 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
E-chat: Emotion-sensitive Spoken Dialogue System with Large Language Models
Jan 06, 2024



This study focuses on emotion-sensitive spoken dialogue in human-machine speech interaction. With the advancement of Large Language Models (LLMs), dialogue systems can handle multimodal data, including audio. Recent models have enhanced the understanding of complex audio signals through the integration of various audio events. However, they are unable to generate appropriate responses based on emotional speech. To address this, we introduce the Emotional chat Model (E-chat), a novel spoken dialogue system capable of comprehending and responding to emotions conveyed from speech. This model leverages an emotion embedding extracted by a speech encoder, combined with LLMs, enabling it to respond according to different emotional contexts. Additionally, we introduce the E-chat200 dataset, designed explicitly for emotion-sensitive spoken dialogue. In various evaluation metrics, E-chat consistently outperforms baseline LLMs, demonstrating its potential in emotional comprehension and human-machine interaction.
FunASR: A Fundamental End-to-End Speech Recognition Toolkit
May 18, 2023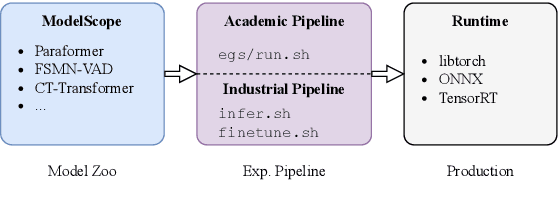

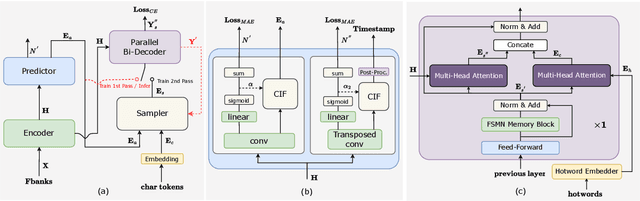
This paper introduces FunASR, an open-source speech recognition toolkit designed to bridge the gap between academic research and industrial applications. FunASR offers models trained on large-scale industrial corpora and the ability to deploy them in applications. The toolkit's flagship model, Paraformer, is a non-autoregressive end-to-end speech recognition model that has been trained on a manually annotated Mandarin speech recognition dataset that contains 60,000 hours of speech. To improve the performance of Paraformer, we have added timestamp prediction and hotword customization capabilities to the standard Paraformer backbone. In addition, to facilitate model deployment, we have open-sourced a voice activity detection model based on the Feedforward Sequential Memory Network (FSMN-VAD) and a text post-processing punctuation model based on the controllable time-delay Transformer (CT-Transformer), both of which were trained on industrial corpora. These functional modules provide a solid foundation for building high-precision long audio speech recognition services. Compared to other models trained on open datasets, Paraformer demonstrates superior performance.
Discriminative Self-training for Punctuation Prediction
Apr 21, 2021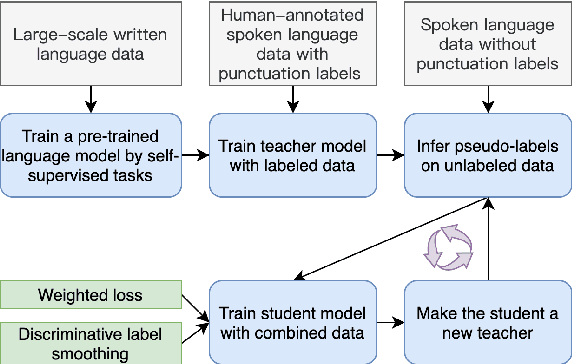
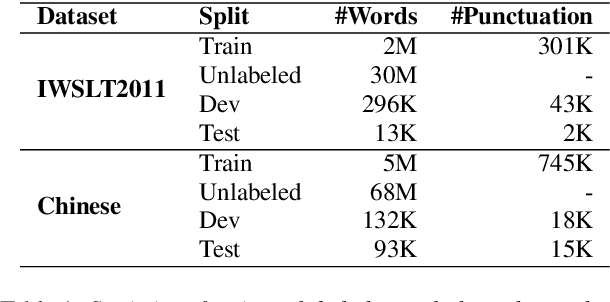

