 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeLoRA: Enabling Training-Free LoRA Fusion for Autoregressive Multi-Subject Personalization
Jul 02, 2025Subject-driven image generation plays a crucial role in applications such as virtual try-on and poster design. Existing approaches typically fine-tune pretrained generative models or apply LoRA-based adaptations for individual subjects. However, these methods struggle with multi-subject personalization, as combining independently adapted modules often requires complex re-tuning or joint optimization. We present FreeLoRA, a simple and generalizable framework that enables training-free fusion of subject-specific LoRA modules for multi-subject personalization. Each LoRA module is adapted on a few images of a specific subject using a Full Token Tuning strategy, where it is applied across all tokens in the prompt to encourage weakly supervised token-content alignment. At inference, we adopt Subject-Aware Inference, activating each module only on its corresponding subject tokens. This enables training-free fusion of multiple personalized subjects within a single image, while mitigating overfitting and mutual interference between subjects. Extensive experiments show that FreeLoRA achieves strong performance in both subject fidelity and prompt consistency.
Rethinking Discrete Tokens: Treating Them as Conditions for Continuous Autoregressive Image Synthesis
Jul 02, 2025Recent advances in large language models (LLMs) have spurred interests in encoding images as discrete tokens and leveraging autoregressive (AR) frameworks for visual generation. However, the quantization process in AR-based visual generation models inherently introduces information loss that degrades image fidelity. To mitigate this limitation, recent studies have explored to autoregressively predict continuous tokens. Unlike discrete tokens that reside in a structured and bounded space, continuous representations exist in an unbounded, high-dimensional space, making density estimation more challenging and increasing the risk of generating out-of-distribution artifacts. Based on the above findings, this work introduces DisCon (Discrete-Conditioned Continuous Autoregressive Model), a novel framework that reinterprets discrete tokens as conditional signals rather than generation targets. By modeling the conditional probability of continuous representations conditioned on discrete tokens, DisCon circumvents the optimization challenges of continuous token modeling while avoiding the information loss caused by quantization. DisCon achieves a gFID score of 1.38 on ImageNet 256$\times$256 generation, outperforming state-of-the-art autoregressive approaches by a clear margin.
SuperNeRF-GAN: A Universal 3D-Consistent Super-Resolution Framework for Efficient and Enhanced 3D-Aware Image Synthesis
Jan 12, 2025



Neural volume rendering techniques, such as NeRF, have revolutionized 3D-aware image synthesis by enabling the generation of images of a single scene or object from various camera poses. However, the high computational cost of NeRF presents challenges for synthesizing high-resolution (HR) images. Most existing methods address this issue by leveraging 2D super-resolution, which compromise 3D-consistency. Other methods propose radiance manifolds or two-stage generation to achieve 3D-consistent HR synthesis, yet they are limited to specific synthesis tasks, reducing their universality. To tackle these challenges, we propose SuperNeRF-GAN, a universal framework for 3D-consistent super-resolution. A key highlight of SuperNeRF-GAN is its seamless integration with NeRF-based 3D-aware image synthesis methods and it can simultaneously enhance the resolution of generated images while preserving 3D-consistency and reducing computational cost. Specifically, given a pre-trained generator capable of producing a NeRF representation such as tri-plane, we first perform volume rendering to obtain a low-resolution image with corresponding depth and normal map. Then, we employ a NeRF Super-Resolution module which learns a network to obtain a high-resolution NeRF. Next, we propose a novel Depth-Guided Rendering process which contains three simple yet effective steps, including the construction of a boundary-correct multi-depth map through depth aggregation, a normal-guided depth super-resolution and a depth-guided NeRF rendering. Experimental results demonstrate the superior efficiency, 3D-consistency, and quality of our approach. Additionally, ablation studies confirm the effectiveness of our proposed components.
Solution for OOD-CV Workshop SSB Challenge 2024 (Open-Set Recognition Track)
Sep 30, 2024



This report provides a detailed description of the method we explored and proposed in the OSR Challenge at the OOD-CV Workshop during ECCV 2024. The challenge required identifying whether a test sample belonged to the semantic classes of a classifier's training set, a task known as open-set recognition (OSR). Using the Semantic Shift Benchmark (SSB) for evaluation, we focused on ImageNet1k as the in-distribution (ID) dataset and a subset of ImageNet21k as the out-of-distribution (OOD) dataset.To address this, we proposed a hybrid approach, experimenting with the fusion of various post-hoc OOD detection techniques and different Test-Time Augmentation (TTA) strategies. Additionally, we evaluated the impact of several base models on the final performance. Our best-performing method combined Test-Time Augmentation with the post-hoc OOD techniques, achieving a strong balance between AUROC and FPR95 scores. Our approach resulted in AUROC: 79.77 (ranked 5th) and FPR95: 61.44 (ranked 2nd), securing second place in the overall competition.
