 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
Adaptive RISE Control for Dual-Arm Unmanned Aerial Manipulator Systems with Deep Neural Networks
Apr 08, 2025



The unmanned aerial manipulator system, consisting of a multirotor UAV (unmanned aerial vehicle) and a manipulator, has attracted considerable interest from researchers. Nevertheless, the operation of a dual-arm manipulator poses a dynamic challenge, as the CoM (center of mass) of the system changes with manipulator movement, potentially impacting the multirotor UAV. Additionally, unmodeled effects, parameter uncertainties, and external disturbances can significantly degrade control performance, leading to unforeseen dangers. To tackle these issues, this paper proposes a nonlinear adaptive RISE (robust integral of the sign of the error) controller based on DNN (deep neural network). The first step involves establishing the kinematic and dynamic model of the dual-arm aerial manipulator. Subsequently, the adaptive RISE controller is proposed with a DNN feedforward term to effectively address both internal and external challenges. By employing Lyapunov techniques, the asymptotic convergence of the tracking error signals are guaranteed rigorously. Notably, this paper marks a pioneering effort by presenting the first DNN-based adaptive RISE controller design accompanied by a comprehensive stability analysis. To validate the practicality and robustness of the proposed control approach, several groups of actual hardware experiments are conducted. The results confirm the efficacy of the developed methodology in handling real-world scenarios, thereby offering valuable insights into the performance of the dual-arm aerial manipulator system.
OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
Oct 23, 2024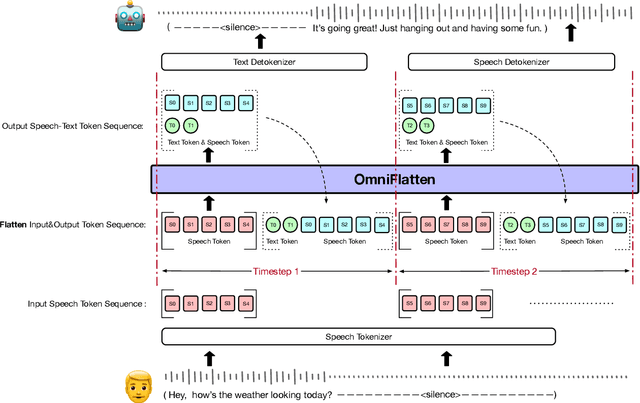
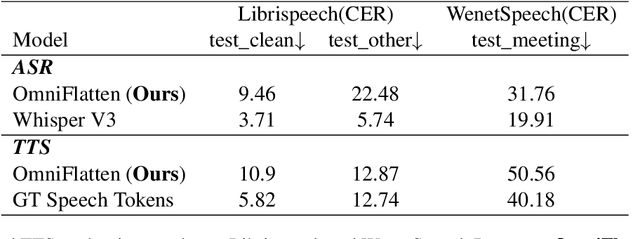
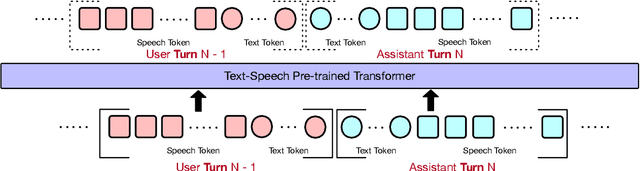
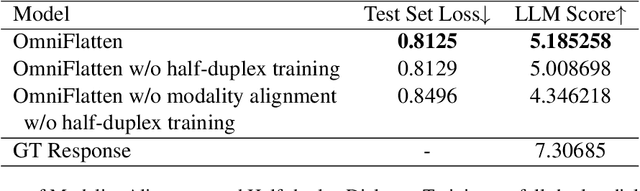
Full-duplex spoken dialogue systems significantly advance over traditional turn-based dialogue systems, as they allow simultaneous bidirectional communication, closely mirroring human-human interactions. However, achieving low latency and natural interactions in full-duplex dialogue systems remains a significant challenge, especially considering human conversation dynamics such as interruptions, backchannels, and overlapping speech. In this paper, we introduce a novel End-to-End GPT-based model OmniFlatten for full-duplex conversation, capable of effectively modeling the complex behaviors inherent to natural conversations with low latency. To achieve full-duplex communication capabilities, we propose a multi-stage post-training scheme that progressively adapts a text-based large language model (LLM) backbone into a speech-text dialogue LLM, capable of generating text and speech in real time, without modifying the architecture of the backbone LLM. The training process comprises three stages: modality alignment, half-duplex dialogue learning, and full-duplex dialogue learning. Throughout all training stages, we standardize the data using a flattening operation, which allows us to unify the training methods and the model architecture across different modalities and tasks. Our approach offers a straightforward modeling technique and a promising research direction for developing efficient and natural end-to-end full-duplex spoken dialogue systems. Audio samples of dialogues generated by OmniFlatten can be found at this web site (https://omniflatten.github.io/).
