 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Efficient Semantic Segmentation: Learning Offsets for Better Spatial and Class Feature Alignment
Aug 12, 2025Semantic segmentation is fundamental to vision systems requiring pixel-level scene understanding, yet deploying it on resource-constrained devices demands efficient architectures. Although existing methods achieve real-time inference through lightweight designs, we reveal their inherent limitation: misalignment between class representations and image features caused by a per-pixel classification paradigm. With experimental analysis, we find that this paradigm results in a highly challenging assumption for efficient scenarios: Image pixel features should not vary for the same category in different images. To address this dilemma, we propose a coupled dual-branch offset learning paradigm that explicitly learns feature and class offsets to dynamically refine both class representations and spatial image features. Based on the proposed paradigm, we construct an efficient semantic segmentation network, OffSeg. Notably, the offset learning paradigm can be adopted to existing methods with no additional architectural changes. Extensive experiments on four datasets, including ADE20K, Cityscapes, COCO-Stuff-164K, and Pascal Context, demonstrate consistent improvements with negligible parameters. For instance, on the ADE20K dataset, our proposed offset learning paradigm improves SegFormer-B0, SegNeXt-T, and Mask2Former-Tiny by 2.7%, 1.9%, and 2.6% mIoU, respectively, with only 0.1-0.2M additional parameters required.
GAPNet: A Lightweight Framework for Image and Video Salient Object Detection via Granularity-Aware Paradigm