MetaSD: A Unified Framework for Scalable Downscaling of Meteorological Variables in Diverse Situations
Apr 26, 2024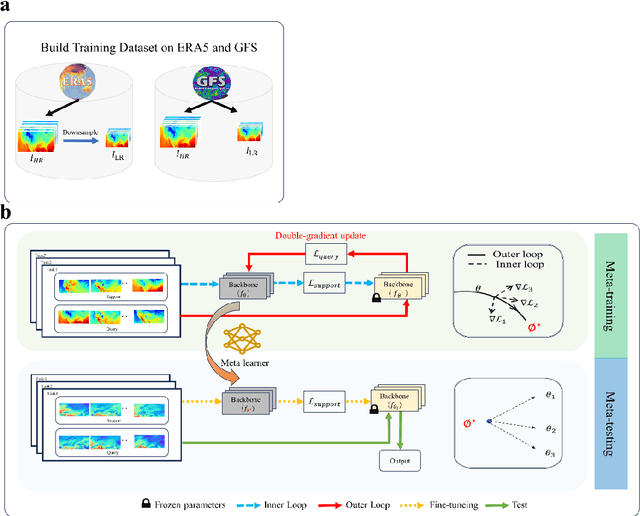
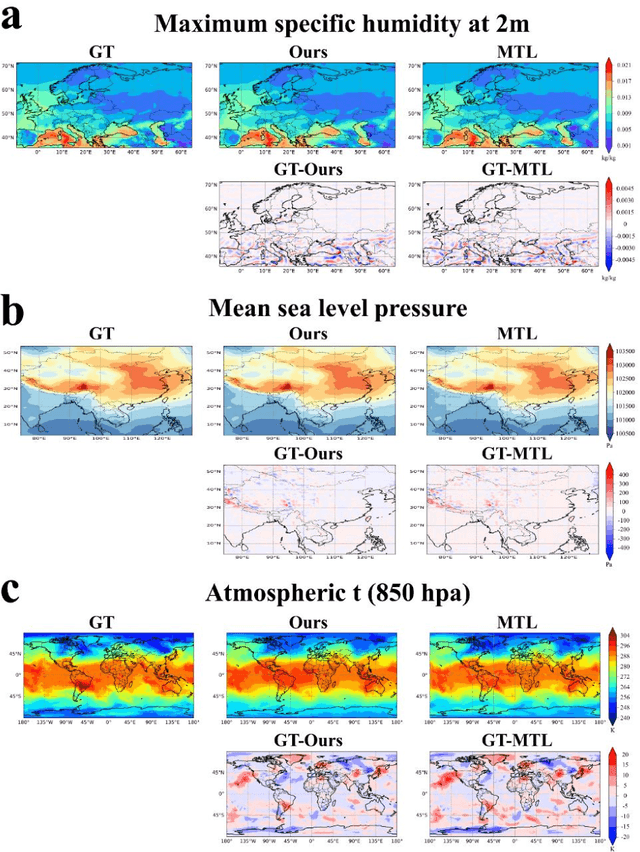
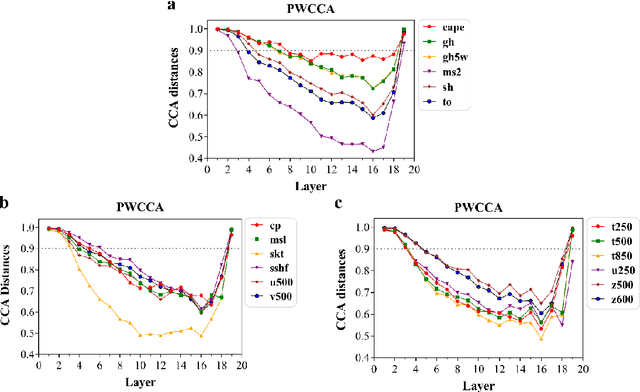
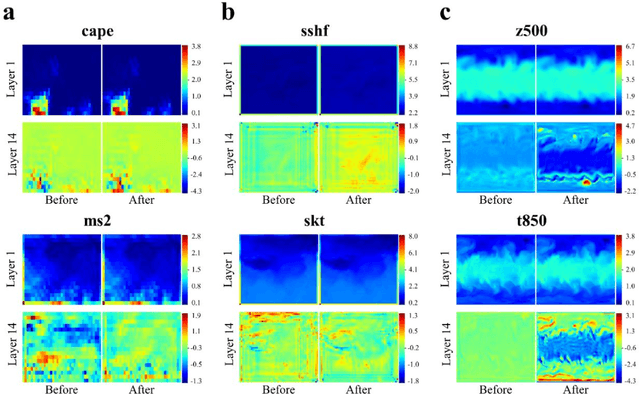
Addressing complex meteorological processes at a fine spatial resolution requires substantial computational resources. To accelerate meteorological simulations, researchers have utilized neural networks to downscale meteorological variables from low-resolution simulations. Despite notable advancements, contemporary cutting-edge downscaling algorithms tailored to specific variables. Addressing meteorological variables in isolation overlooks their interconnectedness, leading to an incomplete understanding of atmospheric dynamics. Additionally, the laborious processes of data collection, annotation, and computational resources required for individual variable downscaling are significant hurdles. Given the limited versatility of existing models across different meteorological variables and their failure to account for inter-variable relationships, this paper proposes a unified downscaling approach leveraging meta-learning. This framework aims to facilitate the downscaling of diverse meteorological variables derived from various numerical models and spatiotemporal scales. Trained at variables consisted of temperature, wind, surface pressure and total precipitation from ERA5 and GFS, the proposed method can be extended to downscale convective precipitation, potential energy, height, humidity and ozone from CFS, S2S and CMIP6 at different spatiotemporal scales, which demonstrating its capability to capture the interconnections among diverse variables. Our approach represents the initial effort to create a generalized downscaling model. Experimental evidence demonstrates that the proposed model outperforms existing top downscaling methods in both quantitative and qualitative assessments.
D-Aug: Enhancing Data Augmentation for Dynamic LiDAR Scenes
