 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualCloze: A Universal Image Generation Framework via Visual In-Context Learning
Apr 10, 2025Recent progress in diffusion models significantly advances various image generation tasks. However, the current mainstream approach remains focused on building task-specific models, which have limited efficiency when supporting a wide range of different needs. While universal models attempt to address this limitation, they face critical challenges, including generalizable task instruction, appropriate task distributions, and unified architectural design. To tackle these challenges, we propose VisualCloze, a universal image generation framework, which supports a wide range of in-domain tasks, generalization to unseen ones, unseen unification of multiple tasks, and reverse generation. Unlike existing methods that rely on language-based task instruction, leading to task ambiguity and weak generalization, we integrate visual in-context learning, allowing models to identify tasks from visual demonstrations. Meanwhile, the inherent sparsity of visual task distributions hampers the learning of transferable knowledge across tasks. To this end, we introduce Graph200K, a graph-structured dataset that establishes various interrelated tasks, enhancing task density and transferable knowledge. Furthermore, we uncover that our unified image generation formulation shared a consistent objective with image infilling, enabling us to leverage the strong generative priors of pre-trained infilling models without modifying the architectures.
PR-MIM: Delving Deeper into Partial Reconstruction in Masked Image Modeling
Nov 24, 2024Masked image modeling has achieved great success in learning representations but is limited by the huge computational costs. One cost-saving strategy makes the decoder reconstruct only a subset of masked tokens and throw the others, and we refer to this method as partial reconstruction. However, it also degrades the representation quality. Previous methods mitigate this issue by throwing tokens with minimal information using temporal redundancy inaccessible for static images or attention maps that incur extra costs and complexity. To address these limitations, we propose a progressive reconstruction strategy and a furthest sampling strategy to reconstruct those thrown tokens in an extremely lightweight way instead of completely abandoning them. This approach involves all masked tokens in supervision to ensure adequate pre-training, while maintaining the cost-reduction benefits of partial reconstruction. We validate the effectiveness of the proposed method across various existing frameworks. For example, when throwing 50% patches, we can achieve lossless performance of the ViT-B/16 while saving 28% FLOPs and 36% memory usage compared to standard MAE. Our source code will be made publicly available
Multi-Token Enhancing for Vision Representation Learning
Nov 24, 2024Vision representation learning, especially self-supervised learning, is pivotal for various vision applications. Ensemble learning has also succeeded in enhancing the performance and robustness of the vision models. However, traditional ensemble strategies are impractical for representation learning, especially self-supervised representation learning that requires large-scale datasets and long schedules. This is because they require k times more training and inference computation costs for an ensemble of k models. Differently, we introduce Multi-Token Enhancing (MTE) that extracts multiple auxiliary tokens simultaneously from a single model to enhance representation learning, while incurring minimal additional training costs and no additional inference costs. These auxiliary tokens, including auxiliary CLS tokens and adaptively pooled tokens, capture complementary information due to their differences. Meanwhile, to address the increase in inference costs, we distill the knowledge acquired by the auxiliary tokens into a global token during pre-training. Consequently, we can discard the auxiliary tokens during inference without incurring additional costs. Our MTE is compatible with various self-supervised loss functions and architectures, consistently improving performances across different downstream tasks. Our source code will be made publicly available.
Towards RAW Object Detection in Diverse Conditions
Nov 24, 2024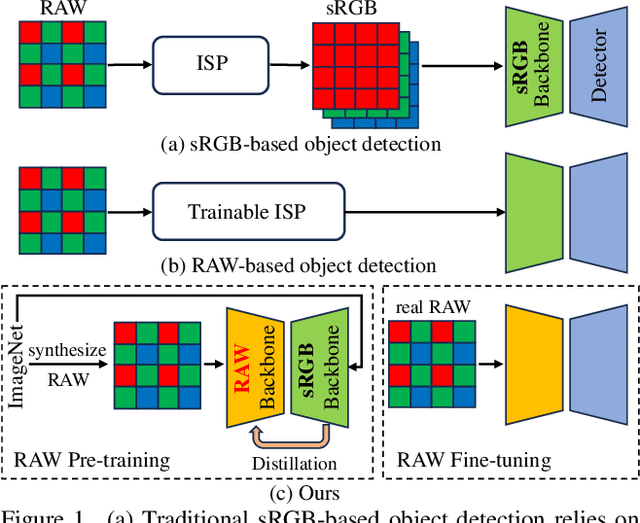