Aug 11, 2025Recent salient object detection (SOD) models predominantly rely on heavyweight backbones, incurring substantial computational cost and hindering their practical application in various real-world settings, particularly on edge devices. This paper presents GAPNet, a lightweight network built on the granularity-aware paradigm for both image and video SOD. We assign saliency maps of different granularities to supervise the multi-scale decoder side-outputs: coarse object locations for high-level outputs and fine-grained object boundaries for low-level outputs. Specifically, our decoder is built with granularity-aware connections which fuse high-level features of low granularity and low-level features of high granularity, respectively. To support these connections, we design granular pyramid convolution (GPC) and cross-scale attention (CSA) modules for efficient fusion of low-scale and high-scale features, respectively. On top of the encoder, a self-attention module is built to learn global information, enabling accurate object localization with negligible computational cost. Unlike traditional U-Net-based approaches, our proposed method optimizes feature utilization and semantic interpretation while applying appropriate supervision at each processing stage. Extensive experiments show that the proposed method achieves a new state-of-the-art performance among lightweight image and video SOD models. Code is available at https://github.com/yuhuan-wu/GAPNet.
Low-Resolution Self-Attention for Semantic Segmentation
Oct 08, 2023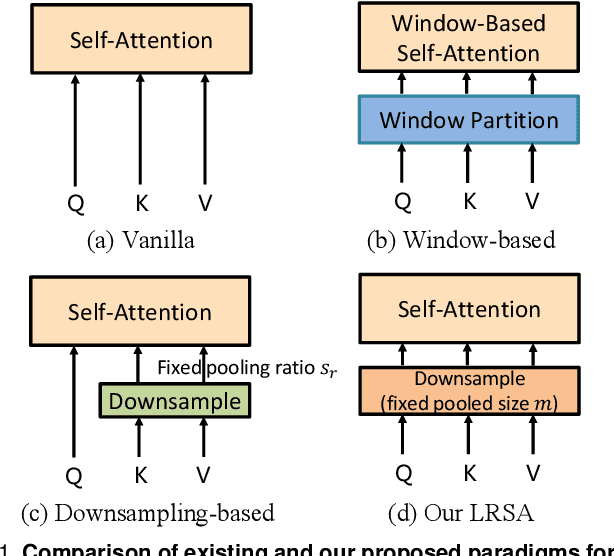
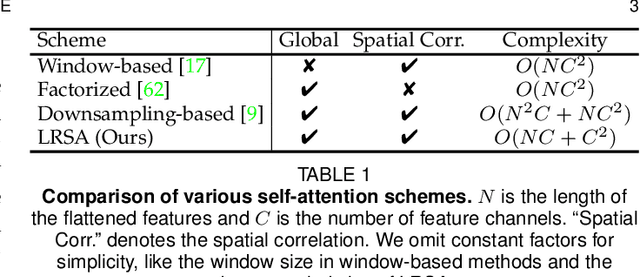
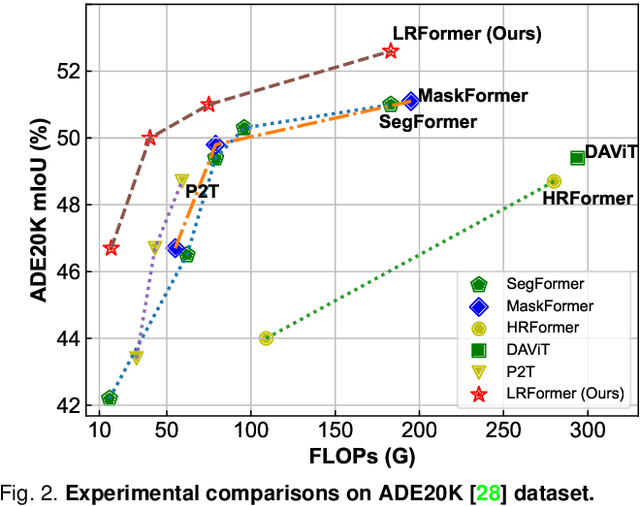

Semantic segmentation tasks naturally require high-resolution information for pixel-wise segmentation and global context information for class prediction. While existing vision transformers demonstrate promising performance, they often utilize high resolution context modeling, resulting in a computational bottleneck. In this work, we challenge conventional wisdom and introduce the Low-Resolution Self-Attention (LRSA) mechanism to capture global context at a significantly reduced computational cost. Our approach involves