 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunAudio-ASR Technical Report
Sep 15, 2025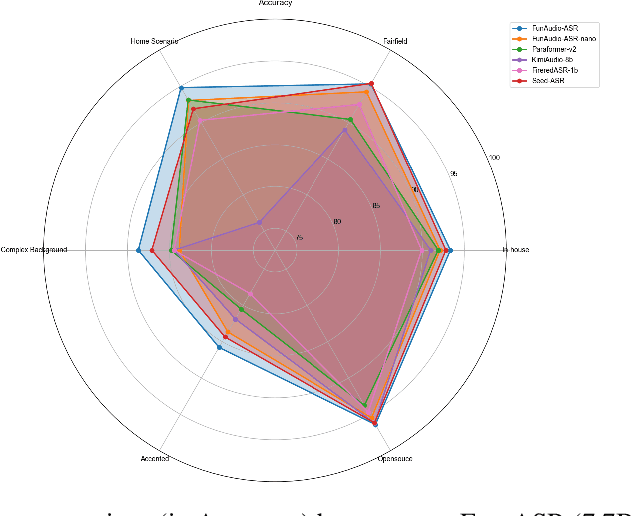
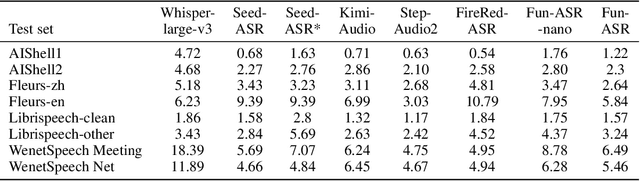
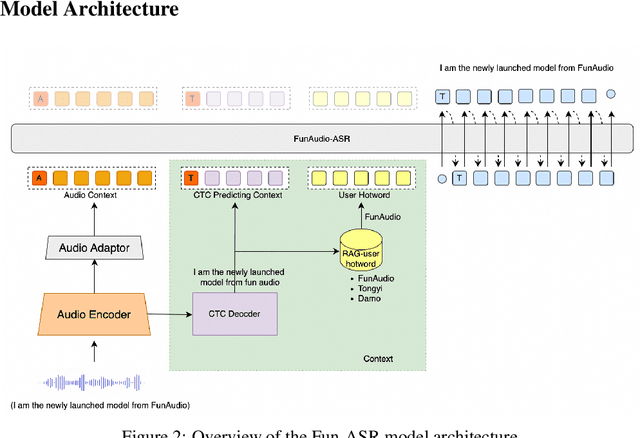
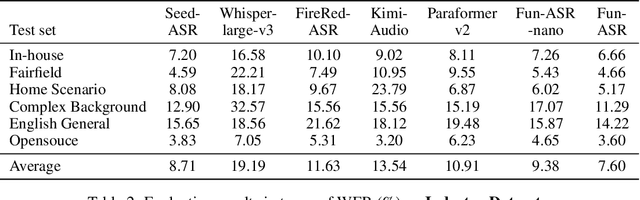
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
Accurate and Reliable Confidence Estimation Based on Non-Autoregressive End-to-End Speech Recognition System
May 25, 2023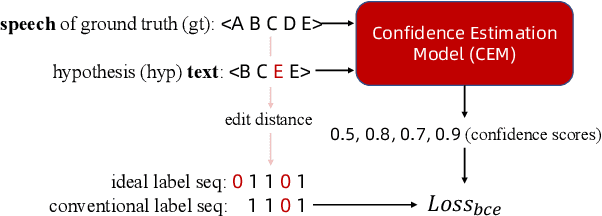
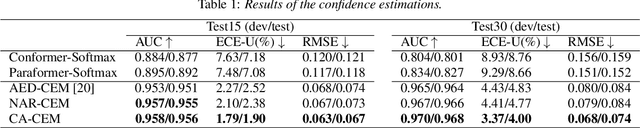
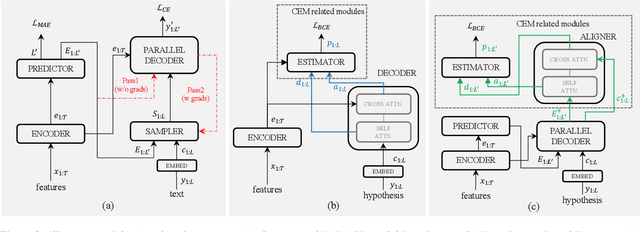
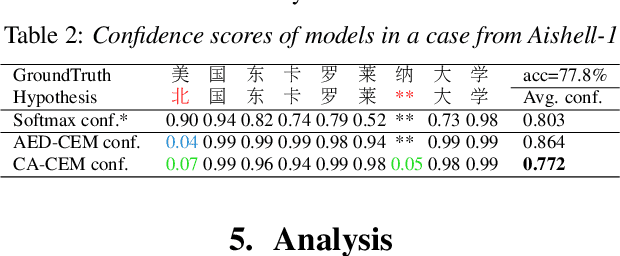
Estimating confidence scores for recognition results is a classic task in ASR field and of vital importance for kinds of downstream tasks and training strategies. Previous end-to-end~(E2E) based confidence estimation models (CEM) predict score sequences of equal length with input transcriptions, leading to unreliable estimation when deletion and insertion errors occur. In this paper we proposed CIF-Aligned confidence estimation model (CA-CEM) to achieve accurate and reliable confidence estimation based on novel non-autoregressive E2E ASR model - Paraformer. CA-CEM utilizes the modeling character of continuous integrate-and-fire (CIF) mechanism to generate token-synchronous acoustic embedding, which solves the estimation failure issue above. We measure the quality of estimation with AUC and RMSE in token level and ECE-U - a proposed metrics in utterance level. CA-CEM gains 24% and 19% relative reduction on ECE-U and also better AUC and RMSE on two test sets. Furthermore, we conduct analysis to explore the potential of CEM for different ASR related usage.
