 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive ASR: Towards Human-Like Interaction and Semantic Coherence Evaluation for Agentic Speech Recognition
Apr 14, 2026Recent years have witnessed remarkable progress in automatic speech recognition (ASR), driven by advances in model architectures and large-scale training data. However, two important aspects remain underexplored. First, Word Error Rate (WER), the dominant evaluation metric for decades, treats all words equally and often fails to reflect the semantic correctness of an utterance at the sentence level. Second, interactive correction-an essential component of human communication-has rarely been systematically studied in ASR research. In this paper, we integrate these two perspectives under an agentic framework for interactive ASR. We propose leveraging LLM-as-a-Judge as a semantic-aware evaluation metric to assess recognition quality beyond token-level accuracy. Furthermore, we design an LLM-driven agent framework to simulate human-like multi-turn interaction, enabling iterative refinement of recognition outputs through semantic feedback. Extensive experiments are conducted on standard benchmarks, including GigaSpeech (English), WenetSpeech (Chinese), the ASRU 2019 code-switching test set. Both objective and subjective evaluations demonstrate the effectiveness of the proposed framework in improving semantic fidelity and interactive correction capability. We will release the code to facilitate future research in interactive and agentic ASR.
FGGM: Fisher-Guided Gradient Masking for Continual Learning
Jan 26, 2026Catastrophic forgetting impairs the continuous learning of large language models. We propose Fisher-Guided Gradient Masking (FGGM), a framework that mitigates this by strategically selecting parameters for updates using diagonal Fisher Information. FGGM dynamically generates binary masks with adaptive thresholds, preserving critical parameters to balance stability and plasticity without requiring historical data. Unlike magnitude-based methods such as MIGU, our approach offers a mathematically principled parameter importance estimation. On the TRACE benchmark, FGGM shows a 9.6% relative improvement in retaining general capabilities over supervised fine-tuning (SFT) and a 4.4% improvement over MIGU on TRACE tasks. Additional analysis on code generation tasks confirms FGGM's superior performance and reduced forgetting, establishing it as an effective solution.
E2E-AEC: Implementing an end-to-end neural network learning approach for acoustic echo cancellation
Jan 23, 2026We propose a novel neural network-based end-to-end acoustic echo cancellation (E2E-AEC) method capable of streaming inference, which operates effectively without reliance on traditional linear AEC (LAEC) techniques and time delay estimation. Our approach includes several key strategies: First, we introduce and refine progressive learning to gradually enhance echo suppression. Second, our model employs knowledge transfer by initializing with a pre-trained LAECbased model, harnessing the insights gained from LAEC training. Third, we optimize the attention mechanism with a loss function applied on attention weights to achieve precise time alignment between the reference and microphone signals. Lastly, we incorporate voice activity detection to enhance speech quality and improve echo removal by masking the network output when near-end speech is absent. The effectiveness of our approach is validated through experiments conducted on public datasets.
FlowSE-GRPO: Training Flow Matching Speech Enhancement via Online Reinforcement Learning
Jan 23, 2026Generative speech enhancement offers a promising alternative to traditional discriminative methods by modeling the distribution of clean speech conditioned on noisy inputs. Post-training alignment via reinforcement learning (RL) effectively aligns generative models with human preferences and downstream metrics in domains such as natural language processing, but its use in speech enhancement remains limited, especially for online RL. Prior work explores offline methods like Direct Preference Optimization (DPO); online methods such as Group Relative Policy Optimization (GRPO) remain largely uninvestigated. In this paper, we present the first successful integration of online GRPO into a flow-matching speech enhancement framework, enabling efficient post-training alignment to perceptual and task-oriented metrics with few update steps. Unlike prior GRPO work on Large Language Models, we adapt the algorithm to the continuous, time-series nature of speech and to the dynamics of flow-matching generative models. We show that optimizing a single reward yields rapid metric gains but often induces reward hacking that degrades audio fidelity despite higher scores. To mitigate this, we propose a multi-metric reward optimization strategy that balances competing objectives, substantially reducing overfitting and improving overall performance. Our experiments validate online GRPO for speech enhancement and provide practical guidance for RL-based post-training of generative audio models.
FunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
Jan 21, 2026Movie dubbing is the task of synthesizing speech from scripts conditioned on video scenes, requiring accurate lip sync, faithful timbre transfer, and proper modeling of character identity and emotion. However, existing methods face two major limitations: (1) high-quality multimodal dubbing datasets are limited in scale, suffer from high word error rates, contain sparse annotations, rely on costly manual labeling, and are restricted to monologue scenes, all of which hinder effective model training; (2) existing dubbing models rely solely on the lip region to learn audio-visual alignment, which limits their applicability to complex live-action cinematic scenes, and exhibit suboptimal performance in lip sync, speech quality, and emotional expressiveness. To address these issues, we propose FunCineForge, which comprises an end-to-end production pipeline for large-scale dubbing datasets and an MLLM-based dubbing model designed for diverse cinematic scenes. Using the pipeline, we construct the first Chinese television dubbing dataset with rich annotations, and demonstrate the high quality of these data. Experiments across monologue, narration, dialogue, and multi-speaker scenes show that our dubbing model consistently outperforms SOTA methods in audio quality, lip sync, timbre transfer, and instruction following. Code and demos are available at https://anonymous.4open.science/w/FunCineForge.
Fun-Audio-Chat Technical Report
Dec 23, 2025Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo.
