 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperNeRF-GAN: A Universal 3D-Consistent Super-Resolution Framework for Efficient and Enhanced 3D-Aware Image Synthesis
Jan 12, 2025



Neural volume rendering techniques, such as NeRF, have revolutionized 3D-aware image synthesis by enabling the generation of images of a single scene or object from various camera poses. However, the high computational cost of NeRF presents challenges for synthesizing high-resolution (HR) images. Most existing methods address this issue by leveraging 2D super-resolution, which compromise 3D-consistency. Other methods propose radiance manifolds or two-stage generation to achieve 3D-consistent HR synthesis, yet they are limited to specific synthesis tasks, reducing their universality. To tackle these challenges, we propose SuperNeRF-GAN, a universal framework for 3D-consistent super-resolution. A key highlight of SuperNeRF-GAN is its seamless integration with NeRF-based 3D-aware image synthesis methods and it can simultaneously enhance the resolution of generated images while preserving 3D-consistency and reducing computational cost. Specifically, given a pre-trained generator capable of producing a NeRF representation such as tri-plane, we first perform volume rendering to obtain a low-resolution image with corresponding depth and normal map. Then, we employ a NeRF Super-Resolution module which learns a network to obtain a high-resolution NeRF. Next, we propose a novel Depth-Guided Rendering process which contains three simple yet effective steps, including the construction of a boundary-correct multi-depth map through depth aggregation, a normal-guided depth super-resolution and a depth-guided NeRF rendering. Experimental results demonstrate the superior efficiency, 3D-consistency, and quality of our approach. Additionally, ablation studies confirm the effectiveness of our proposed components.
MMFakeBench: A Mixed-Source Multimodal Misinformation Detection Benchmark for LVLMs
Jun 13, 2024



Current multimodal misinformation detection (MMD) methods often assume a single source and type of forgery for each sample, which is insufficient for real-world scenarios where multiple forgery sources coexist. The lack of a benchmark for mixed-source misinformation has hindered progress in this field. To address this, we introduce MMFakeBench, the first comprehensive benchmark for mixed-source MMD. MMFakeBench includes 3 critical sources: textual veracity distortion, visual veracity distortion, and cross-modal consistency distortion, along with 12 sub-categories of misinformation forgery types. We further conduct an extensive evaluation of 6 prevalent detection methods and 15 large vision-language models (LVLMs) on MMFakeBench under a zero-shot setting. The results indicate that current methods struggle under this challenging and realistic mixed-source MMD setting. Additionally, we propose an innovative unified framework, which integrates rationales, actions, and tool-use capabilities of LVLM agents, significantly enhancing accuracy and generalization. We believe this study will catalyze future research into more realistic mixed-source multimodal misinformation and provide a fair evaluation of misinformation detection methods.
Skeleton2vec: A Self-supervised Learning Framework with Contextualized Target Representations for Skeleton Sequence
Jan 01, 2024Self-supervised pre-training paradigms have been extensively explored in the field of skeleton-based action recognition. In particular, methods based on masked prediction have pushed the performance of pre-training to a new height. However, these methods take low-level features, such as raw joint coordinates or temporal motion, as prediction targets for the masked regions, which is suboptimal. In this paper, we show that using high-level contextualized features as prediction targets can achieve superior performance. Specifically, we propose Skeleton2vec, a simple and efficient self-supervised 3D action representation learning framework, which utilizes a transformer-based teacher encoder taking unmasked training samples as input to create latent contextualized representations as prediction targets. Benefiting from the self-attention mechanism, the latent representations generated by the teacher encoder can incorporate the global context of the entire training samples, leading to a richer training task. Additionally, considering the high temporal correlations in skeleton sequences, we propose a motion-aware tube masking strategy which divides the skeleton sequence into several tubes and performs persistent masking within each tube based on motion priors, thus forcing the model to build long-range spatio-temporal connections and focus on action-semantic richer regions. Extensive experiments on NTU-60, NTU-120, and PKU-MMD datasets demonstrate that our proposed Skeleton2vec outperforms previous methods and achieves state-of-the-art results.
