 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgem-RevNet: Deep Reversible Neural Networks with Momentum
Aug 16, 2021



In recent years, the connections between deep residual networks and first-order Ordinary Differential Equations (ODEs) have been disclosed. In this work, we further bridge the deep neural architecture design with the second-order ODEs and propose a novel reversible neural network, termed as m-RevNet, that is characterized by inserting momentum update to residual blocks. The reversible property allows us to perform backward pass without access to activation values of the forward pass, greatly relieving the storage burden during training. Furthermore, the theoretical foundation based on second-order ODEs grants m-RevNet with stronger representational power than vanilla residual networks, which potentially explains its performance gains. For certain learning scenarios, we analytically and empirically reveal that our m-RevNet succeeds while standard ResNet fails. Comprehensive experiments on various image classification and semantic segmentation benchmarks demonstrate the superiority of our m-RevNet over ResNet, concerning both memory efficiency and recognition performance.
Large-scale Unsupervised Semantic Segmentation
Jun 06, 2021

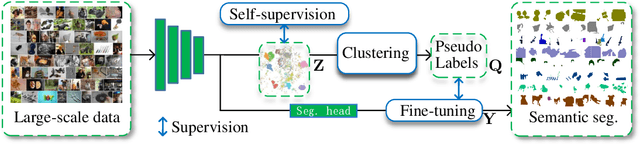
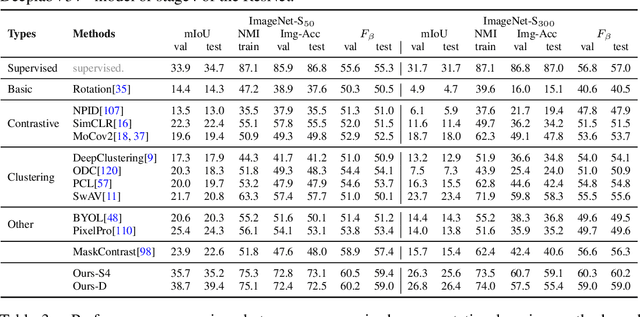
Powered by the ImageNet dataset, unsupervised learning on large-scale data has made significant advances for classification tasks. There are two major challenges to allow such an attractive learning modality for segmentation tasks: i) a large-scale benchmark for assessing algorithms is missing; ii) unsupervised shape representation learning is difficult. We propose a new problem of large-scale unsupervised semantic segmentation (LUSS) with a newly created benchmark dataset to track the research progress. Based on the ImageNet dataset, we propose the ImageNet-S dataset with 1.2 million training images and 40k high-quality semantic segmentation annotations for evaluation. Our benchmark has a high data diversity and a clear task objective. We also present a simple yet effective baseline method that works surprisingly well for LUSS. In addition, we benchmark related un/weakly supervised methods accordingly, identifying the challenges and possible directions of LUSS.
Global2Local: Efficient Structure Search for Video Action Segmentation
Jan 04, 2021

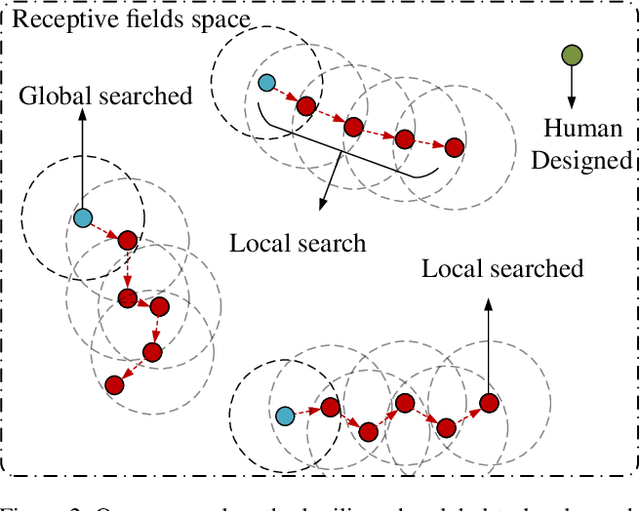

Temporal receptive fields of models play an important role in action segmentation. Large receptive fields facilitate the long-term relations among video clips while small receptive fields help capture the local details. Existing methods construct models with hand-designed receptive fields in layers. Can we effectively search for receptive field combinations to replace hand-designed patterns? To answer this question, we propose to find better receptive field combinations through a global-to-local search scheme. Our search scheme exploits both global search to find the coarse combinations and local search to get the refined receptive field combination patterns further. The global search finds possible coarse combinations other than human-designed patterns. On top of the global search, we propose an expectation guided iterative local search scheme to refine combinations effectively. Our global-to-local search can be plugged into existing action segmentation methods to achieve state-of-the-art performance.