Recording for Eyes, Not Echoing to Ears: Contextualized Spoken-to-Written Conversion of ASR Transcripts
Aug 19, 2024
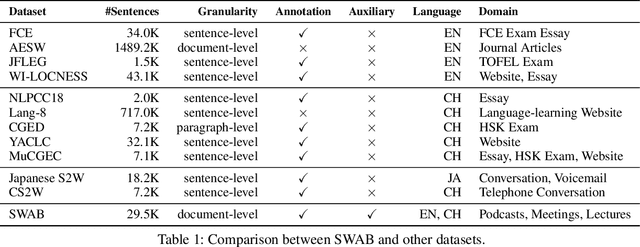
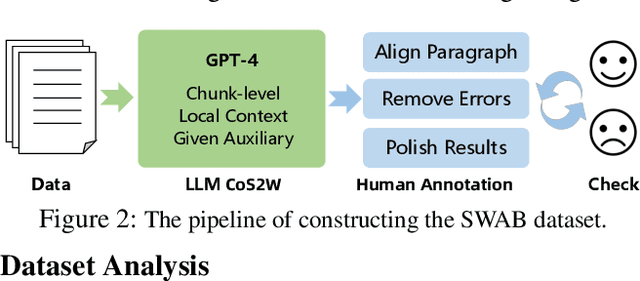
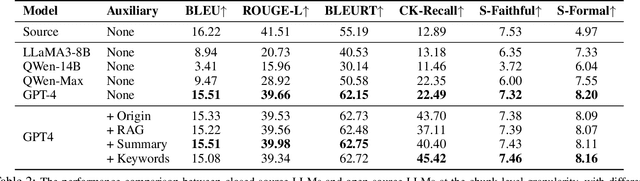
Automatic Speech Recognition (ASR) transcripts exhibit recognition errors and various spoken language phenomena such as disfluencies, ungrammatical sentences, and incomplete sentences, hence suffering from poor readability. To improve readability, we propose a Contextualized Spoken-to-Written conversion (CoS2W) task to address ASR and grammar errors and also transfer the informal text into the formal style with content preserved, utilizing contexts and auxiliary information. This task naturally matches the in-context learning capabilities of Large Language Models (LLMs). To facilitate comprehensive comparisons of various LLMs, we construct a document-level Spoken-to-Written conversion of ASR Transcripts Benchmark (SWAB) dataset. Using SWAB, we study the impact of different granularity levels on the CoS2W performance, and propose methods to exploit contexts and auxiliary information to enhance the outputs. Experimental results reveal that LLMs have the potential to excel in the CoS2W task, particularly in grammaticality and formality, our methods achieve effective understanding of contexts and auxiliary information by LLMs. We further investigate the effectiveness of using LLMs as evaluators and find that LLM evaluators show strong correlations with human evaluations on rankings of faithfulness and formality, which validates the reliability of LLM evaluators for the CoS2W task.