computing self-attention in a fixed low-resolution space regardless of the input image's resolution, with additional 3x3 depth-wise convolutions to capture fine details in the high-resolution space. We demonstrate the effectiveness of our LRSA approach by building the LRFormer, a vision transformer with an encoder-decoder structure. Extensive experiments on the ADE20K, COCO-Stuff, and Cityscapes datasets demonstrate that LRFormer outperforms state-of-the-art models. The code will be made available at https://github.com/yuhuan-wu/LRFormer.
Revisiting Computer-Aided Tuberculosis Diagnosis
Jul 06, 2023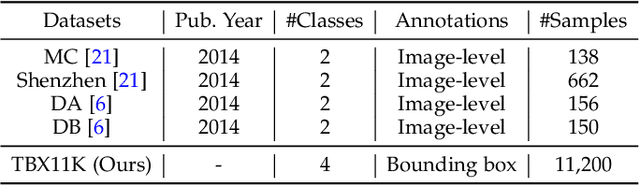
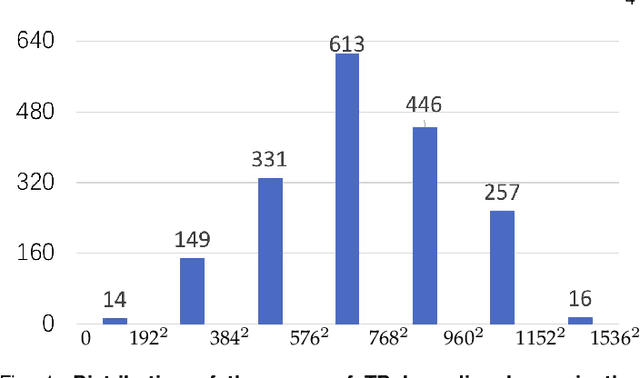
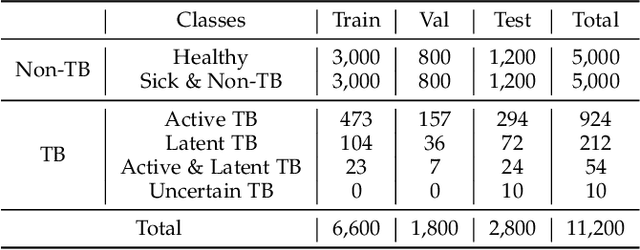
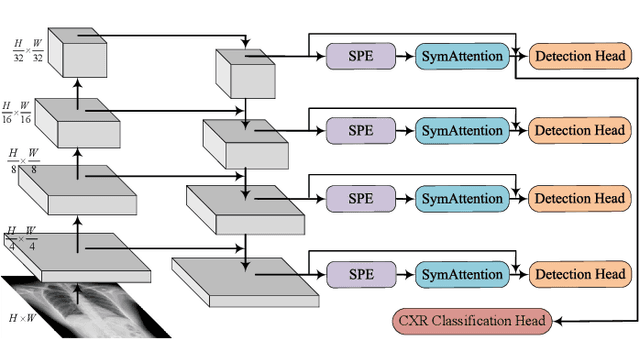
Tuberculosis (TB) is a major global health threat, causing millions of deaths annually. Although early diagnosis and treatment can greatly improve the chances of survival, it remains a major challenge, especially in developing countries. Recently, computer-aided tuberculosis diagnosis (CTD) using deep learning has shown promise, but progress is hindered by limited training data. To address this, we establish a large-scale dataset, namely the Tuberculosis X-ray (TBX11K) dataset, which contains 11,200 chest X-ray (CXR) images with corresponding bounding box annotations for TB areas. This dataset enables the training of sophisticated detectors for high-quality CTD. Furthermore, we propose a strong baseline, SymFormer, for simultaneous CXR image classification and TB infection area detection. SymFormer incorporates Symmetric Search Attention (SymAttention) to tackle the bilateral symmetry property of CXR images for learning discriminative features. Since CXR images may not strictly adhere to the bilateral symmetry property, we also propose Symmetric Positional Encoding (SPE) to facilitate SymAttention through feature recalibration. To promote future research on