FunASR: A Fundamental End-to-End Speech Recognition Toolkit
May 18, 2023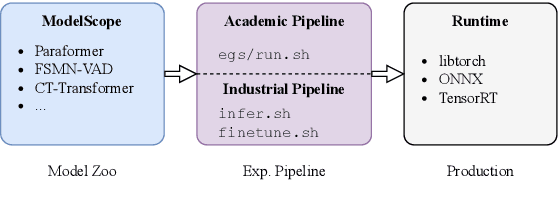

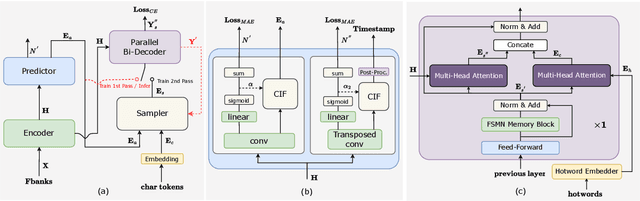
This paper introduces FunASR, an open-source speech recognition toolkit designed to bridge the gap between academic research and industrial applications. FunASR offers models trained on large-scale industrial corpora and the ability to deploy them in applications. The toolkit's flagship model, Paraformer, is a non-autoregressive end-to-end speech recognition model that has been trained on a manually annotated Mandarin speech recognition dataset that contains 60,000 hours of speech. To improve the performance of Paraformer, we have added timestamp prediction and hotword customization capabilities to the standard Paraformer backbone. In addition, to facilitate model deployment, we have open-sourced a voice activity detection model based on the Feedforward Sequential Memory Network (FSMN-VAD) and a text post-processing punctuation model based on the controllable time-delay Transformer (CT-Transformer), both of which were trained on industrial corpora. These functional modules provide a solid foundation for building high-precision long audio speech recognition services. Compared to other models trained on open datasets, Paraformer demonstrates superior performance.
