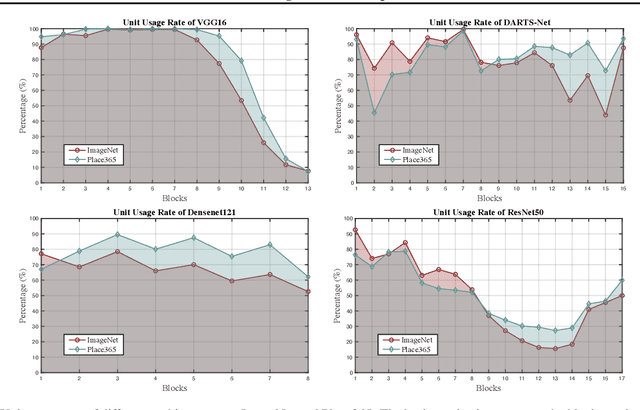
Deep Neural Networks (DNNs) are central to deep learning, and understanding their internal working mechanism is crucial if they are to be used for emerging applications in medical and industrial AI. To this end, the current line of research typically involves linking semantic concepts to a DNN's units or layers. However, this fails to capture the hierarchical inference procedure throughout the network. To address this issue, we introduce the novel concept of Neural Architecture Disentanglement (NAD) in this paper. Specifically, we disentangle a pre-trained network into hierarchical paths corresponding to specific concepts, forming the concept feature paths, i.e., the concept flows from the bottom to top layers of a DNN. Such paths further enable us to quantify the interpretability of DNNs according to the learned diversity of human concepts. We select four types of representative architectures ranging from handcrafted to autoML-based, and conduct extensive experiments on object-based and scene-based datasets. Our NAD sheds important light on the information flow of semantic concepts in DNNs, and provides a fundamental metric that will facilitate the design of interpretable network architectures. Code will be available at: https://github.com/hujiecpp/NAD.
Scoot: A Perceptual Metric for Facial Sketches
Sep 04, 2019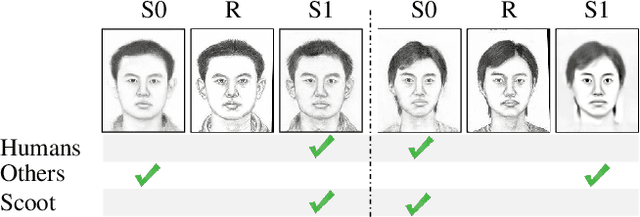

Human visual system has the strong ability to quick assess the perceptual similarity between two facial sketches. However, existing two widely-used facial sketch metrics, e.g., FSIM and SSIM fail to address this perceptual similarity in this field. Recent study in facial modeling area has verified that the inclusion of both structure and texture has a significant positive benefit for face sketch synthesis (FSS). But which statistics are more important, and are helpful for their success? In this paper, we design a perceptual metric,called Structure Co-Occurrence Texture (Scoot), which simultaneously considers the block-level spatial structure and co-occurrence texture statistics. To test the quality of metrics, we propose three novel meta-measures based on various reliable properties. Extensive experiments demonstrate that our Scoot metric exceeds the performance of prior work. Besides, we built the first large scale (152k judgments) human-perception-based sketch database that can evaluate how well a metric is consistent with human perception. Our results suggest that "spatial structure" and "co-occurrence texture" are two generally applicable perceptual features in face sketch synthesis.
Information Competing Process for Learning Diversified Representations
Jun 04, 2019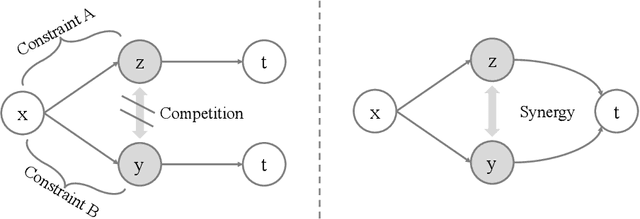



Learning representations with diversified information remains an open problem. Towards learning diversified representations, a new approach, termed Information Competing Process (ICP), is proposed in this paper. Aiming to enrich the information carried by feature representations, ICP separates a representation into two parts with different mutual information constraints. The separated parts are forced to accomplish the downstream task independently in a competitive environment which prevents the two parts from learning what each other learned for the downstream task. Such competing parts are then combined synergistically to complete the task. By fusing representation parts learned competitively under different conditions, ICP facilitates obtaining diversified representations which contain complementary information. Experiments on image classification and image reconstruction tasks demonstrate the great potential of ICP to learn discriminative and disentangled representations in both supervised and self-supervised learning settings.
