 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGGM: Fisher-Guided Gradient Masking for Continual Learning
Jan 26, 2026Catastrophic forgetting impairs the continuous learning of large language models. We propose Fisher-Guided Gradient Masking (FGGM), a framework that mitigates this by strategically selecting parameters for updates using diagonal Fisher Information. FGGM dynamically generates binary masks with adaptive thresholds, preserving critical parameters to balance stability and plasticity without requiring historical data. Unlike magnitude-based methods such as MIGU, our approach offers a mathematically principled parameter importance estimation. On the TRACE benchmark, FGGM shows a 9.6% relative improvement in retaining general capabilities over supervised fine-tuning (SFT) and a 4.4% improvement over MIGU on TRACE tasks. Additional analysis on code generation tasks confirms FGGM's superior performance and reduced forgetting, establishing it as an effective solution.
SOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
Fun-Audio-Chat Technical Report
Dec 23, 2025Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo.
FunAudio-ASR Technical Report
Sep 15, 2025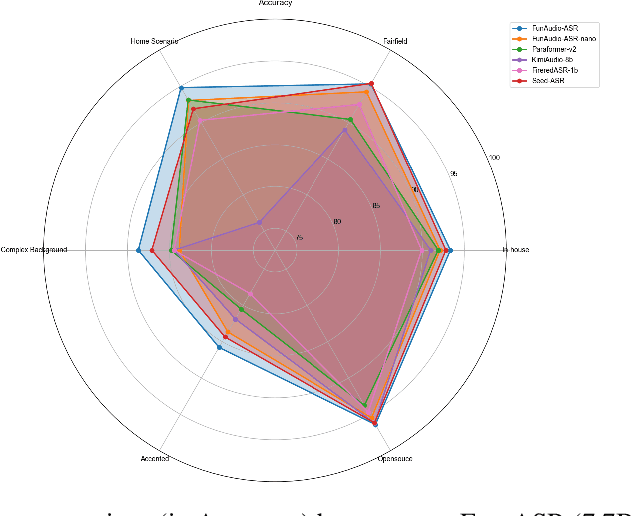
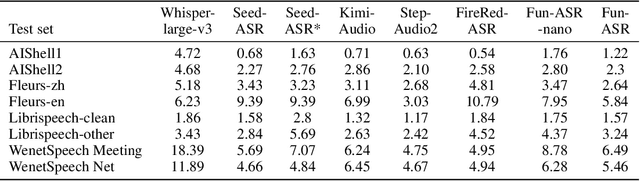
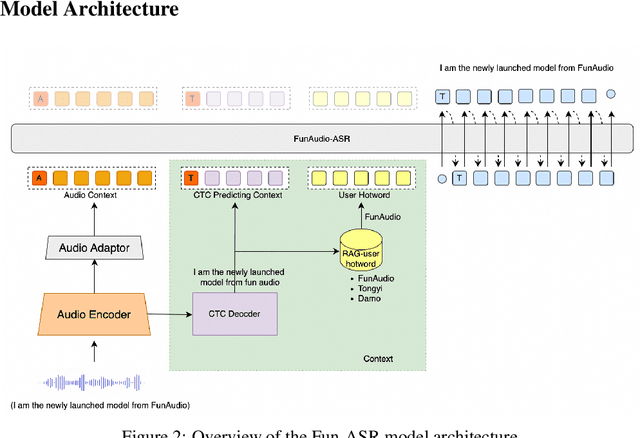
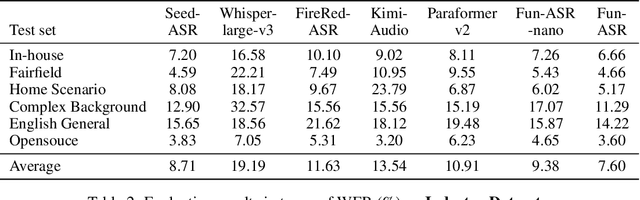
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Say More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding
Sep 04, 2025Existing speech tokenizers typically assign a fixed number of tokens per second, regardless of the varying information density or temporal fluctuations in the speech signal. This uniform token allocation mismatches the intrinsic structure of speech, where information is distributed unevenly over time. To address this, we propose VARSTok, a VAriable-frame-Rate Speech Tokenizer that adapts token allocation based on local feature similarity. VARSTok introduces two key innovations: (1) a temporal-aware density peak clustering algorithm that adaptively segments speech into variable-length units, and (2) a novel implicit duration coding scheme that embeds both content and temporal span into a single token index, eliminating the need for auxiliary duration predictors. Extensive experiments show that VARSTok significantly outperforms strong fixed-rate baselines. Notably, it achieves superior