CTD, we build a benchmark by introducing evaluation metrics, evaluating baseline models reformed from existing detectors, and running an online challenge. Experiments show that SymFormer achieves state-of-the-art performance on the TBX11K dataset. The data, code, and models will be released.
Ret3D: Rethinking Object Relations for Efficient 3D Object Detection in Driving Scenes
Aug 18, 2022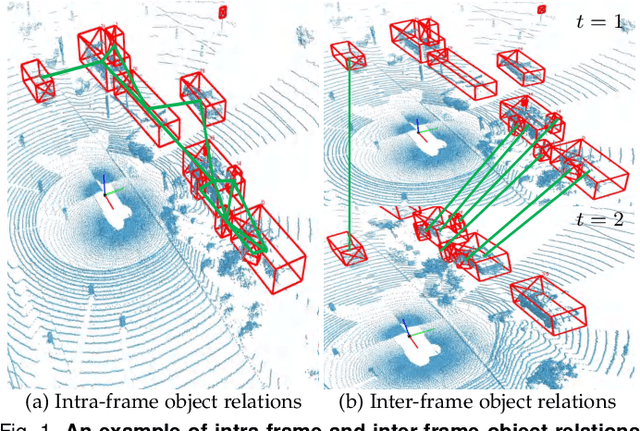
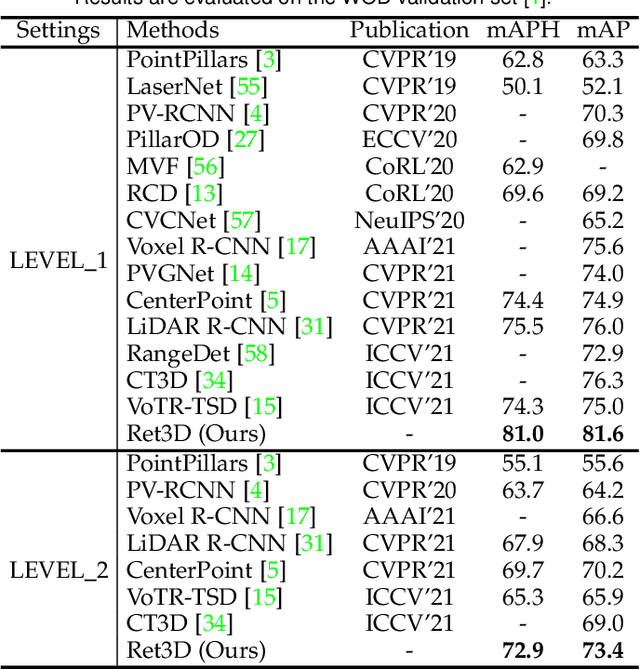
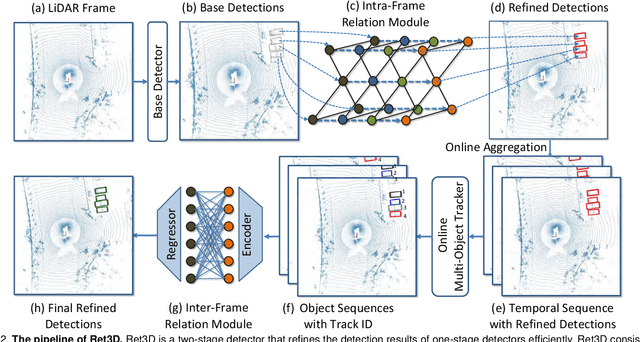
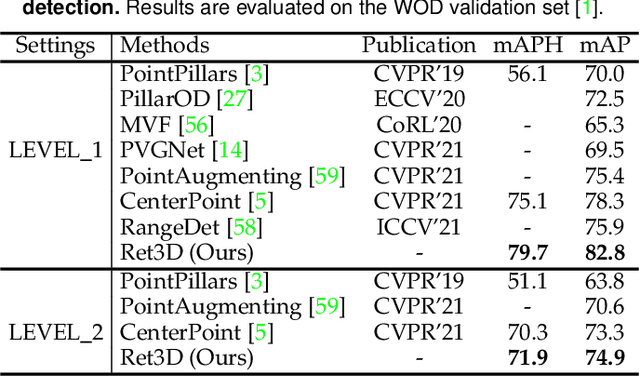
Current efficient LiDAR-based detection frameworks are lacking in exploiting object relations, which naturally present in both spatial and temporal manners. To this end, we introduce a simple, efficient, and effective two-stage detector, termed as Ret3D. At the core of Ret3D is the utilization of novel intra-frame and inter-frame relation modules to capture the spatial and temporal relations accordingly. More Specifically, intra-frame relation module (IntraRM) encapsulates the intra-frame objects into a sparse graph and thus allows us to refine the object features through efficient message passing. On the other hand, inter-frame relation module (InterRM) densely connects each object in its corresponding tracked sequences dynamically, and leverages such temporal information to further enhance its representations efficiently through a lightweight transformer network. We instantiate our novel designs of IntraRM and InterRM with general center-based or anchor-based detectors and evaluate them on Waymo Open Dataset (WOD). With negligible extra overhead, Ret3D achieves the state-of-the-art performance, being 5.5% and 3.2% higher than the recent competitor in terms of the LEVEL 1 and LEVEL 2 mAPH metrics on vehicle detection, respectively.
P2T: Pyramid Pooling Transformer for Scene Understanding
Jul 10, 2021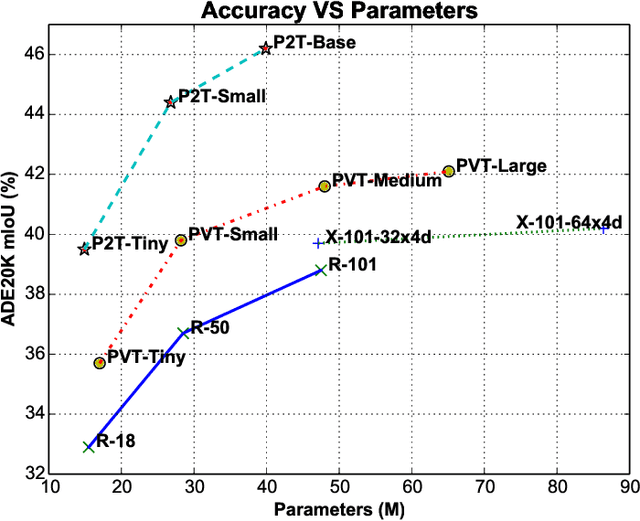
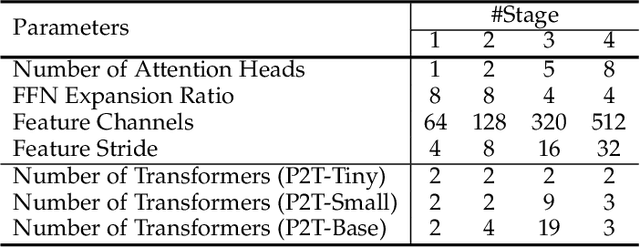
