 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Efficient Directional and Distance Cues for Regional Speech Separation
Aug 11, 2025In this paper, we introduce a neural network-based method for regional speech separation using a microphone array. This approach leverages novel spatial cues to extract the sound source not only from specified direction but also within defined distance. Specifically, our method employs an improved delay-and-sum technique to obtain directional cues, substantially enhancing the signal from the target direction. We further enhance separation by incorporating the direct-to-reverberant ratio into the input features, enabling the model to better discriminate sources within and beyond a specified distance. Experimental results demonstrate that our proposed method leads to substantial gains across multiple objective metrics. Furthermore, our method achieves state-of-the-art performance on the CHiME-8 MMCSG dataset, which was recorded in real-world conversational scenarios, underscoring its effectiveness for speech separation in practical applications.
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Aug 08, 2025The Speaker Diarization and Recognition (SDR) task aims to predict "who spoke when and what" within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
Speech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
Pushing the Frontiers of Self-Distillation Prototypes Network with Dimension Regularization and Score Normalization
May 20, 2025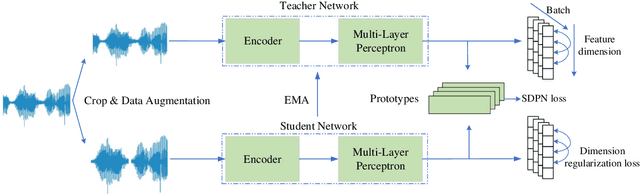
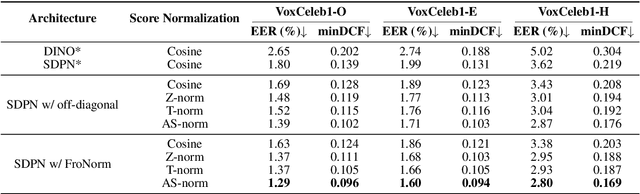

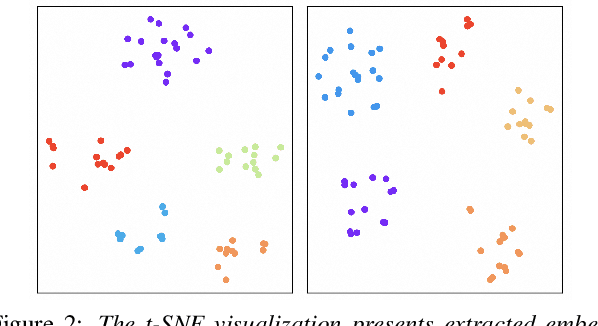
Developing robust speaker verification (SV) systems without speaker labels has been a longstanding challenge. Earlier research has highlighted a considerable performance gap between self-supervised and fully supervised approaches. In this paper, we enhance the non-contrastive self-supervised framework, Self-Distillation Prototypes Network (SDPN), by introducing dimension regularization that explicitly addresses the collapse problem through the application of regularization terms to speaker embeddings. Moreover, we integrate score normalization techniques from fully supervised SV to further bridge the gap toward supervised verification performance. SDPN with dimension regularization and score normalization sets a new state-of-the-art on the VoxCeleb1 speaker verification evaluation benchmark, achieving Equal Error Rate 1.29%, 1.60%, and 2.80% for trial VoxCeleb1-{O,E,H} respectively. These results demonstrate relative improvements of 28.3%, 19.6%, and 22.6% over the current best self-supervised methods, thereby advancing the frontiers of SV technology.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
Integrating Audio, Visual, and Semantic Information for Enhanced Multimodal Speaker Diarization
Aug 22, 2024



Speaker diarization, the process of segmenting an audio stream or transcribed speech content into homogenous partitions based on speaker identity, plays a crucial role in the interpretation and analysis of human speech. Most existing speaker diarization systems rely exclusively on unimodal acoustic information, making the task particularly challenging due to the innate ambiguities of audio signals. Recent studies have made tremendous efforts towards audio-visual or audio-semantic modeling to enhance performance. However, even the incorporation of up to two modalities often falls short in addressing the complexities of spontaneous and unstructured conversations. To exploit more meaningful dialogue patterns, we propose a novel multimodal approach that jointly utilizes audio, visual, and semantic cues to enhance speaker diarization. Our method elegantly formulates the multimodal modeling as a constrained optimization problem. First, we build insights into the visual connections among active speakers and the semantic interactions within spoken content, thereby establishing abundant pairwise constraints. Then we introduce a joint pairwise constraint propagation algorithm to cluster speakers based on these visual and semantic constraints. This integration effectively leverages the complementary strengths of different modalities, refining the affinity estimation between individual speaker embeddings. Extensive experiments conducted on multiple multimodal datasets demonstrate that our approach consistently outperforms state-of-the-art speaker diarization methods.
Self-Distillation Prototypes Network: Learning Robust Speaker Representations without Supervision
Jun 17, 2024Training speaker-discriminative and robust speaker verification systems without explicit speaker labels remains a persisting challenge. In this paper, we propose a new self-supervised speaker verification approach, Self-Distillation Prototypes Network (SDPN), which effectively facilitates self-supervised speaker representation learning. SDPN assigns the representation of the augmented views of an utterance to the same prototypes as the representation of the original view, thereby enabling effective knowledge transfer between the views. Originally, due to the lack of negative pairs in the SDPN training process, the network tends to align positive pairs very closely in the embedding space, a phenomenon known as model collapse. To alleviate this problem, we introduce a diversity regularization term to embeddings in SDPN. Comprehensive experiments on the VoxCeleb datasets demonstrate the superiority of SDPN in self-supervised speaker verification. SDPN sets a new state-of-the-art on the VoxCeleb1 speaker verification evaluation benchmark, achieving Equal Error Rate 1.80%, 1.99%, and 3.62% for trial VoxCeleb1-O, VoxCeleb1-E and VoxCeleb1-H respectively, without using any speaker labels in training.
ERes2NetV2: Boosting Short-Duration Speaker Verification Performance with Computational Efficiency
Jun 04, 2024Speaker verification systems experience significant performance degradation when tasked with short-duration trial recordings. To address this challenge, a multi-scale feature fusion approach has been proposed to effectively capture speaker characteristics from short utterances. Constrained by the model's size, a robust backbone Enhanced Res2Net (ERes2Net) combining global and local feature fusion demonstrates sub-optimal performance in short-duration speaker verification. To further improve the short-duration feature extraction capability of ERes2Net, we expand the channel dimension within each stage. However, this modification also increases the number of model parameters and computational complexity. To alleviate this problem, we propose an improved ERes2NetV2 by pruning redundant structures, ultimately reducing both the model parameters and its computational cost. A range of experiments conducted on the VoxCeleb datasets exhibits the superiority of ERes2NetV2, which achieves EER of 0.61% for the full-duration trial, 0.98% for the 3s-duration trial, and 1.48% for the 2s-duration trial on VoxCeleb1-O, respectively.