Apr 17, 2024Creating large LiDAR datasets with pixel-level labeling poses significant challenges. While numerous data augmentation methods have been developed to reduce the reliance on manual labeling, these methods predominantly focus on static scenes and they overlook the importance of data augmentation for dynamic scenes, which is critical for autonomous driving. To address this issue, we propose D-Aug, a LiDAR data augmentation method tailored for augmenting dynamic scenes. D-Aug extracts objects and inserts them into dynamic scenes, considering the continuity of these objects across consecutive frames. For seamless insertion into dynamic scenes, we propose a reference-guided method that involves dynamic collision detection and rotation alignment. Additionally, we present a pixel-level road identification strategy to efficiently determine suitable insertion positions. We validated our method using the nuScenes dataset with various 3D detection and tracking methods. Comparative experiments demonstrate the superiority of D-Aug.
SemanticHuman-HD: High-Resolution Semantic Disentangled 3D Human Generation
Mar 15, 2024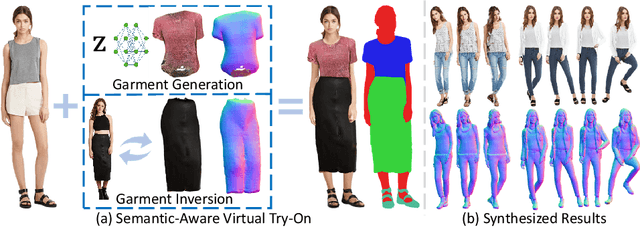
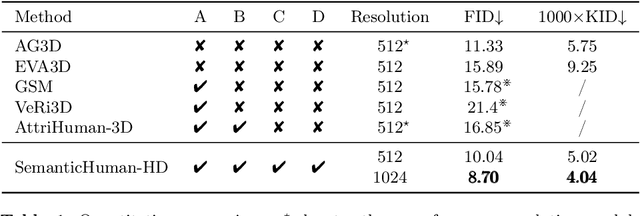
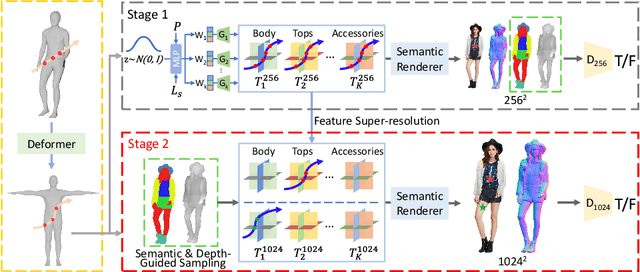

With the development of neural radiance fields and generative models, numerous methods have been proposed for learning 3D human generation from 2D images. These methods allow control over the pose of the generated 3D human and enable rendering from different viewpoints. However, none of these methods explore semantic disentanglement in human image synthesis, i.e., they can not disentangle the generation of different semantic parts, such as the body, tops, and bottoms. Furthermore, existing methods are limited to synthesize images at $512^2$ resolution due to the high computational cost of neural radiance fields. To address these limitations, we introduce SemanticHuman-HD, the first method to achieve semantic disentangled human image synthesis. Notably, SemanticHuman-HD is also the first method to achieve 3D-aware image synthesis at $1024^2$ resolution, benefiting from our proposed 3D-aware super-resolution module. By leveraging the depth maps and semantic masks as guidance for the 3D-aware super-resolution, we significantly reduce the number of sampling points during volume rendering, thereby reducing the computational cost. Our comparative experiments demonstrate the superiority of our method. The effectiveness of each proposed component is also verified through ablation studies. Moreover, our method opens up exciting possibilities for various applications, including 3D garment generation, semantic-aware image synthesis, controllable image synthesis, and out-of-domain image synthesis.