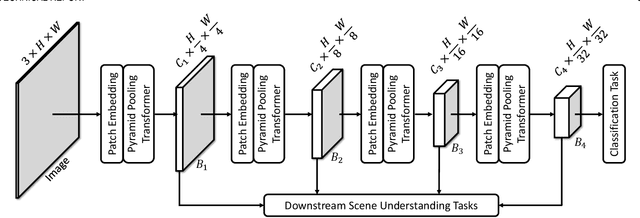
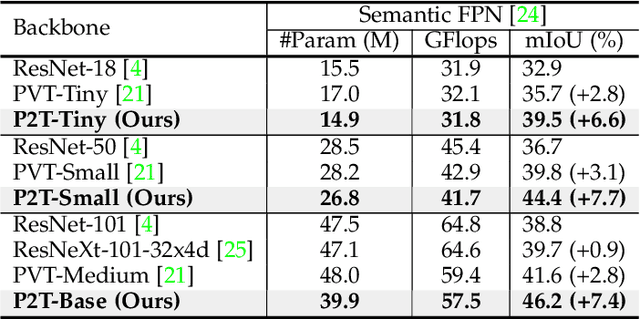
This paper jointly resolves two problems in vision transformer: i) the computation of Multi-Head Self-Attention (MHSA) has high computational/space complexity; ii) recent vision transformer networks are overly tuned for image classification, ignoring the difference between image classification (simple scenarios, more similar to NLP) and downstream scene understanding tasks (complicated scenarios, rich structural and contextual information). To this end, we note that pyramid pooling has been demonstrated to be effective in various vision tasks owing to its powerful ability in context abstraction, and its natural property of spatial invariance is also suitable to address the loss of structural information (problem ii)). Hence, we propose to adapt pyramid pooling to MHSA for alleviating its high requirement on computational resources (problem i)). In this way, this pooling-based MHSA can well address the above two problems and is thus flexible and powerful for downstream scene understanding tasks. Plugged with our pooling-based MHSA, we build a downstream-task-oriented transformer network, dubbed Pyramid Pooling Transformer (P2T). Extensive experiments demonstrate that, when applied P2T as the backbone network, it shows substantial superiority in various downstream scene understanding tasks such as semantic segmentation, object detection, instance segmentation, and visual saliency detection, compared to previous CNN- and transformer-based networks. The code will be released at https://github.com/yuhuan-wu/P2T.
MobileSal: Extremely Efficient RGB-D Salient Object Detection
Dec 24, 2020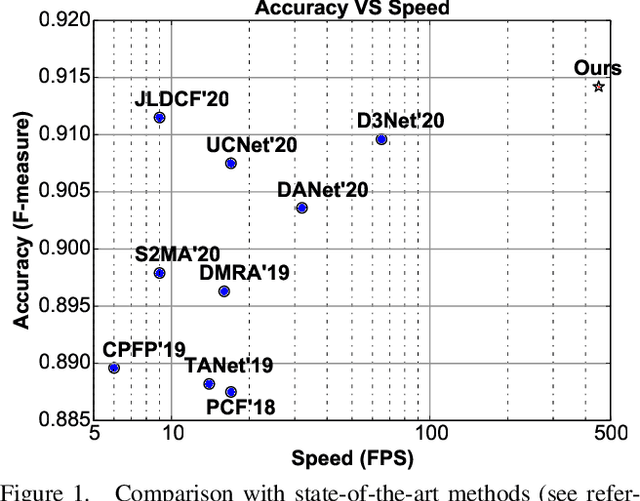
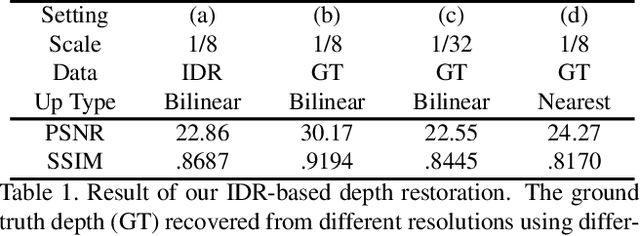
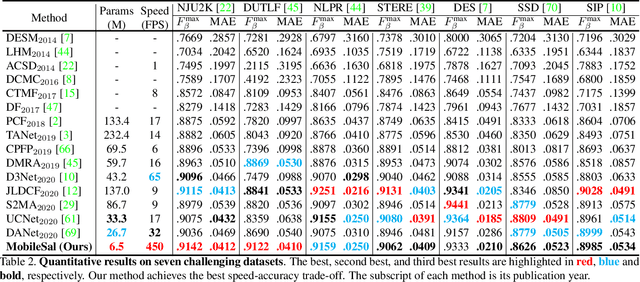