CornerFormer: Boosting Corner Representation for Fine-Grained Structured Reconstruction
Apr 22, 2023Structured reconstruction is a non-trivial dense prediction problem, which extracts structural information (\eg, building corners and edges) from a raster image, then reconstructs it to a 2D planar graph accordingly. Compared with common segmentation or detection problems, it significantly relays on the capability that leveraging holistic geometric information for structural reasoning. Current transformer-based approaches tackle this challenging problem in a two-stage manner, which detect corners in the first model and classify the proposed edges (corner-pairs) in the second model. However, they separate two-stage into different models and only share the backbone encoder. Unlike the existing modeling strategies, we present an enhanced corner representation method: 1) It fuses knowledge between the corner detection and edge prediction by sharing feature in different granularity; 2) Corner candidates are proposed in four heatmap channels w.r.t its direction. Both qualitative and quantitative evaluations demonstrate that our proposed method can better reconstruct fine-grained structures, such as adjacent corners and tiny edges. Consequently, it outperforms the state-of-the-art model by +1.9\%@F-1 on Corner and +3.0\%@F-1 on Edge.
Gradient Attention Balance Network: Mitigating Face Recognition Racial Bias via Gradient Attention
Apr 05, 2023



Although face recognition has made impressive progress in recent years, we ignore the racial bias of the recognition system when we pursue a high level of accuracy. Previous work found that for different races, face recognition networks focus on different facial regions, and the sensitive regions of darker-skinned people are much smaller. Based on this discovery, we propose a new de-bias method based on gradient attention, called Gradient Attention Balance Network (GABN). Specifically, we use the gradient attention map (GAM) of the face recognition network to track the sensitive facial regions and make the GAMs of different races tend to be consistent through adversarial learning. This method mitigates the bias by making the network focus on similar facial regions. In addition, we also use masks to erase the Top-N sensitive facial regions, forcing the network to allocate its attention to a larger facial region. This method expands the sensitive region of darker-skinned people and further reduces the gap between GAM of darker-skinned people and GAM of Caucasians. Extensive experiments show that GABN successfully mitigates racial bias in face recognition and learns more balanced performance for people of different races.
Semi-Supervised 2D Human Pose Estimation Driven by Position Inconsistency Pseudo Label Correction Module
Mar 08, 2023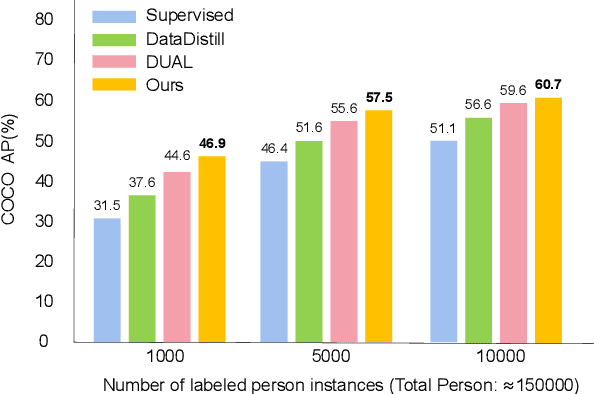