Multimodal Fusion and Coherence Modeling for Video Topic Segmentation
Aug 01, 2024
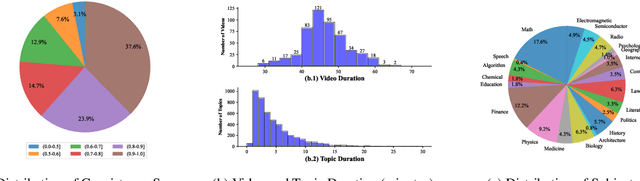
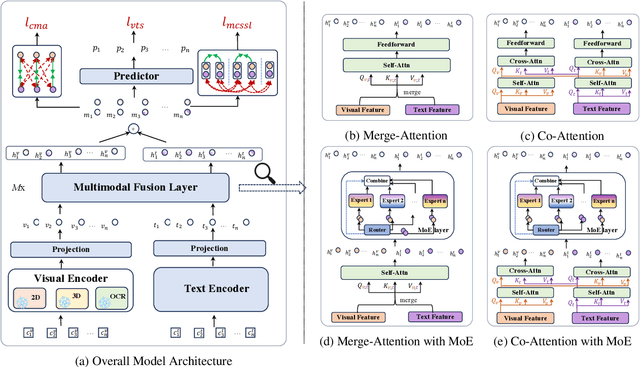
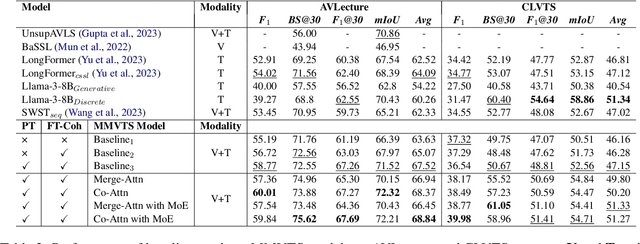
The video topic segmentation (VTS) task segments videos into intelligible, non-overlapping topics, facilitating efficient comprehension of video content and quick access to specific content. VTS is also critical to various downstream video understanding tasks. Traditional VTS methods using shallow features or unsupervised approaches struggle to accurately discern the nuances of topical transitions. Recently, supervised approaches have achieved superior performance on video action or scene segmentation over unsupervised approaches. In this work, we improve supervised VTS by thoroughly exploring multimodal fusion and multimodal coherence modeling. Specifically, (1) we enhance multimodal fusion by exploring different architectures using cross-attention and mixture of experts. (2) To generally strengthen multimodality alignment and fusion, we pre-train and fine-tune the model with multimodal contrastive learning. (3) We propose a new pre-training task tailored for the VTS task, and a novel fine-tuning task for enhancing multimodal coherence modeling for VTS. We evaluate the proposed approaches on educational videos, in the form of lectures, due to the vital role of topic segmentation of educational videos in boosting learning experiences. Additionally, we introduce a large-scale Chinese lecture video dataset to augment the existing English corpus, promoting further research in VTS. Experiments on both English and Chinese lecture datasets demonstrate that our model achieves superior VTS performance compared to competitive unsupervised and supervised baselines.
Skip-Layer Attention: Bridging Abstract and Detailed Dependencies in Transformers
Jun 17, 2024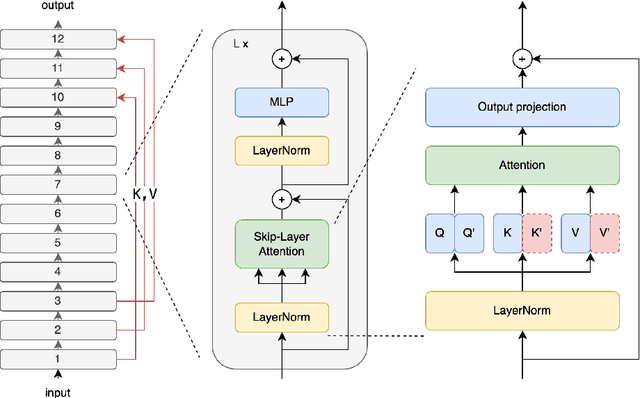
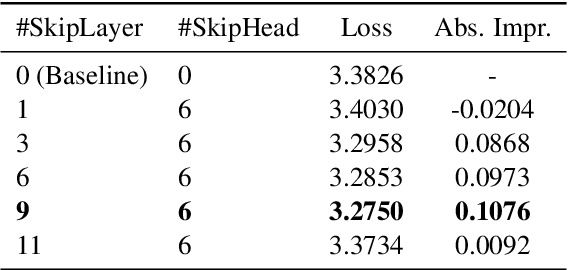

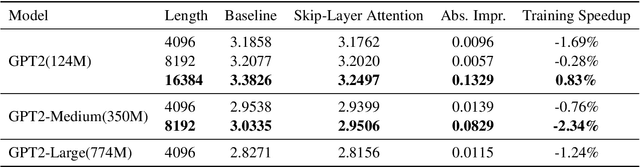
The Transformer architecture has significantly advanced deep learning, particularly in natural language processing, by effectively managing long-range dependencies. However, as the demand for understanding complex relationships grows, refining the Transformer's architecture becomes critical. This paper introduces Skip-Layer Attention (SLA) to enhance Transformer models by enabling direct attention between non-adjacent layers. This method improves the model's ability to capture dependencies between high-level abstract features and low-level details. By facilitating direct attention between these diverse feature levels, our approach overcomes the limitations of current Transformers, which often rely on suboptimal intra-layer attention. Our implementation extends the Transformer's functionality by enabling queries in a given layer to interact with keys and values from both the current layer and one preceding layer, thus enhancing the diversity of multi-head attention without additional computational burden. Extensive experiments demonstrate that our enhanced Transformer model achieves superior performance in language modeling tasks, highlighting the effectiveness of our skip-layer attention mechanism.