The high computational cost of neural networks has prevented recent successes in RGB-D salient object detection (SOD) from benefiting real-world applications. Hence, this paper introduces a novel network, \methodname, which focuses on efficient RGB-D SOD by using mobile networks for deep feature extraction. The problem is that mobile networks are less powerful in feature representation than cumbersome networks. To this end, we observe that the depth information of color images can strengthen the feature representation related to SOD if leveraged properly. Therefore, we propose an implicit depth restoration (IDR) technique to strengthen the feature representation capability of mobile networks for RGB-D SOD. IDR is only adopted in the training phase and is omitted during testing, so it is computationally free. Besides, we propose compact pyramid refinement (CPR) for efficient multi-level feature aggregation so that we can derive salient objects with clear boundaries. With IDR and CPR incorporated, \methodname~performs favorably against \sArt methods on seven challenging RGB-D SOD datasets with much faster speed (450fps) and fewer parameters (6.5M). The code will be released.
EDN: Salient Object Detection via Extremely-Downsampled Network
Dec 24, 2020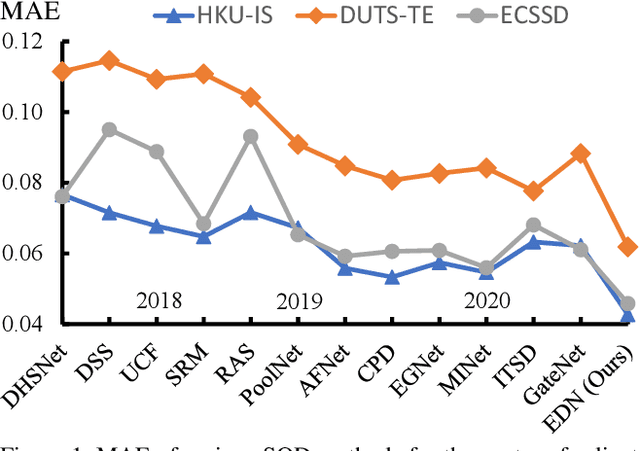
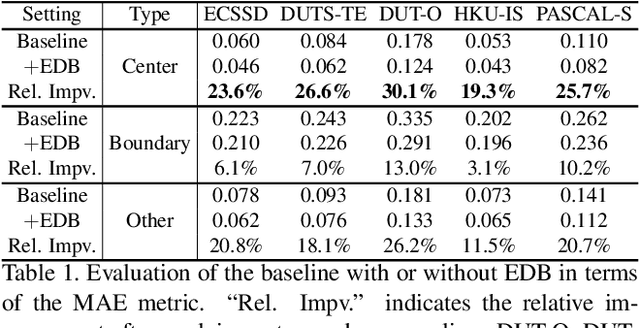
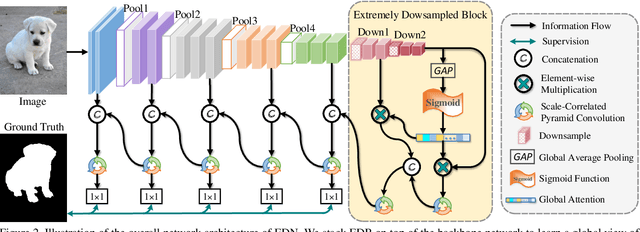
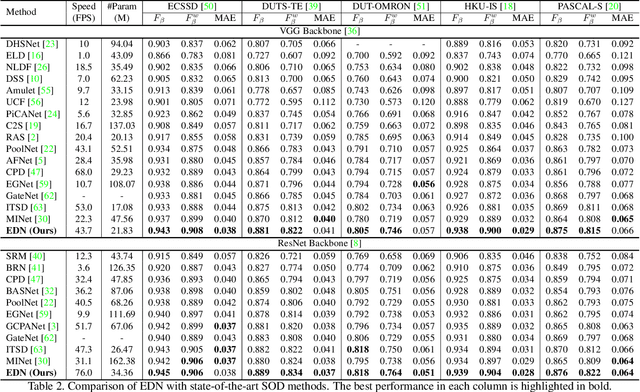
Recent progress on salient object detection (SOD) mainly benefits from multi-scale learning, where the high-level and low-level features work collaboratively in locating salient objects and discovering fine details, respectively. However, most efforts are devoted to low-level feature learning by fusing multi-scale features or enhancing boundary representations. In this paper, we show another direction that improving high-level feature learning is essential for SOD as well. To verify this, we introduce an Extremely-Downsampled Network (EDN), which employs an extreme downsampling technique to effectively learn a global view of the whole