Boundary and Context Aware Training for CIF-based Non-Autoregressive End-to-end ASR
Apr 10, 2021Continuous integrate-and-fire (CIF) based models, which use a soft and monotonic alignment mechanism, have been well applied in non-autoregressive (NAR) speech recognition and achieved competitive performance compared with other NAR methods. However, such an alignment learning strategy may also result in inaccurate acoustic boundary estimation and deceleration in convergence speed. To eliminate these drawbacks and improve performance further, we incorporate an additional connectionist temporal classification (CTC) based alignment loss and a contextual decoder into the CIF-based NAR model. Specifically, we use the CTC spike information to guide the leaning of acoustic boundary and adopt a new contextual decoder to capture the linguistic dependencies within a sentence in the conventional CIF model. Besides, a recently proposed Conformer architecture is also employed to model both local and global acoustic dependencies. Experiments on the open-source Mandarin corpora AISHELL-1 show that the proposed method achieves a comparable character error rate (CER) of 4.9% with only 1/24 latency compared with a state-of-the-art autoregressive (AR) Conformer model.
Simplified Self-Attention for Transformer-based End-to-End Speech Recognition
May 21, 2020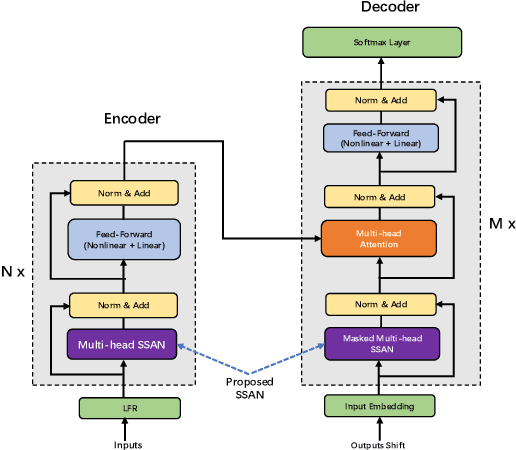
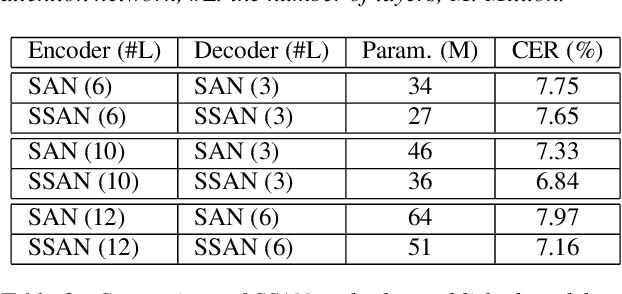

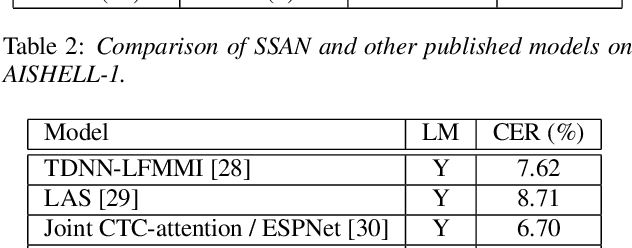
Transformer models have been introduced into end-to-end speech recognition with state-of-the-art performance on various tasks owing to their superiority in modeling long-term dependencies. However, such improvements are usually obtained through the use of very large neural networks. Transformer models mainly include two submodules - position-wise feedforward layers and self-attention (SAN) layers. In this paper, to reduce the model complexity while maintaining good performance, we propose a simplified self-attention (SSAN) layer which employs FSMN memory block instead of projection layers to form query and key vectors for transformer-based end-to-end speech recognition. We evaluate the SSAN-based and the conventional SAN-based transformers on the public AISHELL-1, internal 1000-hour and 20,000-hour large-scale Mandarin tasks. Results show that our proposed SSAN-based transformer model can achieve over 20% relative reduction in model parameters and 6.7% relative CER reduction on the AISHELL-1 task. With impressively 20% parameter reduction, our model shows no loss of recognition performance on the 20,000-hour large-scale task.