MELA-TTS: Joint transformer-diffusion model with representation alignment for speech synthesis
Sep 18, 2025This work introduces MELA-TTS, a novel joint transformer-diffusion framework for end-to-end text-to-speech synthesis. By autoregressively generating continuous mel-spectrogram frames from linguistic and speaker conditions, our architecture eliminates the need for speech tokenization and multi-stage processing pipelines. To address the inherent difficulties of modeling continuous features, we propose a representation alignment module that aligns output representations of the transformer decoder with semantic embeddings from a pretrained ASR encoder during training. This mechanism not only speeds up training convergence, but also enhances cross-modal coherence between the textual and acoustic domains. Comprehensive experiments demonstrate that MELA-TTS achieves state-of-the-art performance across multiple evaluation metrics while maintaining robust zero-shot voice cloning capabilities, in both offline and streaming synthesis modes. Our results establish a new benchmark for continuous feature generation approaches in TTS, offering a compelling alternative to discrete-token-based paradigms.
FunAudio-ASR Technical Report
Sep 15, 2025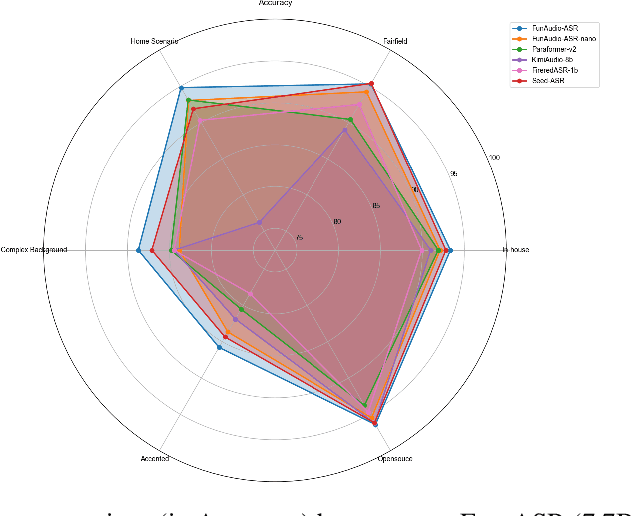
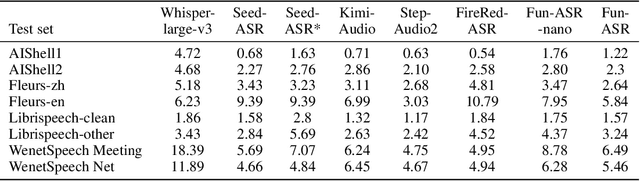
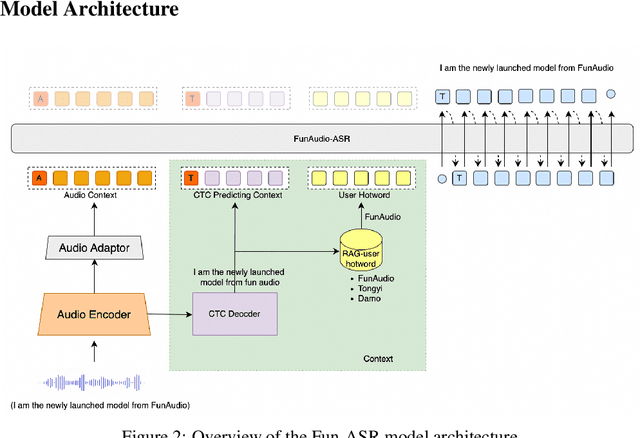
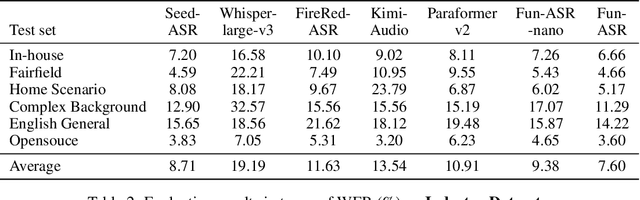
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Aug 08, 2025The Speaker Diarization and Recognition (SDR) task aims to predict "who spoke when and what" within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
Not All Correct Answers Are Equal: Why Your Distillation Source Matters
May 20, 2025Distillation has emerged as a practical and effective approach to enhance the reasoning capabilities of open-source language models. In this work, we conduct a large-scale empirical study on reasoning data distillation by collecting verified outputs from three state-of-the-art teacher models-AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1-on a shared corpus of 1.89 million queries. We construct three parallel datasets and analyze their distributions, revealing that AM-Thinking-v1-distilled data exhibits greater token length diversity and lower perplexity. Student models trained on each dataset are evaluated on reasoning benchmarks including AIME2024, AIME2025, MATH500, and LiveCodeBench. The AM-based model consistently achieves the best performance (e.g., 84.3 on AIME2024, 72.2 on AIME2025, 98.4 on MATH500, and 65.9 on LiveCodeBench) and demonstrates adaptive output behavior-producing longer responses for harder tasks and shorter ones for simpler tasks. These findings highlight the value of high-quality, verified reasoning traces. We release the AM-Thinking-v1 and Qwen3-235B-A22B distilled datasets to support future research on open and high-performing reasoning-oriented language models. The datasets are publicly available on Hugging Face\footnote{Datasets are available on Hugging Face: \href{https://huggingface.co/datasets/a-m-team/AM-Thinking-v1-Distilled}{AM-Thinking-v1-Distilled}, \href{https://huggingface.co/datasets/a-m-team/AM-Qwen3-Distilled}{AM-Qwen3-Distilled}.}.