TaylorGrid: Towards Fast and High-Quality Implicit Field Learning via Direct Taylor-based Grid Optimization
Feb 22, 2024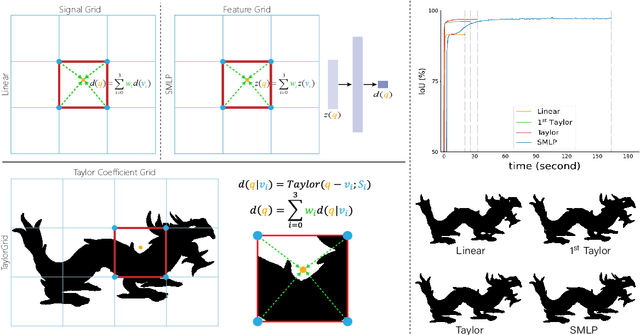
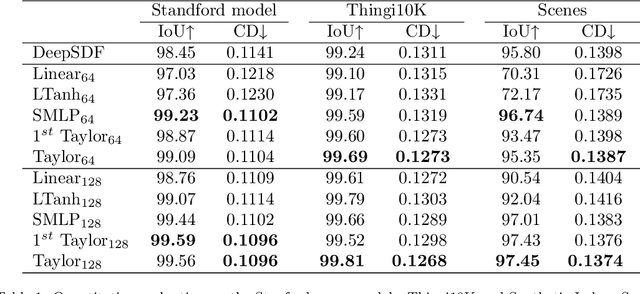

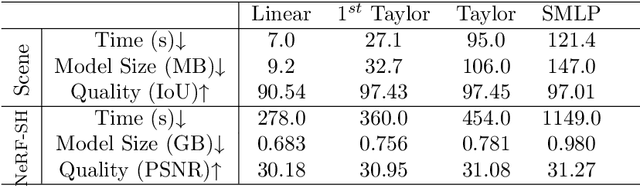
Coordinate-based neural implicit representation or implicit fields have been widely studied for 3D geometry representation or novel view synthesis. Recently, a series of efforts have been devoted to accelerating the speed and improving the quality of the coordinate-based implicit field learning. Instead of learning heavy MLPs to predict the neural implicit values for the query coordinates, neural voxels or grids combined with shallow MLPs have been proposed to achieve high-quality implicit field learning with reduced optimization time. On the other hand, lightweight field representations such as linear grid have been proposed to further improve the learning speed. In this paper, we aim for both fast and high-quality implicit field learning, and propose TaylorGrid, a novel implicit field representation which can be efficiently computed via direct Taylor expansion optimization on 2D or 3D grids. As a general representation, TaylorGrid can be adapted to different implicit fields learning tasks such as SDF learning or NeRF. From extensive quantitative and qualitative comparisons, TaylorGrid achieves a balance between the linear grid and neural voxels, showing its superiority in fast and high-quality implicit field learning.