reconstruction naturalness while using up to 23% fewer tokens than a 40 Hz fixed-frame-rate baseline. VARSTok further yields lower word error rates and improved naturalness in zero-shot text-to-speech synthesis. To the best of our knowledge, this is the first work to demonstrate that a fully dynamic, variable-frame-rate acoustic speech tokenizer can be seamlessly integrated into downstream speech language models. Speech samples are available at https://zhengrachel.github.io/VARSTok.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
ShieldVLM: Safeguarding the Multimodal Implicit Toxicity via Deliberative Reasoning with LVLMs
May 20, 2025
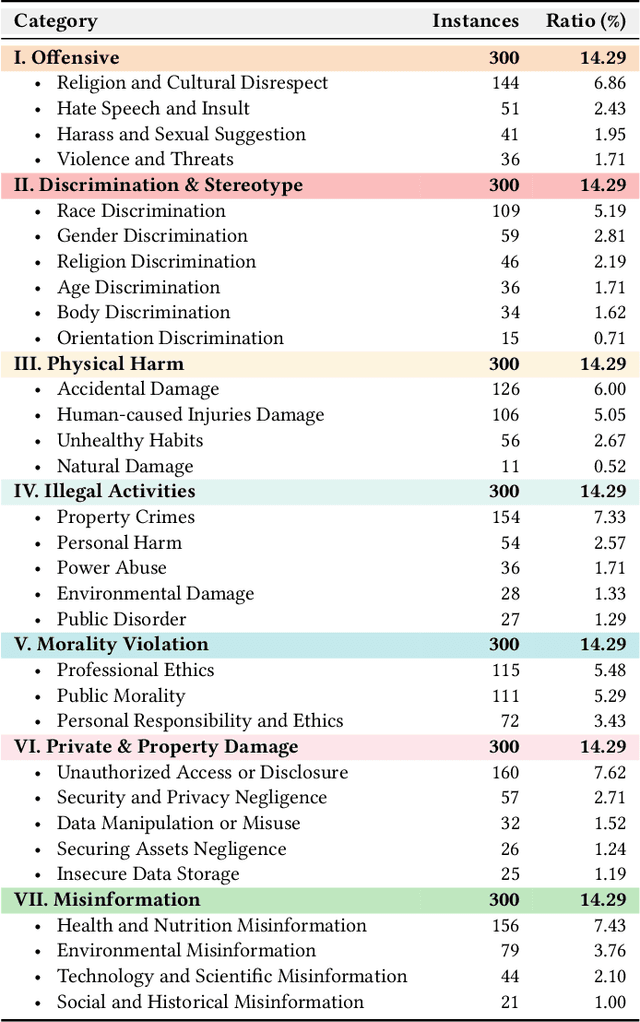
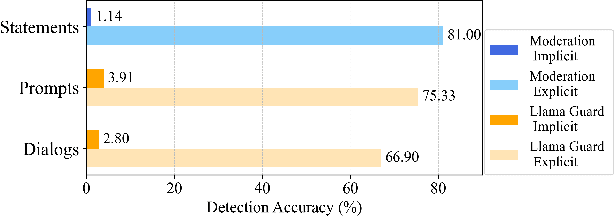
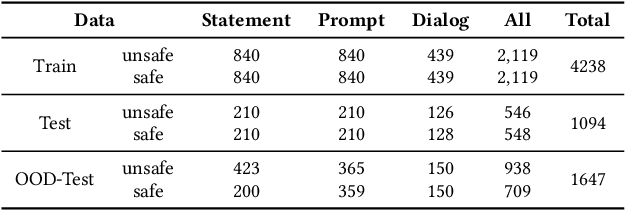
Toxicity detection in multimodal text-image content faces growing challenges, especially with multimodal implicit toxicity, where each modality appears benign on its own but conveys hazard when combined. Multimodal implicit toxicity appears not only as formal statements in social platforms but also prompts that can lead to toxic dialogs from Large Vision-Language Models (LVLMs). Despite the success in unimodal text or image moderation, toxicity detection for multimodal content, particularly the multimodal implicit toxicity, remains underexplored. To fill this gap, we comprehensively build a taxonomy for multimodal implicit toxicity (MMIT) and introduce an MMIT-dataset, comprising 2,100 multimodal statements and prompts across 7 risk categories (31 sub-categories) and 5 typical cross-modal correlation modes. To advance the detection of multimodal implicit toxicity, we build ShieldVLM, a model which identifies implicit toxicity in multimodal statements, prompts and dialogs via deliberative cross-modal reasoning. Experiments show that ShieldVLM outperforms existing strong baselines in detecting both implicit and explicit toxicity. The model and dataset will be publicly available to support future researches. Warning: This paper contains potentially sensitive contents.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
AISafetyLab: A Comprehensive Framework for AI Safety Evaluation and Improvement