JCS: An Explainable COVID-19 Diagnosis System by Joint Classification and Segmentation
Apr 15, 2020
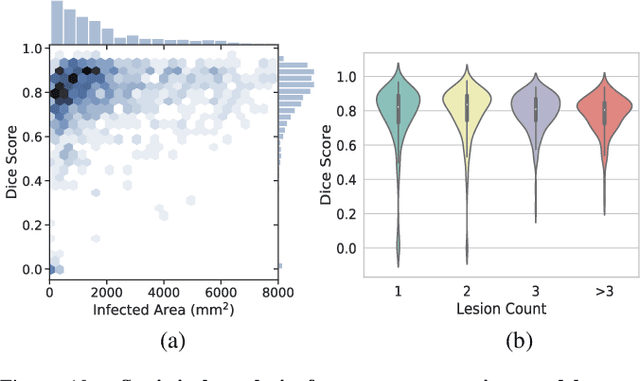
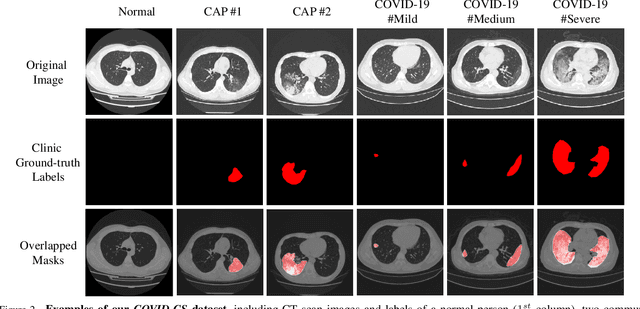

Recently, the novel coronavirus 2019 (COVID-19) has caused a pandemic disease over 200 countries, influencing billions of humans. To control the infection, the first and key step is to identify and separate the infected people. But due to the lack of Reverse Transcription Polymerase Chain Reaction (RT-PCR) tests, it is essential to discover suspected COVID-19 patients via CT scan analysis by radiologists. However, CT scan analysis is usually time-consuming, requiring at least 15 minutes per case. In this paper, we develop a novel Joint Classification and Segmentation (JCS) system to perform real-time and explainable COVID-19 diagnosis. To train our JCS system, we construct a large scale COVID-19 Classification and Segmentation (COVID-CS) dataset, with 144,167 CT images of 400 COVID-19 patients and 350 uninfected cases. 3,855 CT images of 200 patients are annotated with fine-grained pixel-level labels, lesion counts, infected areas and locations, benefiting various diagnosis aspects. Extensive experiments demonstrate that, the proposed JCS diagnosis system is very efficient for COVID-19 classification and segmentation. It obtains an average sensitivity of 95.0% and a specificity of 93.0% on the classification test set, and 78.3% Dice score on the segmentation test set, of our COVID-CS dataset. The online demo of our JCS diagnosis system will be available soon.