3D-SSGAN: Lifting 2D Semantics for 3D-Aware Compositional Portrait Synthesis
Jan 08, 2024
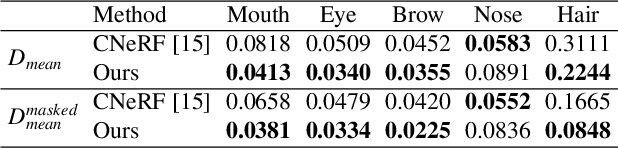
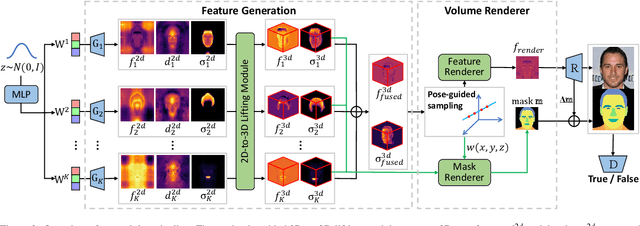

Existing 3D-aware portrait synthesis methods can generate impressive high-quality images while preserving strong 3D consistency. However, most of them cannot support the fine-grained part-level control over synthesized images. Conversely, some GAN-based 2D portrait synthesis methods can achieve clear disentanglement of facial regions, but they cannot preserve view consistency due to a lack of 3D modeling abilities. To address these issues, we propose 3D-SSGAN, a novel framework for 3D-aware compositional portrait image synthesis. First, a simple yet effective depth-guided 2D-to-3D lifting module maps the generated 2D part features and semantics to 3D. Then, a volume renderer with a novel 3D-aware semantic mask renderer is utilized to produce the composed face features and corresponding masks. The whole framework is trained end-to-end by discriminating between real and synthesized 2D images and their semantic masks. Quantitative and qualitative evaluations demonstrate the superiority of 3D-SSGAN in controllable part-level synthesis while preserving 3D view consistency.
Bilateral Reference for High-Resolution Dichotomous Image Segmentation
Jan 07, 2024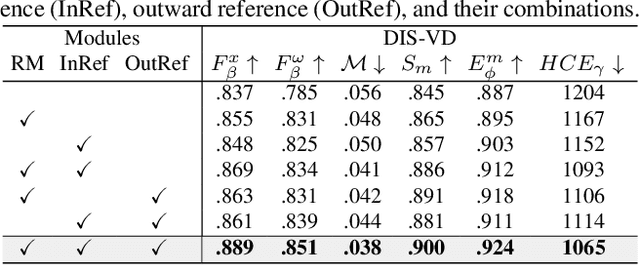
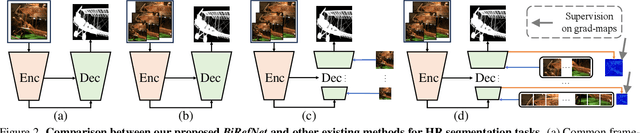
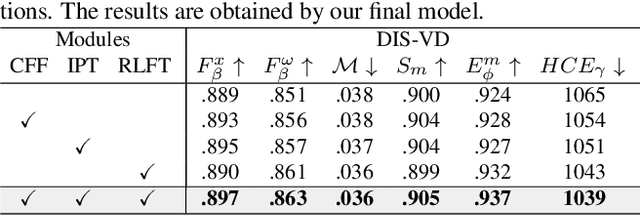
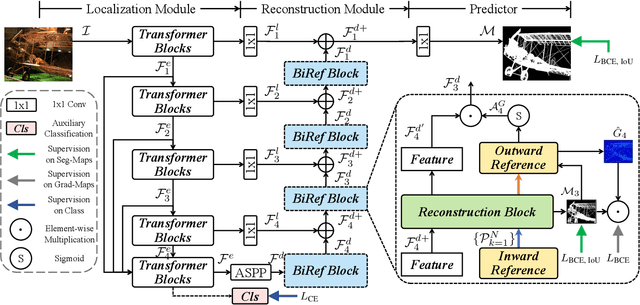
We introduce a novel bilateral reference framework (***BiRefNet***) for high-resolution dichotomous image segmentation (DIS). It comprises two essential components: the localization module (LM) and the reconstruction module (RM) with our proposed bilateral reference (BiRef). The LM aids in object localization using global semantic information. Within the RM, we utilize BiRef for the reconstruction process, where hierarchical patches of images provide the source reference and gradient maps serve as the target reference. These components collaborate to generate the final predicted maps. We also introduce auxiliary gradient supervision to enhance focus on regions with finer details. Furthermore, we outline practical training strategies tailored for DIS to improve map quality and training process. To validate the general applicability of our approach, we conduct extensive experiments on four tasks to evince that *BiRefNet* exhibits remarkable performance, outperforming task-specific cutting-edge methods across all benchmarks.