 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion and Coherence Modeling for Video Topic Segmentation
Paper and Code
Aug 01, 2024
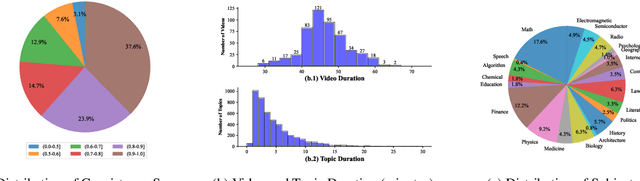
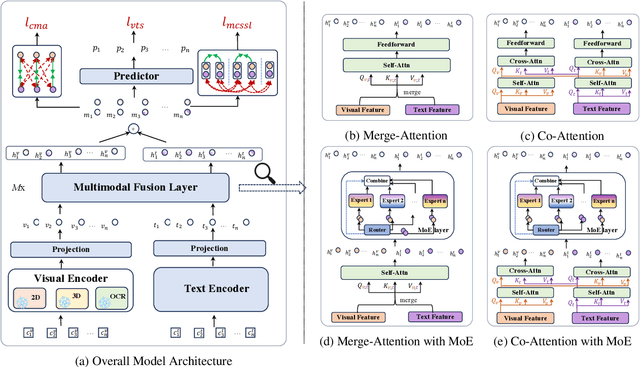
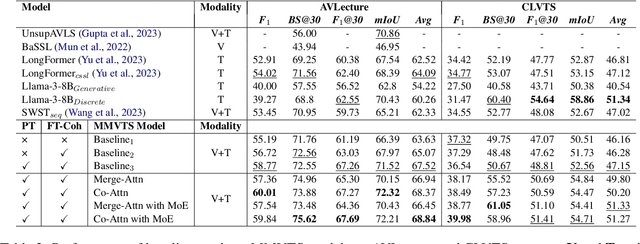
The video topic segmentation (VTS) task segments videos into intelligible, non-overlapping topics, facilitating efficient comprehension of video content and quick access to specific content. VTS is also critical to various downstream video understanding tasks. Traditional VTS methods using shallow features or unsupervised approaches struggle to accurately discern the nuances of topical transitions. Recently, supervised approaches have achieved superior performance on video action or scene segmentation over unsupervised approaches. In this work, we improve supervised VTS by thoroughly exploring multimodal fusion and multimodal coherence modeling. Specifically, (1) we enhance multimodal fusion by exploring different architectures using cross-attention and mixture of experts. (2) To generally strengthen multimodality alignment and fusion, we pre-train and fine-tune the model with multimodal contrastive learning. (3) We propose a new pre-training task tailored for the VTS task, and a novel fine-tuning task for enhancing multimodal coherence modeling for VTS. We evaluate the proposed approaches on educational videos, in the form of lectures, due to the vital role of topic segmentation of educational videos in boosting learning experiences. Additionally, we introduce a large-scale Chinese lecture video dataset to augment the existing English corpus, promoting further research in VTS. Experiments on both English and Chinese lecture datasets demonstrate that our model achieves superior VTS performance compared to competitive unsupervised and supervised baselines.