Highly Efficient Salient Object Detection with 100K Parameters
Mar 12, 2020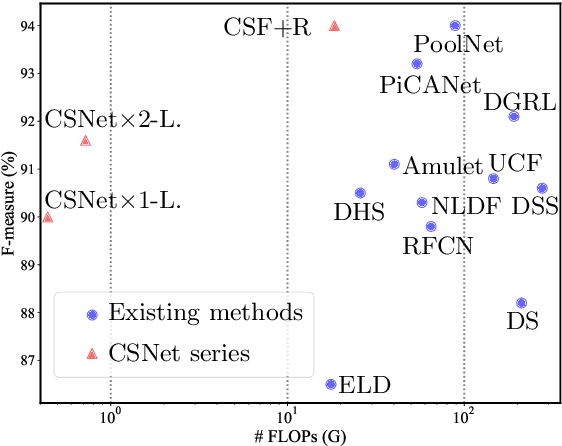
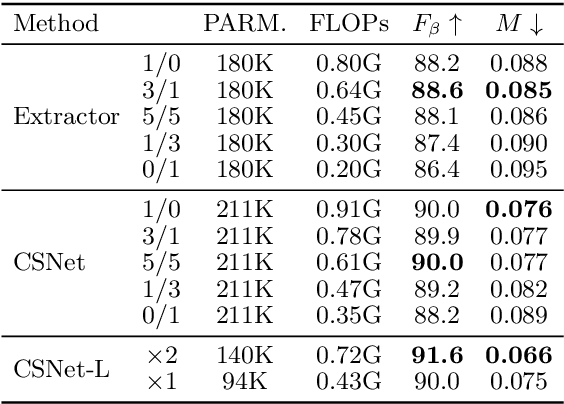
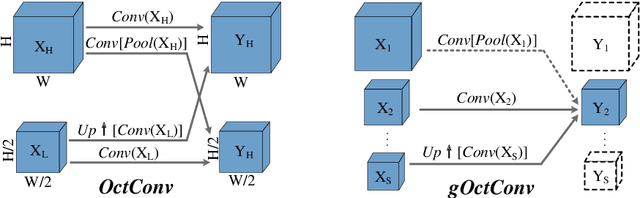
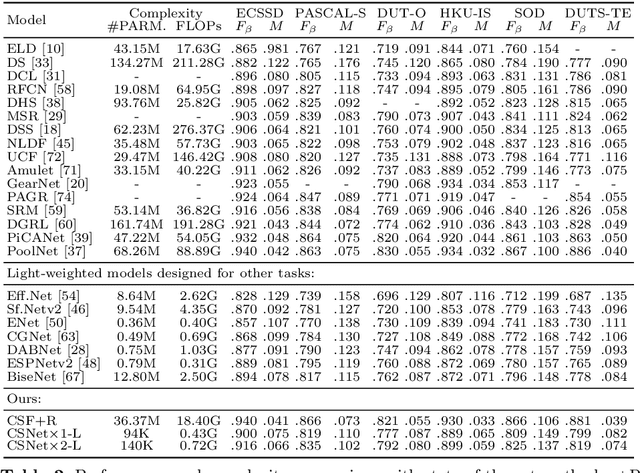
Salient object detection models often demand a considerable amount of computation cost to make precise prediction for each pixel, making them hardly applicable on low-power devices. In this paper, we aim to relieve the contradiction between computation cost and model performance by improving the network efficiency to a higher degree. We propose a flexible convolutional module, namely generalized OctConv (gOctConv), to efficiently utilize both in-stage and cross-stages multi-scale features, while reducing the representation redundancy by a novel dynamic weight decay scheme. The effective dynamic weight decay scheme stably boosts the sparsity of parameters during training, supports learnable number of channels for each scale in gOctConv, allowing 80% of parameters reduce with negligible performance drop. Utilizing gOctConv, we build an extremely light-weighted model, namely CSNet, which achieves comparable performance with about 0.2% parameters (100k) of large models on popular salient object detection benchmarks.
