 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
Jun 04, 2026Large language model (LLM) agents are increasingly applied to long-horizon tasks such as scientific discovery and machine learning engineering (MLE), where sustained self-evolution becomes a key capability. However, existing MLE agents suffer from inter-branch information isolation, memoryless search, and lack of hierarchical control, which together hinder long-horizon optimization. We present MLEvolve, an LLM-based self-evolving multi-agent framework for end-to-end machine learning algorithm discovery. By extending tree search to Progressive MCGS, MLEvolve enables cross-branch information flow through graph-based reference edges and gradually shifts the search from broad exploration to focused exploitation with an entropy-inspired progressive schedule. To allow the agent to evolve with accumulated experience, we introduce Retrospective Memory, which combines a cold-start domain knowledge base with a dynamic global memory for task-specific experience retrieval and reuse. For stable long-horizon iteration, we further decouple strategic planning from code generation with adaptive coding modes. Evaluation on MLE-Bench shows that MLEvolve achieves state-of-the-art performance across multiple dimensions including average medal rate and valid submission rate under a 12-hour budget (half the standard runtime). Moreover, MLEvolve also outperforms specialized algorithm discovery methods including AlphaEvolve on mathematical algorithm optimization tasks, demonstrating strong cross-domain generalization. Our code is available at https://github.com/InternScience/MLEvolve.
GeoAgent: Learning to Geolocate Everywhere with Reinforced Geographic Characteristics
Feb 13, 2026This paper presents GeoAgent, a model capable of reasoning closely with humans and deriving fine-grained address conclusions. Previous RL-based methods have achieved breakthroughs in performance and interpretability but still remain concerns because of their reliance on AI-generated chain-of-thought (CoT) data and training strategies, which conflict with geographic characteristics. To address these issues, we first introduce GeoSeek, a new geolocation dataset comprising CoT data annotated by geographic experts and professional players. We further thoroughly explore the inherent characteristics of geographic tasks and propose a geo-similarity reward and a consistency reward assessed by a consistency agent to assist training. This encourages the model to converge towards correct answers from a geographic perspective while ensuring the integrity and consistency of its reasoning process. Experimental results show that GeoAgent outperforms existing methods and a series of general VLLMs across multiple grains, while generating reasoning that closely aligns with humans.
Depth Anything at Any Condition
Jul 02, 2025We present Depth Anything at Any Condition (DepthAnything-AC), a foundation monocular depth estimation (MDE) model capable of handling diverse environmental conditions. Previous foundation MDE models achieve impressive performance across general scenes but not perform well in complex open-world environments that involve challenging conditions, such as illumination variations, adverse weather, and sensor-induced distortions. To overcome the challenges of data scarcity and the inability of generating high-quality pseudo-labels from corrupted images, we propose an unsupervised consistency regularization finetuning paradigm that requires only a relatively small amount of unlabeled data. Furthermore, we propose the Spatial Distance Constraint to explicitly enforce the model to learn patch-level relative relationships, resulting in clearer semantic boundaries and more accurate details. Experimental results demonstrate the zero-shot capabilities of DepthAnything-AC across diverse benchmarks, including real-world adverse weather benchmarks, synthetic corruption benchmarks, and general benchmarks. Project Page: https://ghost233lism.github.io/depthanything-AC-page Code: https://github.com/HVision-NKU/DepthAnythingAC
HumanOmni: A Large Vision-Speech Language Model for Human-Centric Video Understanding
Jan 25, 2025



In human-centric scenes, the ability to simultaneously understand visual and auditory information is crucial. While recent omni models can process multiple modalities, they generally lack effectiveness in human-centric scenes due to the absence of large-scale, specialized datasets and non-targeted architectures. In this work, we developed HumanOmni, the industry's first human-centric Omni-multimodal large language model. We constructed a dataset containing over 2.4 million human-centric video clips with detailed captions and more than 14 million instructions, facilitating the understanding of diverse human-centric scenes. HumanOmni includes three specialized branches for understanding different types of scenes. It adaptively fuses features from these branches based on user instructions, significantly enhancing visual understanding in scenes centered around individuals. Moreover, HumanOmni integrates audio features to ensure a comprehensive understanding of environments and individuals. Our experiments validate HumanOmni's advanced capabilities in handling human-centric scenes across a variety of tasks, including emotion recognition, facial expression description, and action understanding. Our model will be open-sourced to facilitate further development and collaboration within both academia and industry.
Facial Dynamics in Video: Instruction Tuning for Improved Facial Expression Perception and Contextual Awareness
Jan 14, 2025



Facial expression captioning has found widespread application across various domains. Recently, the emergence of video Multimodal Large Language Models (MLLMs) has shown promise in general video understanding tasks. However, describing facial expressions within videos poses two major challenges for these models: (1) the lack of adequate datasets and benchmarks, and (2) the limited visual token capacity of video MLLMs. To address these issues, this paper introduces a new instruction-following dataset tailored for dynamic facial expression caption. The dataset comprises 5,033 high-quality video clips annotated manually, containing over 700,000 tokens. Its purpose is to improve the capability of video MLLMs to discern subtle facial nuances. Furthermore, we propose FaceTrack-MM, which leverages a limited number of tokens to encode the main character's face. This model demonstrates superior performance in tracking faces and focusing on the facial expressions of the main characters, even in intricate multi-person scenarios. Additionally, we introduce a novel evaluation metric combining event extraction, relation classification, and the longest common subsequence (LCS) algorithm to assess the content consistency and temporal sequence consistency of generated text. Moreover, we present FEC-Bench, a benchmark designed to assess the performance of existing video MLLMs in this specific task. All data and source code will be made publicly available.
LLaVA-Octopus: Unlocking Instruction-Driven Adaptive Projector Fusion for Video Understanding
Jan 09, 2025



