 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaGen: Self-Evolving Roles and Topologies for Multi-Agent LLM Reasoning
Jan 27, 2026Large language models are increasingly deployed as multi-agent systems, where specialized roles communicate and collaborate through structured interactions to solve complex tasks that often exceed the capacity of a single agent. However, most existing systems still rely on a fixed role library and an execution-frozen interaction topology, a rigid design choice that frequently leads to task mismatch, prevents timely adaptation when new evidence emerges during reasoning, and further inflates inference cost. We introduce MetaGen, a training-free framework that adapts both the role space and the collaboration topology at inference time, without updating base model weights. MetaGen generates and rewrites query-conditioned role specifications to maintain a controllable dynamic role pool, then instantiates a constrained execution graph around a minimal backbone. During execution, it iteratively updates role prompts and adjusts structural decisions using lightweight feedback signals. Experiments on code generation and multi-step reasoning benchmarks show that MetaGen improves the accuracy and cost tradeoff over strong multi-agent baselines.
Connecting the Dots: A Chain-of-Collaboration Prompting Framework for LLM Agents
May 16, 2025Large Language Models (LLMs) have demonstrated impressive performance in executing complex reasoning tasks. Chain-of-thought effectively enhances reasoning capabilities by unlocking the potential of large models, while multi-agent systems provide more comprehensive solutions by integrating collective intelligence of multiple agents. However, both approaches face significant limitations. Single-agent with chain-of-thought, due to the inherent complexity of designing cross-domain prompts, faces collaboration challenges. Meanwhile, multi-agent systems consume substantial tokens and inevitably dilute the primary problem, which is particularly problematic in business workflow tasks. To address these challenges, we propose Cochain, a collaboration prompting framework that effectively solves business workflow collaboration problem by combining knowledge and prompts at a reduced cost. Specifically, we construct an integrated knowledge graph that incorporates knowledge from multiple stages. Furthermore, by maintaining and retrieving a prompts tree, we can obtain prompt information relevant to other stages of the business workflow. We perform extensive evaluations of Cochain across multiple datasets, demonstrating that Cochain outperforms all baselines in both prompt engineering and multi-agent LLMs. Additionally, expert evaluation results indicate that the use of a small model in combination with Cochain outperforms GPT-4.
R1-Omni: Explainable Omni-Multimodal Emotion Recognition with Reinforcing Learning
Mar 07, 2025
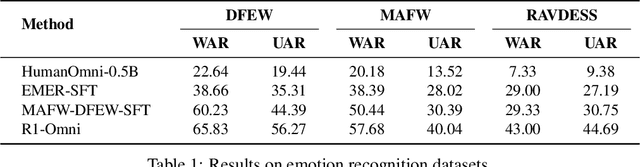


In this work, we present the first application of Reinforcement Learning with Verifiable Reward (RLVR) to an Omni-multimodal large language model in the context of emotion recognition, a task where both visual and audio modalities play crucial roles. We leverage RLVR to optimize the Omni model, significantly enhancing its performance in three key aspects: reasoning capability, emotion recognition accuracy, and generalization ability. The introduction of RLVR not only improves the model's overall performance on in-distribution data but also demonstrates superior robustness when evaluated on out-of-distribution datasets. More importantly, the improved reasoning capability enables clear analysis of the contributions of different modalities, particularly visual and audio information, in the emotion recognition process. This provides valuable insights into the optimization of multimodal large language models.
HumanOmni: A Large Vision-Speech Language Model for Human-Centric Video Understanding
Jan 25, 2025



In human-centric scenes, the ability to simultaneously understand visual and auditory information is crucial. While recent omni models can process multiple modalities, they generally lack effectiveness in human-centric scenes due to the absence of large-scale, specialized datasets and non-targeted architectures. In this work, we developed HumanOmni, the industry's first human-centric Omni-multimodal large language model. We constructed a dataset containing over 2.4 million human-centric video clips with detailed captions and more than 14 million instructions, facilitating the understanding of diverse human-centric scenes. HumanOmni includes three specialized branches for understanding different types of scenes. It adaptively fuses features from these branches based on user instructions, significantly enhancing visual understanding in scenes centered around individuals. Moreover, HumanOmni integrates audio features to ensure a comprehensive understanding of environments and individuals. Our experiments validate HumanOmni's advanced capabilities in handling human-centric scenes across a variety of tasks, including emotion recognition, facial expression description, and action understanding. Our model will be open-sourced to facilitate further development and collaboration within both academia and industry.
Facial Dynamics in Video: Instruction Tuning for Improved Facial Expression Perception and Contextual Awareness
Jan 14, 2025