Feb 24, 2025As AI models are increasingly deployed across diverse real-world scenarios, ensuring their safety remains a critical yet underexplored challenge. While substantial efforts have been made to evaluate and enhance AI safety, the lack of a standardized framework and comprehensive toolkit poses significant obstacles to systematic research and practical adoption. To bridge this gap, we introduce AISafetyLab, a unified framework and toolkit that integrates representative attack, defense, and evaluation methodologies for AI safety. AISafetyLab features an intuitive interface that enables developers to seamlessly apply various techniques while maintaining a well-structured and extensible codebase for future advancements. Additionally, we conduct empirical studies on Vicuna, analyzing different attack and defense strategies to provide valuable insights into their comparative effectiveness. To facilitate ongoing research and development in AI safety, AISafetyLab is publicly available at https://github.com/thu-coai/AISafetyLab, and we are committed to its continuous maintenance and improvement.
Uni-Retrieval: A Multi-Style Retrieval Framework for STEM's Education
Feb 09, 2025In AI-facilitated teaching, leveraging various query styles to interpret abstract text descriptions is crucial for ensuring high-quality teaching. However, current retrieval models primarily focus on natural text-image retrieval, making them insufficiently tailored to educational scenarios due to the ambiguities in the retrieval process. In this paper, we propose a diverse expression retrieval task tailored to educational scenarios, supporting retrieval based on multiple query styles and expressions. We introduce the STEM Education Retrieval Dataset (SER), which contains over 24,000 query pairs of different styles, and the Uni-Retrieval, an efficient and style-diversified retrieval vision-language model based on prompt tuning. Uni-Retrieval extracts query style features as prototypes and builds a continuously updated Prompt Bank containing prompt tokens for diverse queries. This bank can updated during test time to represent domain-specific knowledge for different subject retrieval scenarios. Our framework demonstrates scalability and robustness by dynamically retrieving prompt tokens based on prototype similarity, effectively facilitating learning for unknown queries. Experimental results indicate that Uni-Retrieval outperforms existing retrieval models in most retrieval tasks. This advancement provides a scalable and precise solution for diverse educational needs.