 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELA-TTS: Joint transformer-diffusion model with representation alignment for speech synthesis
Sep 18, 2025This work introduces MELA-TTS, a novel joint transformer-diffusion framework for end-to-end text-to-speech synthesis. By autoregressively generating continuous mel-spectrogram frames from linguistic and speaker conditions, our architecture eliminates the need for speech tokenization and multi-stage processing pipelines. To address the inherent difficulties of modeling continuous features, we propose a representation alignment module that aligns output representations of the transformer decoder with semantic embeddings from a pretrained ASR encoder during training. This mechanism not only speeds up training convergence, but also enhances cross-modal coherence between the textual and acoustic domains. Comprehensive experiments demonstrate that MELA-TTS achieves state-of-the-art performance across multiple evaluation metrics while maintaining robust zero-shot voice cloning capabilities, in both offline and streaming synthesis modes. Our results establish a new benchmark for continuous feature generation approaches in TTS, offering a compelling alternative to discrete-token-based paradigms.
FunAudio-ASR Technical Report
Sep 15, 2025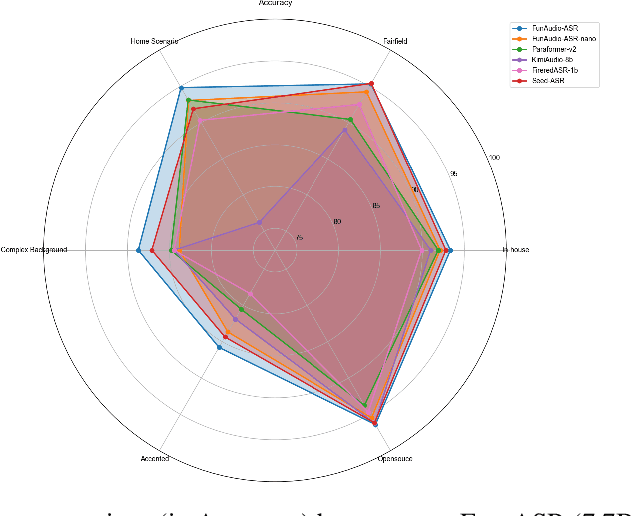
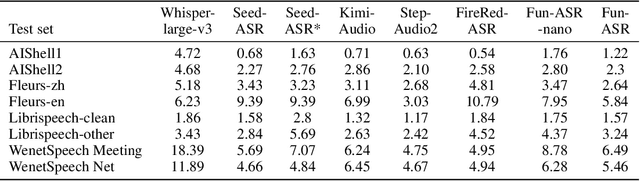
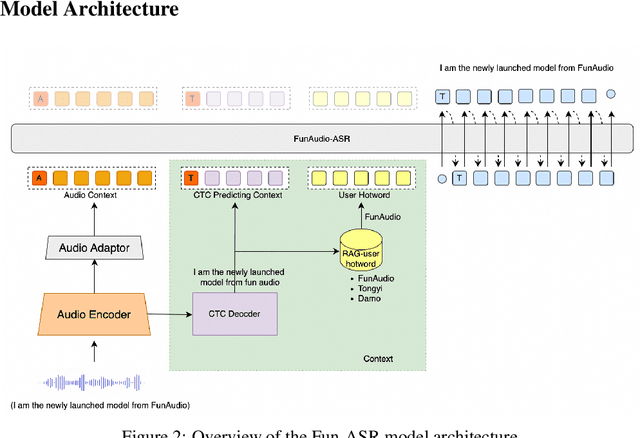
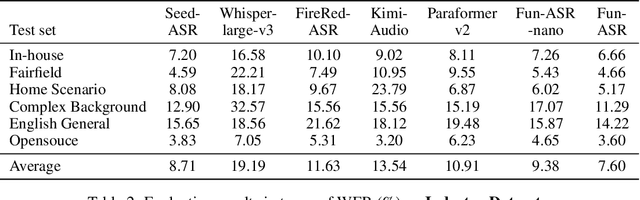
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
Are Transformers in Pre-trained LM A Good ASR Encoder? An Empirical Study
Sep 26, 2024

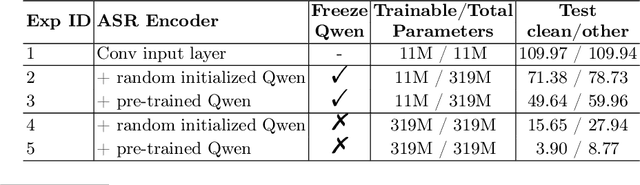

In this study, we delve into the efficacy of transformers within pre-trained language models (PLMs) when repurposed as encoders for Automatic Speech Recognition (ASR). Our underlying hypothesis posits that, despite being initially trained on text-based corpora, these transformers possess a remarkable capacity to extract effective features from the input sequence. This inherent capability, we argue, is transferrable to speech data, thereby augmenting the acoustic modeling ability of ASR. Through rigorous empirical analysis, our findings reveal a notable improvement in Character Error Rate (CER) and Word Error Rate (WER) across diverse ASR tasks when transformers from pre-trained LMs are incorporated. Particularly, they serve as an advantageous starting point for initializing ASR encoders. Furthermore, we uncover that these transformers, when integrated into a well-established ASR encoder, can significantly boost performance, especially in scenarios where profound semantic comprehension is pivotal. This underscores the potential of leveraging the semantic prowess embedded within pre-trained transformers to advance ASR systems' capabilities.