Existing object detection methods often consider sRGB input, which was compressed from RAW data using ISP originally designed for visualization. However, such compression might lose crucial information for detection, especially under complex light and weather conditions. We introduce the AODRaw dataset, which offers 7,785 high-resolution real RAW images with 135,601 annotated instances spanning 62 categories, capturing a broad range of indoor and outdoor scenes under 9 distinct light and weather conditions. Based on AODRaw that supports RAW and sRGB object detection, we provide a comprehensive benchmark for evaluating current detection methods. We find that sRGB pre-training constrains the potential of RAW object detection due to the domain gap between sRGB and RAW, prompting us to directly pre-train on the RAW domain. However, it is harder for RAW pre-training to learn rich representations than sRGB pre-training due to the camera noise. To assist RAW pre-training, we distill the knowledge from an off-the-shelf model pre-trained on the sRGB domain. As a result, we achieve substantial improvements under diverse and adverse conditions without relying on extra pre-processing modules. Code and dataset are available at https://github.com/lzyhha/AODRaw.
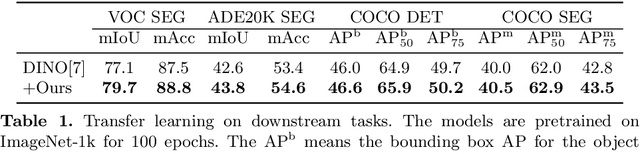
Enhancing Representations through Heterogeneous Self-Supervised Learning
Oct 08, 2023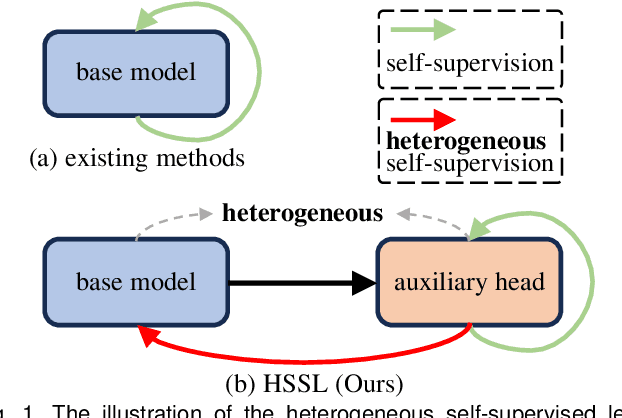

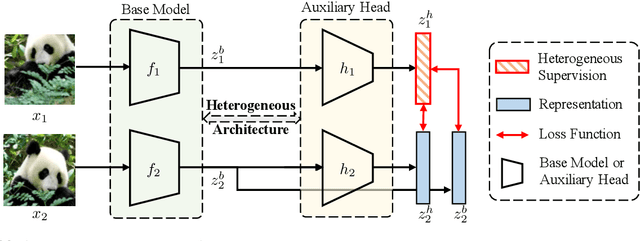

Incorporating heterogeneous representations from different architectures has facilitated various vision tasks, e.g., some hybrid networks combine transformers and convolutions. However, complementarity between such heterogeneous architectures has not been well exploited in self-supervised learning. Thus, we propose Heterogeneous Self-Supervised Learning (HSSL), which enforces a base model to learn from an auxiliary head whose architecture is heterogeneous from the base model. In this process, HSSL endows the base model with new characteristics in a representation learning way without structural changes. To comprehensively understand the HSSL, we conduct experiments on various heterogeneous pairs containing a base model and an auxiliary head. We discover that the representation quality of the base model moves up as their architecture discrepancy grows. This observation motivates us to propose a search strategy that quickly determines the most suitable auxiliary head for a specific base model to learn and several simple but effective methods to enlarge the model discrepancy. The HSSL is compatible with various self-supervised methods, achieving superior performances on various downstream tasks, including image classification, semantic segmentation, instance segmentation, and object detection. Our source code will be made publicly available.
RF-Next: Efficient Receptive Field Search for Convolutional Neural Networks
Jun 15, 2022



Temporal/spatial receptive fields of models play an important role in sequential/spatial tasks. Large receptive fields facilitate long-term relations, while small receptive fields help to capture the local details. Existing methods construct models with hand-designed receptive fields in layers. Can we effectively search for receptive field combinations to replace hand-designed patterns? To answer this question, we propose to find better receptive field combinations through a global-to-local search scheme. Our search scheme exploits both global search to find the coarse combinations and local search to get the refined receptive field combinations further. The global search finds possible coarse combinations other than human-designed patterns. On top of the global search, we propose an expectation-guided iterative local search scheme to refine combinations effectively. Our RF-Next models, plugging receptive field search to various models, boost the performance on many tasks, e.g., temporal action segmentation, object detection, instance segmentation, and speech synthesis. The source code is publicly available on http://mmcheng.net/rfnext.
Exploring Feature Self-relation for Self-supervised Transformer
Jun 10, 2022