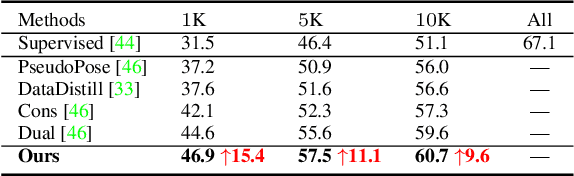
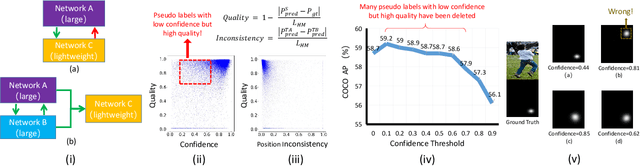
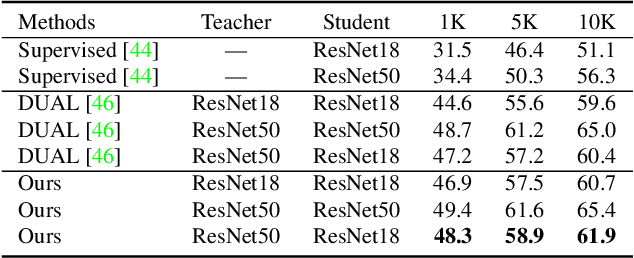
In this paper, we delve into semi-supervised 2D human pose estimation. The previous method ignored two problems: (i) When conducting interactive training between large model and lightweight model, the pseudo label of lightweight model will be used to guide large models. (ii) The negative impact of noise pseudo labels on training. Moreover, the labels used for 2D human pose estimation are relatively complex: keypoint category and keypoint position. To solve the problems mentioned above, we propose a semi-supervised 2D human pose estimation framework driven by a position inconsistency pseudo label correction module (SSPCM). We introduce an additional auxiliary teacher and use the pseudo labels generated by the two teacher model in different periods to calculate the inconsistency score and remove outliers. Then, the two teacher models are updated through interactive training, and the student model is updated using the pseudo labels generated by two teachers. To further improve the performance of the student model, we use the semi-supervised Cut-Occlude based on pseudo keypoint perception to generate more hard and effective samples. In addition, we also proposed a new indoor overhead fisheye human keypoint dataset WEPDTOF-Pose. Extensive experiments demonstrate that our method outperforms the previous best semi-supervised 2D human pose estimation method. We will release the code and dataset at https://github.com/hlz0606/SSPCM.
DH-AUG: DH Forward Kinematics Model Driven Augmentation for 3D Human Pose Estimation
Jul 19, 2022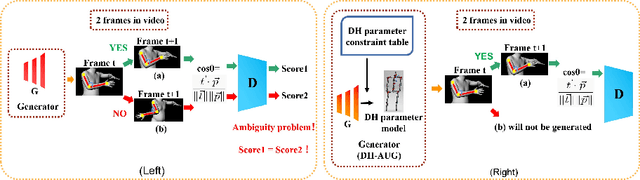
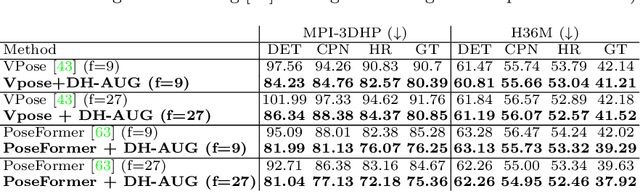
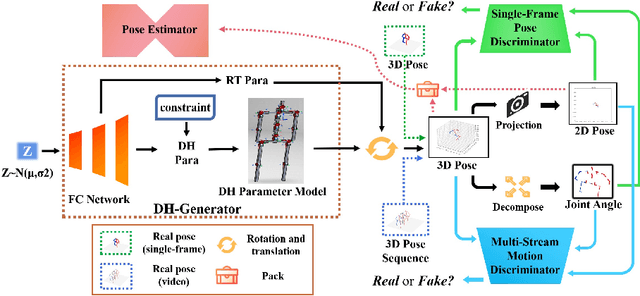

Due to the lack of diversity of datasets, the generalization ability of the pose estimator is poor. To solve this problem, we propose a pose augmentation solution via DH forward kinematics model, which we call DH-AUG. We observe that the previous work is all based on single-frame pose augmentation, if it is directly applied to video pose estimator, there will be several previously ignored problems: (i) angle ambiguity in bone rotation (multiple solutions); (ii) the generated skeleton video lacks movement continuity. To solve these problems, we propose a special generator based on DH forward kinematics model, which is called DH-generator. Extensive experiments demonstrate that DH-AUG can greatly increase the generalization ability of the video pose estimator. In addition, when applied to a single-frame 3D pose estimator, our method outperforms the previous best pose augmentation method. The source code has been released at https://github.com/hlz0606/DH-AUG-DH-Forward-Kinematics-Model-Driven-Augmentation-for-3D-Human-Pose-Estimation.