Loss Masking Is Not Needed in Decoder-only Transformer for Discrete-token Based ASR
Nov 08, 2023



Recently, unified speech-text models, such as SpeechGPT, VioLA, and AudioPaLM, have achieved remarkable performance on speech tasks. These models convert continuous speech signals into discrete tokens (speech discretization) and merge text and speech tokens into a shared vocabulary. Then they train a single decoder-only Transformer on a mixture of speech tasks. Specifically, all these models utilize Loss Masking on the input speech tokens for the ASR task, which means that these models do not explicitly model the dependency between the speech tokens. In this paper, we attempt to model the sequence of speech tokens in an autoregressive manner like text. However, we find that applying the conventional cross-entropy loss on input speech tokens does not consistently improve the ASR performance over Loss Masking. Therefore, we propose a novel approach denoted Smoothed Label Distillation (SLD), which introduces a KL divergence loss with smoothed labels on the input speech tokens to effectively model speech tokens. Experiments demonstrate that our SLD approach alleviates the limitations of the cross-entropy loss and consistently outperforms Loss Masking for decoder-only Transformer based ASR using different speech discretization methods.
Improving Long Document Topic Segmentation Models With Enhanced Coherence Modeling
Oct 23, 2023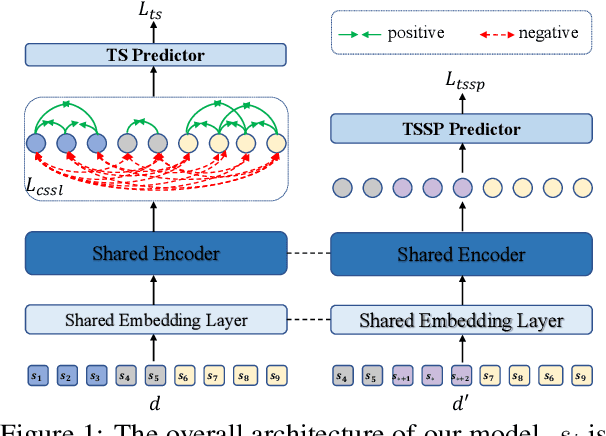
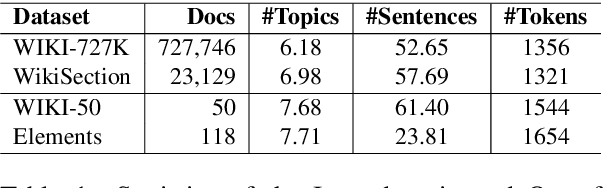

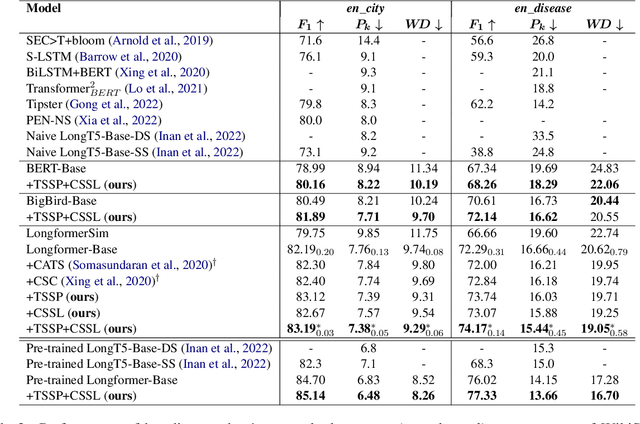
Topic segmentation is critical for obtaining structured documents and improving downstream tasks such as information retrieval. Due to its ability of automatically exploring clues of topic shift from abundant labeled data, recent supervised neural models have greatly promoted the development of long document topic segmentation, but leaving the deeper relationship between coherence and topic segmentation underexplored. Therefore, this paper enhances the ability of supervised models to capture coherence from both logical structure and semantic similarity perspectives to further improve the topic segmentation performance, proposing Topic-aware Sentence Structure Prediction (TSSP) and Contrastive Semantic Similarity Learning (CSSL). Specifically, the TSSP task is proposed to force the model to comprehend structural information by learning the original relations between adjacent sentences in a disarrayed document, which is constructed by jointly disrupting the original document at topic and sentence levels. Moreover, we utilize inter- and intra-topic information to construct contrastive samples and design the CSSL objective to ensure that the sentences representations in the same topic have higher similarity, while those in different topics are less similar. Extensive experiments show that the Longformer with our approach significantly outperforms old state-of-the-art (SOTA) methods. Our approach improve $F_1$ of old SOTA by 3.42 (73.74 -> 77.16) and reduces $P_k$ by 1.11 points (15.0 -> 13.89) on WIKI-727K and achieves an average relative reduction of 4.3% on $P_k$ on WikiSection. The average relative $P_k$ drop of 8.38% on two out-of-domain datasets also demonstrates the robustness of our approach.