Learning representations with self-supervision for convolutional networks (CNN) has proven effective for vision tasks. As an alternative for CNN, vision transformers (ViTs) emerge strong representation ability with the pixel-level self-attention and channel-level feed-forward networks. Recent works reveal that self-supervised learning helps unleash the great potential of ViTs. Still, most works follow self-supervised strategy designed for CNNs, e.g., instance-level discrimination of samples, but they ignore the unique properties of ViTs. We observe that modeling relations among pixels and channels distinguishes ViTs from other networks. To enforce this property, we explore the feature self-relations for training self-supervised ViTs. Specifically, instead of conducting self-supervised learning solely on feature embeddings from multiple views, we utilize the feature self-relations, i.e., pixel/channel-level self-relations, for self-supervised learning. Self-relation based learning further enhance the relation modeling ability of ViTs, resulting in strong representations that stably improve performance on multiple downstream tasks. Our source code will be made publicly available.
Large-scale Unsupervised Semantic Segmentation
Jun 06, 2021

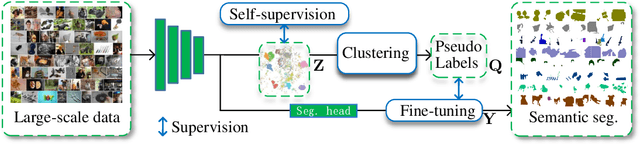
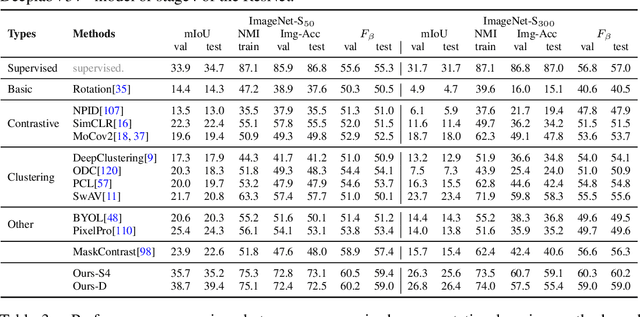
Powered by the ImageNet dataset, unsupervised learning on large-scale data has made significant advances for classification tasks. There are two major challenges to allow such an attractive learning modality for segmentation tasks: i) a large-scale benchmark for assessing algorithms is missing; ii) unsupervised shape representation learning is difficult. We propose a new problem of large-scale unsupervised semantic segmentation (LUSS) with a newly created benchmark dataset to track the research progress. Based on the ImageNet dataset, we propose the ImageNet-S dataset with 1.2 million training images and 40k high-quality semantic segmentation annotations for evaluation. Our benchmark has a high data diversity and a clear task objective. We also present a simple yet effective baseline method that works surprisingly well for LUSS. In addition, we benchmark related un/weakly supervised methods accordingly, identifying the challenges and possible directions of LUSS.
Global2Local: Efficient Structure Search for Video Action Segmentation
Jan 04, 2021

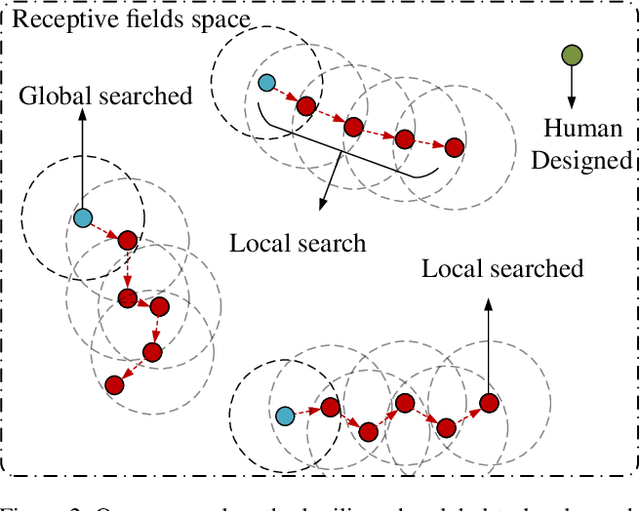

Temporal receptive fields of models play an important role in action segmentation. Large receptive fields facilitate the long-term relations among video clips while small receptive fields help capture the local details. Existing methods construct models with hand-designed receptive fields in layers. Can we effectively search for receptive field combinations to replace hand-designed patterns? To answer this question, we propose to find better receptive field combinations through a global-to-local search scheme. Our search scheme exploits both global search to find the coarse combinations and local search to get the refined receptive field combination patterns further. The global search finds possible coarse combinations other than human-designed patterns. On top of the global search, we propose an expectation guided iterative local search scheme to refine combinations effectively. Our global-to-local search can be plugged into existing action segmentation methods to achieve state-of-the-art performance.