Facial expression captioning has found widespread application across various domains. Recently, the emergence of video Multimodal Large Language Models (MLLMs) has shown promise in general video understanding tasks. However, describing facial expressions within videos poses two major challenges for these models: (1) the lack of adequate datasets and benchmarks, and (2) the limited visual token capacity of video MLLMs. To address these issues, this paper introduces a new instruction-following dataset tailored for dynamic facial expression caption. The dataset comprises 5,033 high-quality video clips annotated manually, containing over 700,000 tokens. Its purpose is to improve the capability of video MLLMs to discern subtle facial nuances. Furthermore, we propose FaceTrack-MM, which leverages a limited number of tokens to encode the main character's face. This model demonstrates superior performance in tracking faces and focusing on the facial expressions of the main characters, even in intricate multi-person scenarios. Additionally, we introduce a novel evaluation metric combining event extraction, relation classification, and the longest common subsequence (LCS) algorithm to assess the content consistency and temporal sequence consistency of generated text. Moreover, we present FEC-Bench, a benchmark designed to assess the performance of existing video MLLMs in this specific task. All data and source code will be made publicly available.
LLaVA-Octopus: Unlocking Instruction-Driven Adaptive Projector Fusion for Video Understanding
Jan 09, 2025



In this paper, we introduce LLaVA-Octopus, a novel video multimodal large language model. LLaVA-Octopus adaptively weights features from different visual projectors based on user instructions, enabling us to leverage the complementary strengths of each projector. We observe that different visual projectors exhibit distinct characteristics when handling specific tasks. For instance, some projectors excel at capturing static details, while others are more effective at processing temporal information, and some are better suited for tasks requiring temporal coherence. By dynamically adjusting feature weights according to user instructions, LLaVA-Octopus dynamically selects and combines the most suitable features, significantly enhancing the model's performance in multimodal tasks. Experimental results demonstrate that LLaVA-Octopus achieves excellent performance across multiple benchmarks, especially in tasks such as multimodal understanding, visual question answering, and video understanding, highlighting its broad application potential.
D-Aug: Enhancing Data Augmentation for Dynamic LiDAR Scenes
Apr 17, 2024Creating large LiDAR datasets with pixel-level labeling poses significant challenges. While numerous data augmentation methods have been developed to reduce the reliance on manual labeling, these methods predominantly focus on static scenes and they overlook the importance of data augmentation for dynamic scenes, which is critical for autonomous driving. To address this issue, we propose D-Aug, a LiDAR data augmentation method tailored for augmenting dynamic scenes. D-Aug extracts objects and inserts them into dynamic scenes, considering the continuity of these objects across consecutive frames. For seamless insertion into dynamic scenes, we propose a reference-guided method that involves dynamic collision detection and rotation alignment. Additionally, we present a pixel-level road identification strategy to efficiently determine suitable insertion positions. We validated our method using the nuScenes dataset with various 3D detection and tracking methods. Comparative experiments demonstrate the superiority of D-Aug.
FLIC: Fast Linear Iterative Clustering with Active Search
Oct 05, 2018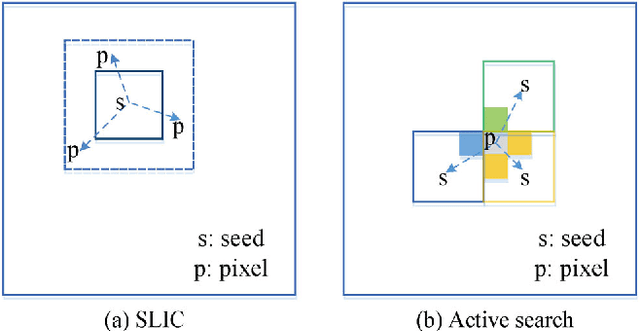



Benefiting from its high efficiency and simplicity, Simple Linear Iterative Clustering (SLIC) remains one of the most popular over-segmentation tools. However, due to explicit enforcement of spatial similarity for region continuity, the boundary adaptation of SLIC is sub-optimal. It also has drawbacks on convergence rate as a result of both the fixed search region and separately doing the assignment step and the update step. In this paper, we propose an alternative approach to fix the inherent limitations of SLIC. In our approach, each pixel actively searches its corresponding segment under the help of its neighboring pixels, which naturally enables region coherence without being harmful to boundary adaptation. We also jointly perform the assignment and update steps, allowing high convergence rate. Extensive evaluations on Berkeley segmentation benchmark verify that our method outperforms competitive methods under various evaluation metrics. It also has the lowest time cost among existing methods (approximately 30fps for a 481x321 image on a single CPU core).