Paraformer-v2: An improved non-autoregressive transformer for noise-robust speech recognition
Sep 26, 2024Attention-based encoder-decoder, e.g. transformer and its variants, generates the output sequence in an autoregressive (AR) manner. Despite its superior performance, AR model is computationally inefficient as its generation requires as many iterations as the output length. In this paper, we propose Paraformer-v2, an improved version of Paraformer, for fast, accurate, and noise-robust non-autoregressive speech recognition. In Paraformer-v2, we use a CTC module to extract the token embeddings, as the alternative to the continuous integrate-and-fire module in Paraformer. Extensive experiments demonstrate that Paraformer-v2 outperforms Paraformer on multiple datasets, especially on the English datasets (over 14% improvement on WER), and is more robust in noisy environments.
Advancing VAD Systems Based on Multi-Task Learning with Improved Model Structures
Dec 19, 2023In a speech recognition system, voice activity detection (VAD) is a crucial frontend module. Addressing the issues of poor noise robustness in traditional binary VAD systems based on DFSMN, the paper further proposes semantic VAD based on multi-task learning with improved models for real-time and offline systems, to meet specific application requirements. Evaluations on internal datasets show that, compared to the real-time VAD system based on DFSMN, the real-time semantic VAD system based on RWKV achieves relative decreases in CER of 7.0\%, DCF of 26.1\% and relative improvement in NRR of 19.2\%. Similarly, when compared to the offline VAD system based on DFSMN, the offline VAD system based on SAN-M demonstrates relative decreases in CER of 4.4\%, DCF of 18.6\% and relative improvement in NRR of 3.5\%.
Exploring RWKV for Memory Efficient and Low Latency Streaming ASR
Sep 26, 2023



Recently, self-attention-based transformers and conformers have been introduced as alternatives to RNNs for ASR acoustic modeling. Nevertheless, the full-sequence attention mechanism is non-streamable and computationally expensive, thus requiring modifications, such as chunking and caching, for efficient streaming ASR. In this paper, we propose to apply RWKV, a variant of linear attention transformer, to streaming ASR. RWKV combines the superior performance of transformers and the inference efficiency of RNNs, which is well-suited for streaming ASR scenarios where the budget for latency and memory is restricted. Experiments on varying scales (100h - 10000h) demonstrate that RWKV-Transducer and RWKV-Boundary-Aware-Transducer achieve comparable to or even better accuracy compared with chunk conformer transducer, with minimal latency and inference memory cost.