image, leading to accurate salient object localization. A novel Scale-Correlated Pyramid Convolution (SCPC) is also designed to build an elegant decoder for recovering object details from the above extreme downsampling. Extensive experiments demonstrate that EDN achieves \sArt performance with real-time speed. Hence, this work is expected to spark some new thinking in SOD. The code will be released.
DOTS: Decoupling Operation and Topology in Differentiable Architecture Search
Oct 02, 2020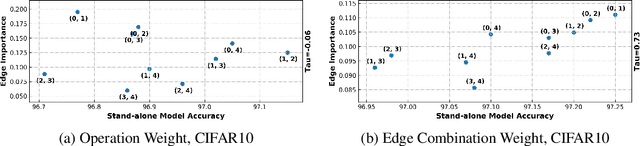
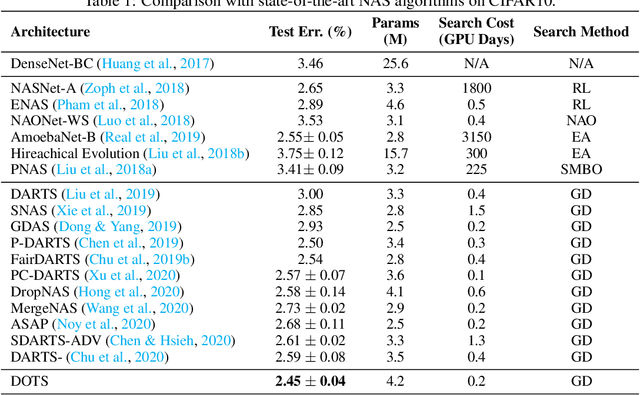
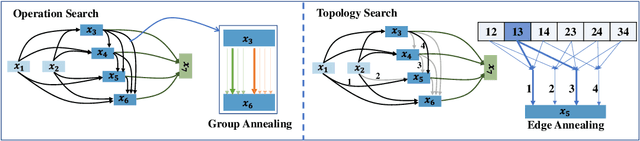
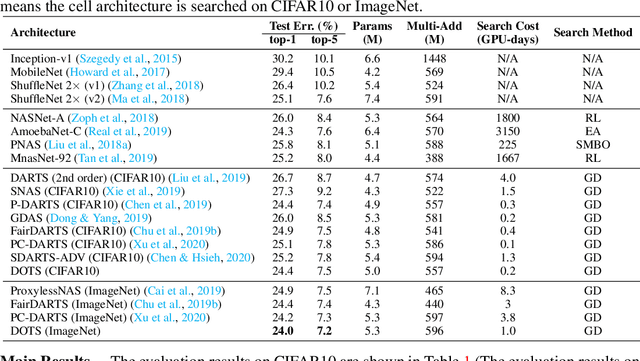
Differentiable Architecture Search (DARTS) has attracted extensive attention due to its efficiency in searching for cell structures. However, DARTS mainly focuses on the operation search, leaving the cell topology implicitly depending on the searched operation weights. Hence, a problem is raised: can cell topology be well represented by the operation weights? The answer is negative because we observe that the operation weights fail to indicate the performance of cell topology. In this paper, we propose to Decouple the Operation and Topology Search (DOTS), which decouples the cell topology representation from the operation weights to make an explicit topology search. DOTS is achieved by defining an additional cell topology search space besides the original operation search space. Within the DOTS framework, we propose group annealing operation search and edge annealing topology search to bridge the optimization gap between the searched over-parameterized network and the derived child network. DOTS is efficient and only costs 0.2 and 1 GPU-day to search the state-of-the-art cell architectures on CIFAR and ImageNet, respectively. By further searching for the topology of DARTS' searched cell, we can improve DARTS' performance significantly. The code will be publicly available.
