 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPIQ: Residual-Projected Multi-Collaboration Closed-Loop and Single Instance Quantization for Visually Impaired Assistance
Jan 06, 2026Visually impaired users face significant challenges in daily information access and real-time environmental perception, and there is an urgent need for intelligent assistive systems with accurate recognition capabilities. Although large-scale models provide effective solutions for perception and reasoning, their practical deployment on assistive devices is severely constrained by excessive memory consumption and high inference costs. Moreover, existing quantization strategies often ignore inter-block error accumulation, leading to degraded model stability. To address these challenges, this study proposes a novel quantization framework -- Residual-Projected Multi-Collaboration Closed-Loop and Single Instance Quantization(RPIQ), whose quantization process adopts a multi-collaborative closed-loop compensation scheme based on Single Instance Calibration and Gauss-Seidel Iterative Quantization. Experiments on various types of large-scale models, including language models such as OPT, Qwen, and LLaMA, as well as vision-language models such as CogVLM2, demonstrate that RPIQ can compress models to 4-bit representation while significantly reducing peak memory consumption (approximately 60%-75% reduction compared to original full-precision models). The method maintains performance highly close to full-precision models across multiple language and visual tasks, and exhibits excellent recognition and reasoning capabilities in key applications such as text understanding and visual question answering in complex scenarios. While verifying the effectiveness of RPIQ for deployment in real assistive systems, this study also advances the computational efficiency and reliability of large models, enabling them to provide visually impaired users with the required information accurately and rapidly.
Momentum-constrained Hybrid Heuristic Trajectory Optimization Framework with Residual-enhanced DRL for Visually Impaired Scenarios
Sep 19, 2025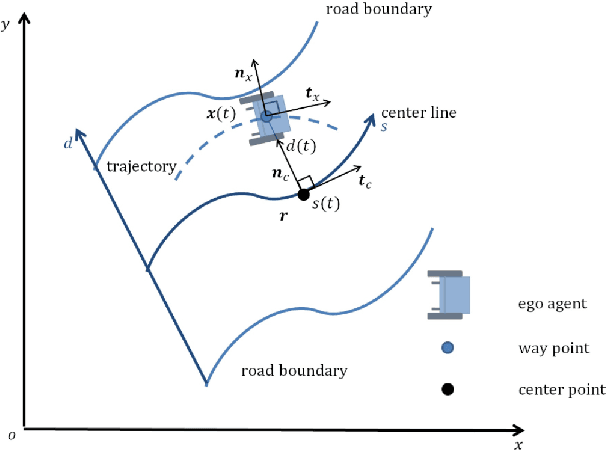
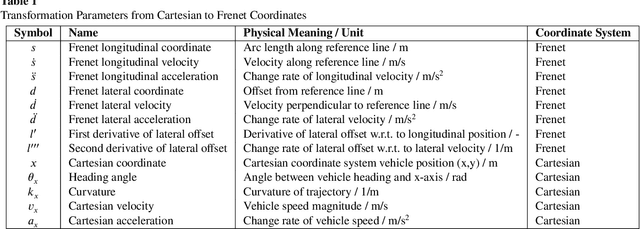
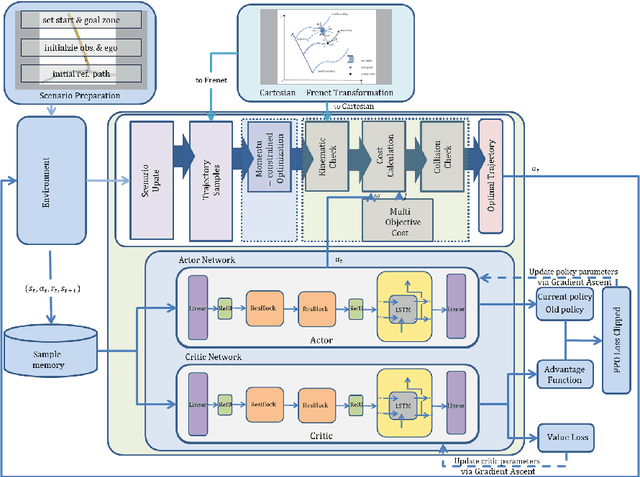

This paper proposes a momentum-constrained hybrid heuristic trajectory optimization framework (MHHTOF) tailored for assistive navigation in visually impaired scenarios, integrating trajectory sampling generation, optimization and evaluation with residual-enhanced deep reinforcement learning (DRL). In the first stage, heuristic trajectory sampling cluster (HTSC) is generated in the Frenet coordinate system using third-order interpolation with fifth-order polynomials and momentum-constrained trajectory optimization (MTO) constraints to ensure smoothness and feasibility. After first stage cost evaluation, the second stage leverages a residual-enhanced actor-critic network with LSTM-based temporal feature modeling to adaptively refine trajectory selection in the Cartesian coordinate system. A dual-stage cost modeling mechanism (DCMM) with weight transfer aligns semantic priorities across stages, supporting human-centered optimization. Experimental results demonstrate that the proposed LSTM-ResB-PPO achieves significantly faster convergence, attaining stable policy performance in approximately half the training iterations required by the PPO baseline, while simultaneously enhancing both reward outcomes and training stability. Compared to baseline method, the selected model reduces average cost and cost variance by 30.3% and 53.3%, and lowers ego and obstacle risks by over 77%. These findings validate the framework's effectiveness in enhancing robustness, safety, and real-time feasibility in complex assistive planning tasks.