In this paper, we introduce LLaVA-Octopus, a novel video multimodal large language model. LLaVA-Octopus adaptively weights features from different visual projectors based on user instructions, enabling us to leverage the complementary strengths of each projector. We observe that different visual projectors exhibit distinct characteristics when handling specific tasks. For instance, some projectors excel at capturing static details, while others are more effective at processing temporal information, and some are better suited for tasks requiring temporal coherence. By dynamically adjusting feature weights according to user instructions, LLaVA-Octopus dynamically selects and combines the most suitable features, significantly enhancing the model's performance in multimodal tasks. Experimental results demonstrate that LLaVA-Octopus achieves excellent performance across multiple benchmarks, especially in tasks such as multimodal understanding, visual question answering, and video understanding, highlighting its broad application potential.
Towards RAW Object Detection in Diverse Conditions
Nov 24, 2024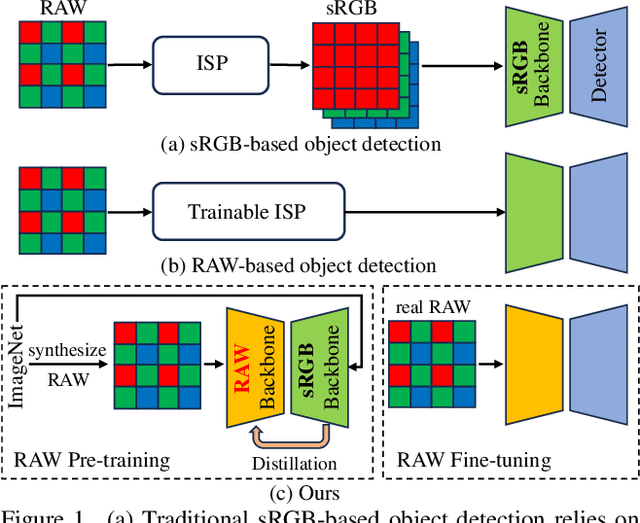



Existing object detection methods often consider sRGB input, which was compressed from RAW data using ISP originally designed for visualization. However, such compression might lose crucial information for detection, especially under complex light and weather conditions. We introduce the AODRaw dataset, which offers 7,785 high-resolution real RAW images with 135,601 annotated instances spanning 62 categories, capturing a broad range of indoor and outdoor scenes under 9 distinct light and weather conditions. Based on AODRaw that supports RAW and sRGB object detection, we provide a comprehensive benchmark for evaluating current detection methods. We find that sRGB pre-training constrains the potential of RAW object detection due to the domain gap between sRGB and RAW, prompting us to directly pre-train on the RAW domain. However, it is harder for RAW pre-training to learn rich representations than sRGB pre-training due to the camera noise. To assist RAW pre-training, we distill the knowledge from an off-the-shelf model pre-trained on the sRGB domain. As a result, we achieve substantial improvements under diverse and adverse conditions without relying on extra pre-processing modules. Code and dataset are available at https://github.com/lzyhha/AODRaw.
CorrMatch: Label Propagation via Correlation Matching for Semi-Supervised Semantic Segmentation
Jun 14, 2023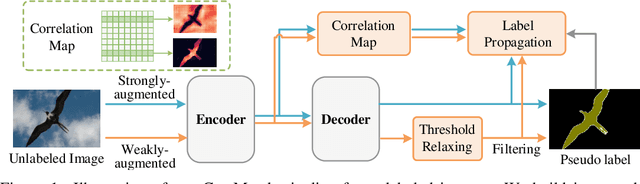
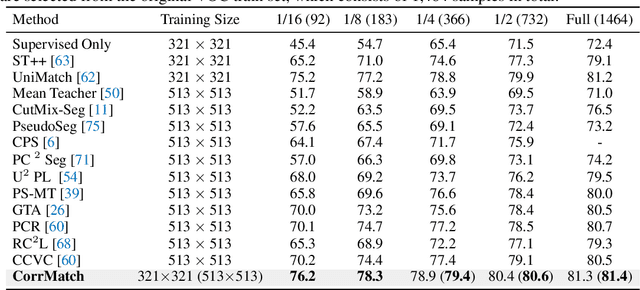


In this paper, we present a simple but performant semi-supervised semantic segmentation approach, termed CorrMatch. Our goal is to mine more high-quality regions from the unlabeled images to leverage the unlabeled data more efficiently via consistency regularization. The key contributions of our CorrMatch are two novel and complementary strategies. First, we introduce an adaptive threshold updating strategy with a relaxed initialization to expand the high-quality regions. Furthermore, we propose to propagate high-confidence predictions through measuring the pairwise similarities between pixels. Despite its simplicity, we show that CorrMatch achieves great performance on popular semi-supervised semantic segmentation benchmarks. Taking the DeepLabV3+ framework with ResNet-101 backbone as our segmentation model, we receive a 76%+ mIoU score on the Pascal VOC 2012 segmentation benchmark with only 92 annotated images provided. We also achieve a consistent improvement over previous semi-supervised semantic segmentation models. Code will be made publicly available.