Regularized Densely-connected Pyramid Network for Salient Instance Segmentation
Aug 28, 2020
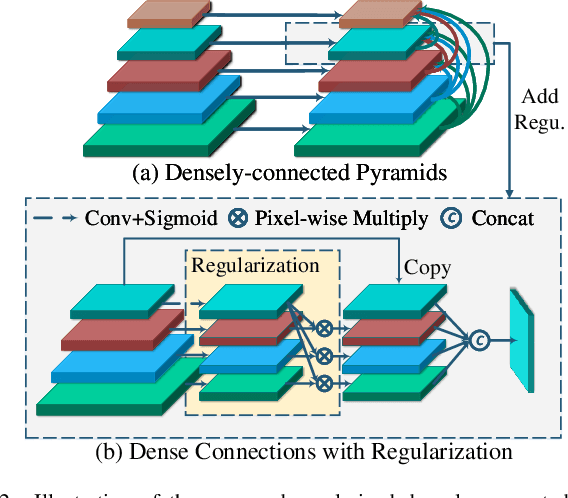
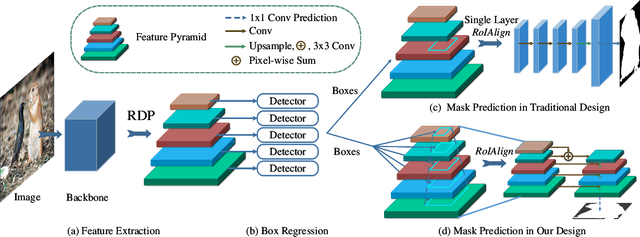
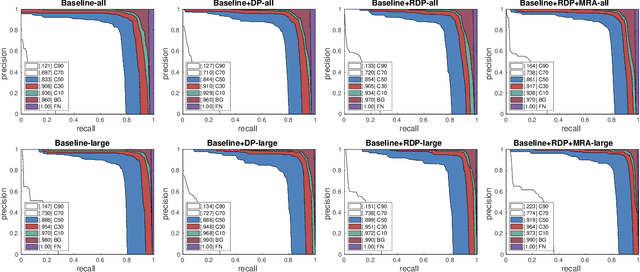
Much of the recent efforts on salient object detection (SOD) has been devoted to producing accurate saliency maps without being aware of their instance labels. To this end, we propose a new pipeline for end-to-end salient instance segmentation (SIS) that predicts a class-agnostic mask for each detected salient instance. To make better use of the rich feature hierarchies in deep networks, we propose the regularized dense connections, which attentively promote informative features and suppress non-informative ones from all feature pyramids, to enhance the side predictions. A novel multi-level RoIAlign based decoder is introduced as well to adaptively aggregate multi-level features for better mask predictions. Such good strategies can be well-encapsulated into the Mask-RCNN pipeline. Extensive experiments on popular benchmarks demonstrate that our design significantly outperforms existing state-of-the-art competitors by 6.3% (58.6% vs 52.3%) in terms of the AP metric. The code is available at https://github.com/yuhuan-wu/RDPNet.