 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing VAD Systems Based on Multi-Task Learning with Improved Model Structures
Dec 19, 2023In a speech recognition system, voice activity detection (VAD) is a crucial frontend module. Addressing the issues of poor noise robustness in traditional binary VAD systems based on DFSMN, the paper further proposes semantic VAD based on multi-task learning with improved models for real-time and offline systems, to meet specific application requirements. Evaluations on internal datasets show that, compared to the real-time VAD system based on DFSMN, the real-time semantic VAD system based on RWKV achieves relative decreases in CER of 7.0\%, DCF of 26.1\% and relative improvement in NRR of 19.2\%. Similarly, when compared to the offline VAD system based on DFSMN, the offline VAD system based on SAN-M demonstrates relative decreases in CER of 4.4\%, DCF of 18.6\% and relative improvement in NRR of 3.5\%.
Semantic VAD: Low-Latency Voice Activity Detection for Speech Interaction
May 21, 2023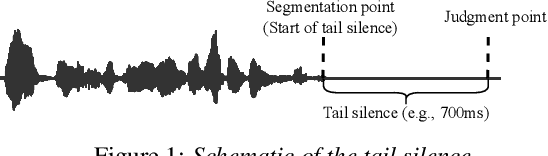
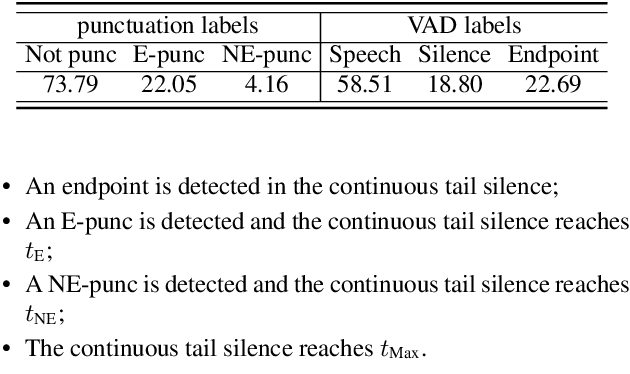
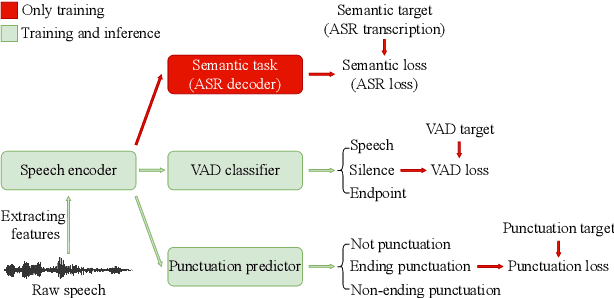
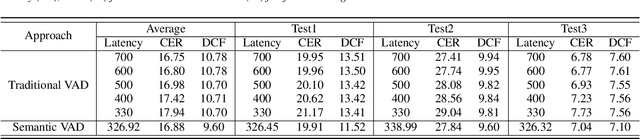
For speech interaction, voice activity detection (VAD) is often used as a front-end. However, traditional VAD algorithms usually need to wait for a continuous tail silence to reach a preset maximum duration before segmentation, resulting in a large latency that affects user experience. In this paper, we propose a novel semantic VAD for low-latency segmentation. Different from existing methods, a frame-level punctuation prediction task is added to the semantic VAD, and the artificial endpoint is included in the classification category in addition to the often-used speech presence and absence. To enhance the semantic information of the model, we also incorporate an automatic speech recognition (ASR) related semantic loss. Evaluations on an internal dataset show that the proposed method can reduce the average latency by 53.3% without significant deterioration of character error rate in the back-end ASR compared to the traditional VAD approach.
FunASR: A Fundamental End-to-End Speech Recognition Toolkit
May 18, 2023

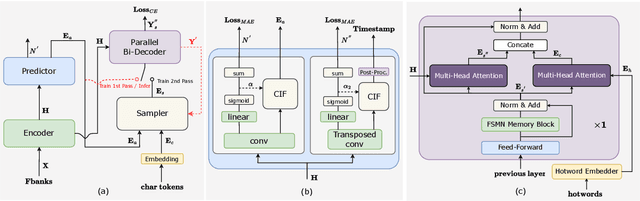
This paper introduces FunASR, an open-source speech recognition toolkit designed to bridge the gap between academic research and industrial applications. FunASR offers models trained on large-scale industrial corpora and the ability to deploy them in applications. The toolkit's flagship model, Paraformer, is a non-autoregressive end-to-end speech recognition model that has been trained on a manually annotated Mandarin speech recognition dataset that contains 60,000 hours of speech. To improve the performance of Paraformer, we have added timestamp prediction and hotword customization capabilities to the standard Paraformer backbone. In addition, to facilitate model deployment, we have open-sourced a voice activity detection model based on the Feedforward Sequential Memory Network (FSMN-VAD) and a text post-processing punctuation model based on the controllable time-delay Transformer (CT-Transformer), both of which were trained on industrial corpora. These functional modules provide a solid foundation for building high-precision long audio speech recognition services. Compared to other models trained on open datasets, Paraformer demonstrates superior performance.