Ditto: A Simple and Efficient Approach to Improve Sentence Embeddings
May 18, 2023



Prior studies diagnose the anisotropy problem in sentence representations from pre-trained language models, e.g., BERT, without fine-tuning. Our analysis reveals that the sentence embeddings from BERT suffer from a bias towards uninformative words, limiting the performance in semantic textual similarity (STS) tasks. To address this bias, we propose a simple and efficient unsupervised approach, Diagonal Attention Pooling (Ditto), which weights words with model-based importance estimations and computes the weighted average of word representations from pre-trained models as sentence embeddings. Ditto can be easily applied to any pre-trained language model as a postprocessing operation. Compared to prior sentence embedding approaches, Ditto does not add parameters nor requires any learning. Empirical evaluations demonstrate that our proposed Ditto can alleviate the anisotropy problem and improve various pre-trained models on STS tasks.
MUG: A General Meeting Understanding and Generation Benchmark
Mar 27, 2023Listening to long video/audio recordings from video conferencing and online courses for acquiring information is extremely inefficient. Even after ASR systems transcribe recordings into long-form spoken language documents, reading ASR transcripts only partly speeds up seeking information. It has been observed that a range of NLP applications, such as keyphrase extraction, topic segmentation, and summarization, significantly improve users' efficiency in grasping important information. The meeting scenario is among the most valuable scenarios for deploying these spoken language processing (SLP) capabilities. However, the lack of large-scale public meeting datasets annotated for these SLP tasks severely hinders their advancement. To prompt SLP advancement, we establish a large-scale general Meeting Understanding and Generation Benchmark (MUG) to benchmark the performance of a wide range of SLP tasks, including topic segmentation, topic-level and session-level extractive summarization and topic title generation, keyphrase extraction, and action item detection. To facilitate the MUG benchmark, we construct and release a large-scale meeting dataset for comprehensive long-form SLP development, the AliMeeting4MUG Corpus, which consists of 654 recorded Mandarin meeting sessions with diverse topic coverage, with manual annotations for SLP tasks on manual transcripts of meeting recordings. To the best of our knowledge, the AliMeeting4MUG Corpus is so far the largest meeting corpus in scale and facilitates most SLP tasks. In this paper, we provide a detailed introduction of this corpus, SLP tasks and evaluation methods, baseline systems and their performance.