Res2Net: A New Multi-scale Backbone Architecture
Apr 02, 2019
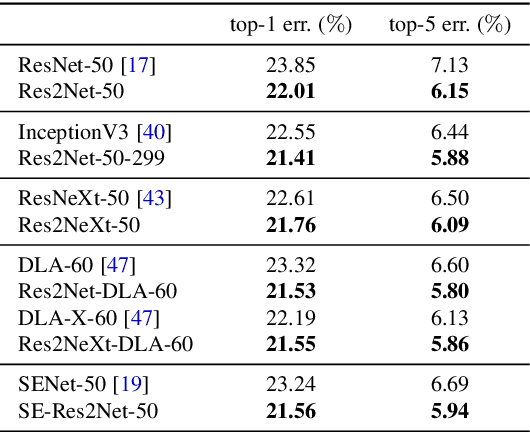
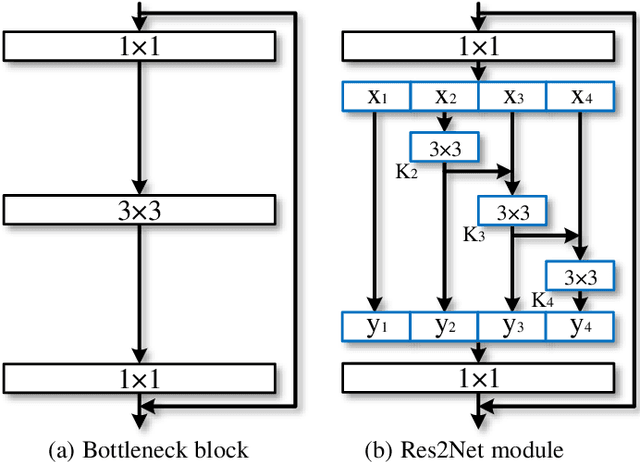
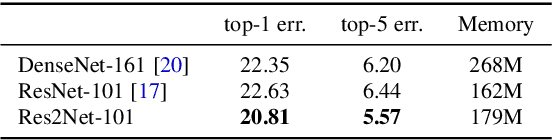
Representing features at multiple scales is of great importance for numerous vision tasks. Recent advances in backbone convolutional neural networks (CNNs) continually demonstrate stronger multi-scale representation ability, leading to consistent performance gains on a wide range of applications. However, most existing methods represent the multi-scale features in a layer-wise manner. In this paper, we propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer. The proposed Res2Net block can be plugged into the state-of-the-art backbone CNN models, e.g., ResNet, ResNeXt, and DLA. We evaluate the Res2Net block on all these models and demonstrate consistent performance gains over baseline models on widely-used datasets, e.g., CIFAR-100 and ImageNet. Further ablation studies and experimental results on representative computer vision tasks, i.e., object detection, class activation mapping, and salient object detection, further verify the superiority of the Res2Net over the state-of-the-art baseline methods. The source code and trained models will be made publicly available.
Salient Objects in Clutter: Bringing Salient Object Detection to the Foreground
Jul 22, 2018
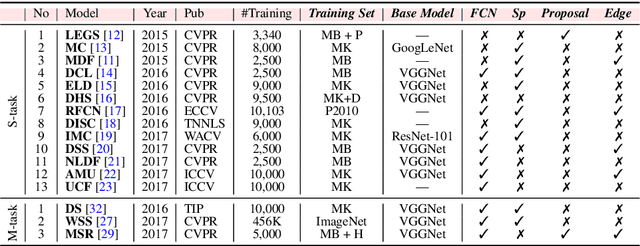


We provide a comprehensive evaluation of salient object detection (SOD) models. Our analysis identifies a serious design bias of existing SOD datasets which assumes that each image contains at least one clearly outstanding salient object in low clutter. The design bias has led to a saturated high performance for state-of-the-art SOD models when evaluated on existing datasets. The models, however, still perform far from being satisfactory when applied to real-world daily scenes. Based on our analyses, we first identify 7 crucial aspects that a comprehensive and balanced dataset should fulfill. Then, we propose a new high quality dataset and update the previous saliency benchmark. Specifically, our SOC (Salient Objects in Clutter) dataset, includes images with salient and non-salient objects from daily object categories. Beyond object category annotations, each salient image is accompanied by attributes that reflect common challenges in real-world scenes. Finally, we report attribute-based performance assessment on our dataset.