FunAudio-ASR Technical Report
Sep 15, 2025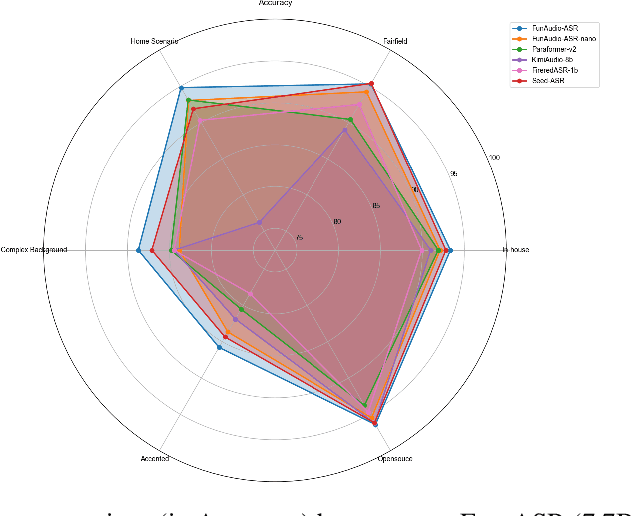
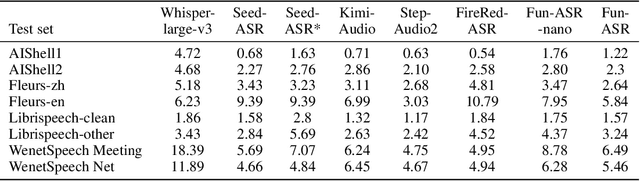
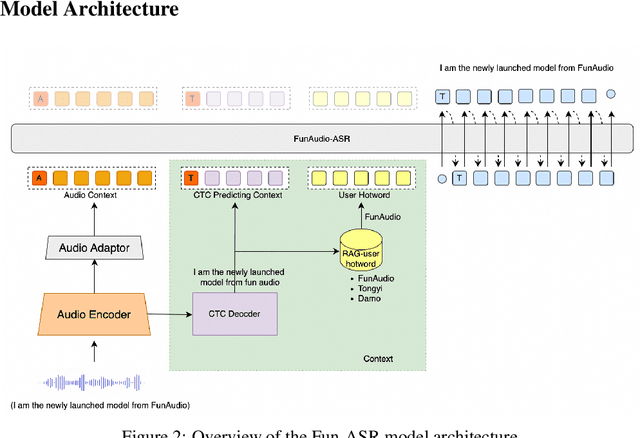
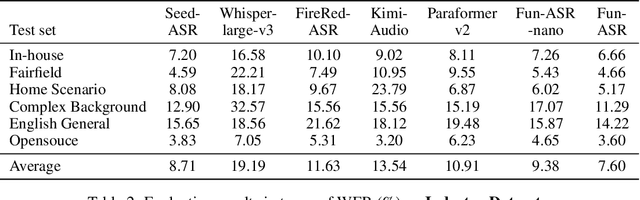
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Development of Reduced Feeder and Load Models Using Practical Topological and Loading Data
May 09, 2025Distribution feeder and load model reduction methods are essential for maintaining a good tradeoff between accurate representation of grid behavior and reduced computational complexity in power system studies. An effective algorithm to obtain a reduced order representation of the practical feeders using utility topological and loading data has been presented in this paper. Simulations conducted in this work show that the reduced feeder and load model of a utility feeder, obtained using the proposed method, can accurately capture contactor and motor stalling behaviors for critical events such as fault induced delayed voltage recovery.
SegAttnGAN: Text to Image Generation with Segmentation Attention
May 25, 2020
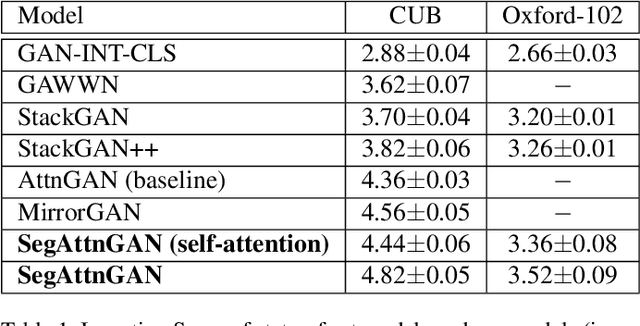
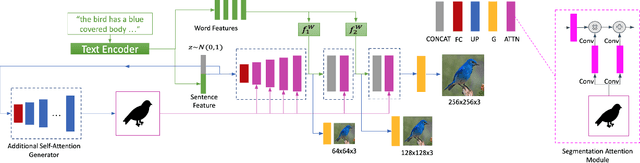

In this paper, we propose a novel generative network (SegAttnGAN) that utilizes additional segmentation information for the text-to-image synthesis task. As the segmentation data introduced to the model provides useful guidance on the generator training, the proposed model can generate images with better realism quality and higher quantitative measures compared with the previous state-of-art methods. We achieved Inception Score of 4.84 on the CUB dataset and 3.52 on the Oxford-102 dataset. Besides, we tested the self-attention SegAttnGAN which uses generated segmentation data instead of masks from datasets for attention and achieved similar high-quality results, suggesting that our model can be adapted for the text-to-image synthesis task.