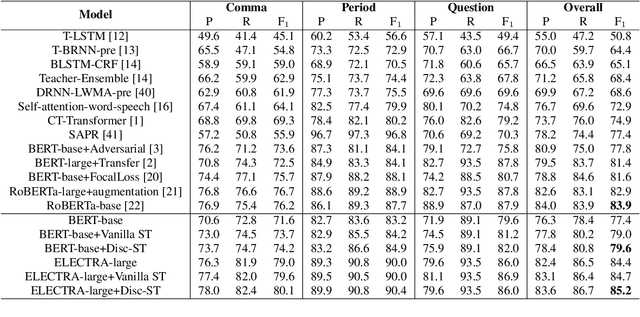
Punctuation prediction for automatic speech recognition (ASR) output transcripts plays a crucial role for improving the readability of the ASR transcripts and for improving the performance of downstream natural language processing applications. However, achieving good performance on punctuation prediction often requires large amounts of labeled speech transcripts, which is expensive and laborious. In this paper, we propose a Discriminative Self-Training approach with weighted loss and discriminative label smoothing to exploit unlabeled speech transcripts. Experimental results on the English IWSLT2011 benchmark test set and an internal Chinese spoken language dataset demonstrate that the proposed approach achieves significant improvement on punctuation prediction accuracy over strong baselines including BERT, RoBERTa, and ELECTRA models. The proposed Discriminative Self-Training approach outperforms the vanilla self-training approach. We establish a new state-of-the-art (SOTA) on the IWSLT2011 test set, outperforming the current SOTA model by 1.3% absolute gain on F$_1$.
Controllable Time-Delay Transformer for Real-Time Punctuation Prediction and Disfluency Detection
Mar 03, 2020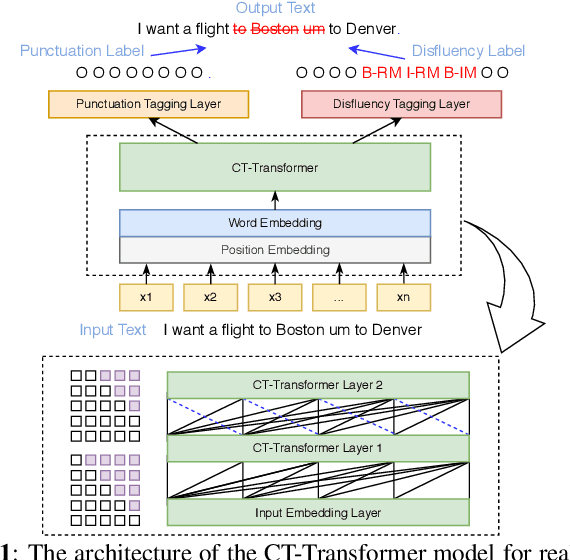
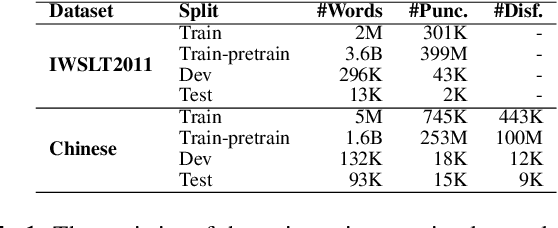
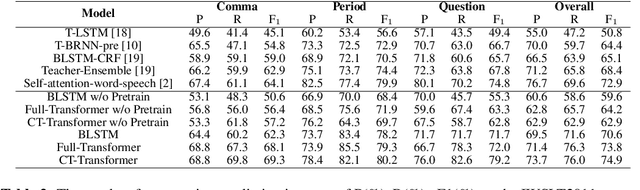
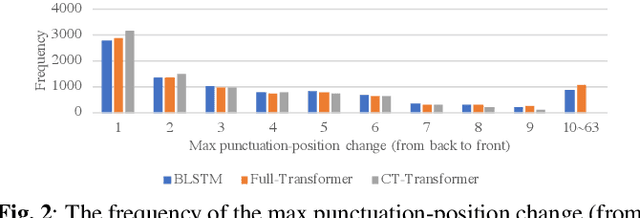
With the increased applications of automatic speech recognition (ASR) in recent years, it is essential to automatically insert punctuation marks and remove disfluencies in transcripts, to improve the readability of the transcripts as well as the performance of subsequent applications, such as machine translation, dialogue systems, and so forth. In this paper, we propose a Controllable Time-delay Transformer (CT-Transformer) model that jointly completes the punctuation prediction and disfluency detection tasks in real time. The CT-Transformer model facilitates freezing partial outputs with controllable time delay to fulfill the real-time constraints in partial decoding required by subsequent applications. We further propose a fast decoding strategy to minimize latency while maintaining competitive performance. Experimental results on the IWSLT2011 benchmark dataset and an in-house Chinese annotated dataset demonstrate that the proposed approach outperforms the previous state-of-the-art models on F-scores and achieves a competitive inference speed.