BAT: Boundary aware transducer for memory-efficient and low-latency ASR
May 19, 2023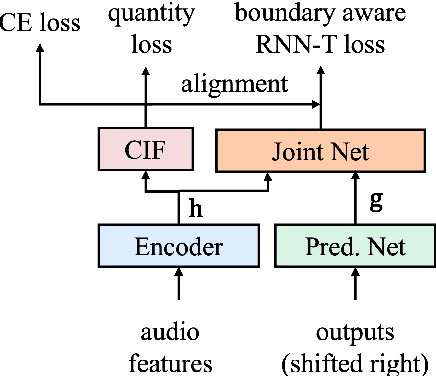
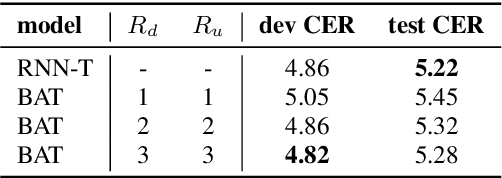
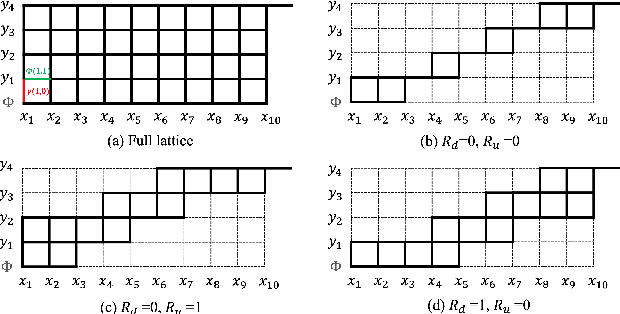

Recently, recurrent neural network transducer (RNN-T) gains increasing popularity due to its natural streaming capability as well as superior performance. Nevertheless, RNN-T training requires large time and computation resources as RNN-T loss calculation is slow and consumes a lot of memory. Another limitation of RNN-T is that it tends to access more contexts for better performance, thus leading to higher emission latency in streaming ASR. In this paper we propose boundary-aware transducer (BAT) for memory-efficient and low-latency ASR. In BAT, the lattice for RNN-T loss computation is reduced to a restricted region selected by the alignment from continuous integrate-and-fire (CIF), which is jointly optimized with the RNN-T model. Extensive experiments demonstrate that compared to RNN-T, BAT reduces time and memory consumption significantly in training, and achieves good CER-latency trade-offs in inference for streaming ASR.
An Empirical Study of Language Model Integration for Transducer based Speech Recognition
Mar 31, 2022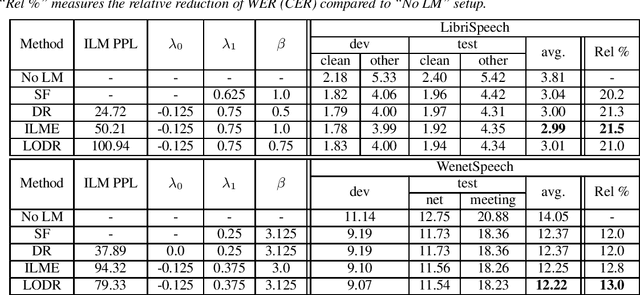
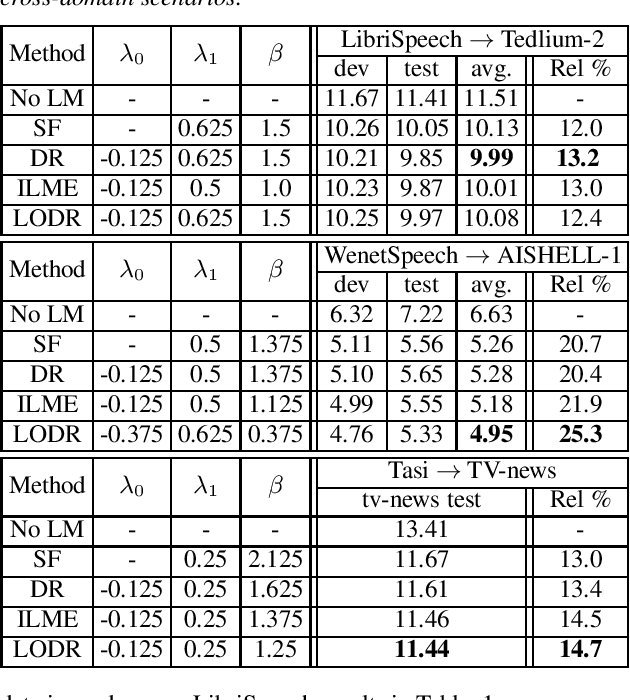
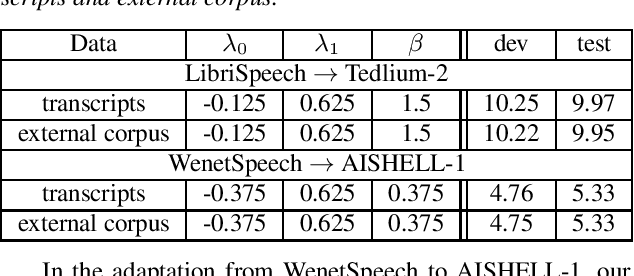
Utilizing text-only data with an external language model (LM) in end-to-end RNN-Transducer (RNN-T) for speech recognition is challenging. Recently, a class of methods such as density ratio (DR) and ILM estimation (ILME) have been developed, outperforming the classic shallow fusion (SF) method. The basic idea behind these methods is that RNN-T posterior should first subtract the implicitly