Face Sketch Synthesis Style Similarity:A New Structure Co-occurrence Texture Measure
Apr 09, 2018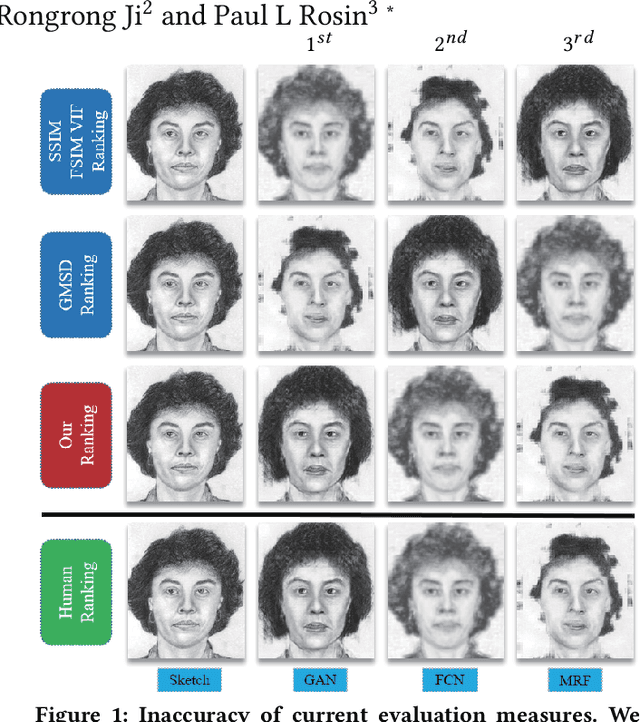
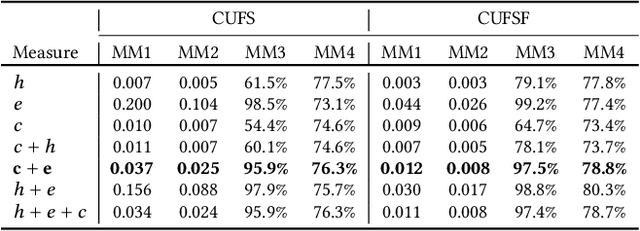
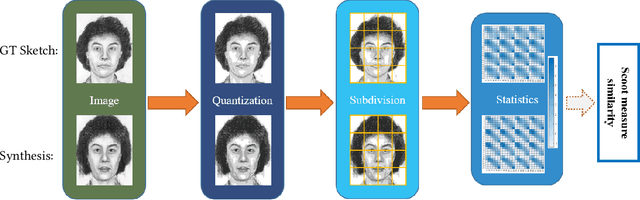
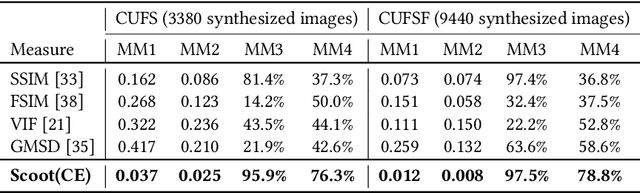
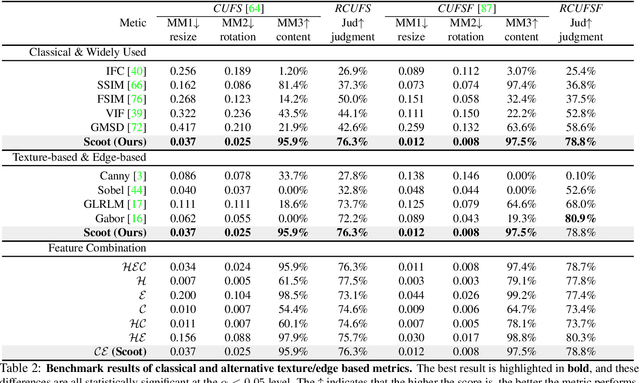
Existing face sketch synthesis (FSS) similarity measures are sensitive to slight image degradation (e.g., noise, blur). However, human perception of the similarity of two sketches will consider both structure and texture as essential factors and is not sensitive to slight ("pixel-level") mismatches. Consequently, the use of existing similarity measures can lead to better algorithms receiving a lower score than worse algorithms. This unreliable evaluation has significantly hindered the development of the FSS field. To solve this problem, we propose a novel and robust style similarity measure called Scoot-measure (Structure CO-Occurrence Texture Measure), which simultaneously evaluates "block-level" spatial structure and co-occurrence texture statistics. In addition, we further propose 4 new meta-measures and create 2 new datasets to perform a comprehensive evaluation of several widely-used FSS measures on two large databases. Experimental results demonstrate that our measure not only provides a reliable evaluation but also achieves significantly improved performance. Specifically, the study indicated a higher degree (78.8%) of correlation between our measure and human judgment than the best prior measure (58.6%). Our code will be made available.