 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Feature Self-relation for Self-supervised Transformer
Paper and Code
Jun 10, 2022
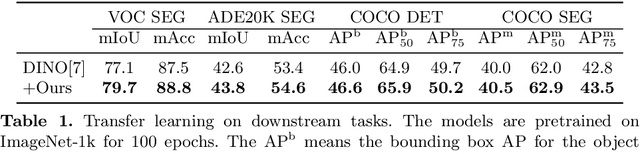


Learning representations with self-supervision for convolutional networks (CNN) has proven effective for vision tasks. As an alternative for CNN, vision transformers (ViTs) emerge strong representation ability with the pixel-level self-attention and channel-level feed-forward networks. Recent works reveal that self-supervised learning helps unleash the great potential of ViTs. Still, most works follow self-supervised strategy designed for CNNs, e.g., instance-level discrimination of samples, but they ignore the unique properties of ViTs. We observe that modeling relations among pixels and channels distinguishes ViTs from other networks. To enforce this property, we explore the feature self-relations for training self-supervised ViTs. Specifically, instead of conducting self-supervised learning solely on feature embeddings from multiple views, we utilize the feature self-relations, i.e., pixel/channel-level self-relations, for self-supervised learning. Self-relation based learning further enhance the relation modeling ability of ViTs, resulting in strong representations that stably improve performance on multiple downstream tasks. Our source code will be made publicly available.