learned ILM prior, in order to integrate the external LM. While recent studies suggest that RNN-T only learns some low-order language model information, the DR method uses a well-trained ILM. We hypothesize that this setting is appropriate and may deteriorate the performance of the DR method, and propose a low-order density ratio method (LODR) by training a low-order weak ILM for DR. Extensive empirical experiments are conducted on both in-domain and cross-domain scenarios on English LibriSpeech & Tedlium-2 and Chinese WenetSpeech & AISHELL-1 datasets. It is shown that LODR consistently outperforms SF in all tasks, while performing generally close to ILME and better than DR in most tests.
CUSIDE: Chunking, Simulating Future Context and Decoding for Streaming ASR
Mar 31, 2022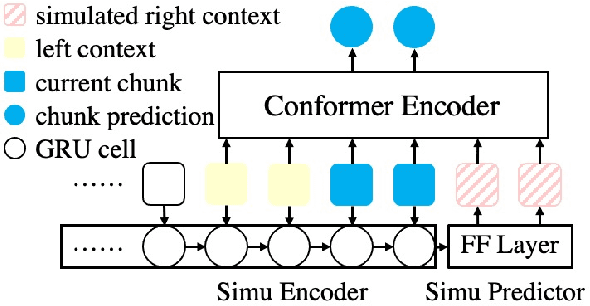
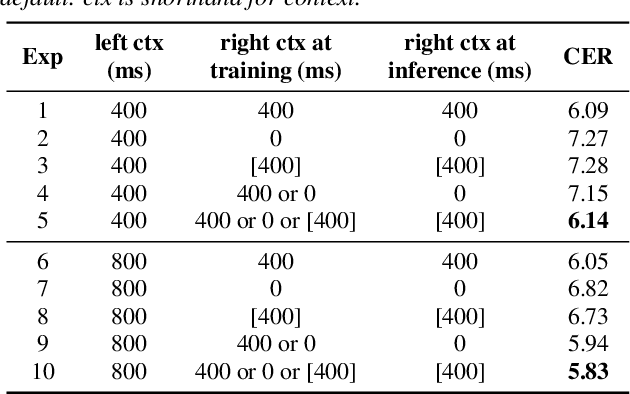

History and future contextual information are known to be important for accurate acoustic modeling. However, acquiring future context brings latency for streaming ASR. In this paper, we propose a new framework - Chunking, Simulating Future Context and Decoding (CUSIDE) for streaming speech recognition. A new simulation module is introduced to recursively simulate the future contextual frames, without waiting for future context. The simulation module is jointly trained with the ASR model using a self-supervised loss; the ASR model is optimized with the usual ASR loss, e.g., CTC-CRF as used in our experiments. Experiments show that, compared to using real future frames as right context, using simulated future context can drastically reduce latency while maintaining recognition accuracy. With CUSIDE, we obtain new state-of-the-art streaming ASR results on the AISHELL-1 dataset.