 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGGM: Fisher-Guided Gradient Masking for Continual Learning
Jan 26, 2026Catastrophic forgetting impairs the continuous learning of large language models. We propose Fisher-Guided Gradient Masking (FGGM), a framework that mitigates this by strategically selecting parameters for updates using diagonal Fisher Information. FGGM dynamically generates binary masks with adaptive thresholds, preserving critical parameters to balance stability and plasticity without requiring historical data. Unlike magnitude-based methods such as MIGU, our approach offers a mathematically principled parameter importance estimation. On the TRACE benchmark, FGGM shows a 9.6% relative improvement in retaining general capabilities over supervised fine-tuning (SFT) and a 4.4% improvement over MIGU on TRACE tasks. Additional analysis on code generation tasks confirms FGGM's superior performance and reduced forgetting, establishing it as an effective solution.
Fun-Audio-Chat Technical Report
Dec 23, 2025Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo.
FunAudio-ASR Technical Report
Sep 15, 2025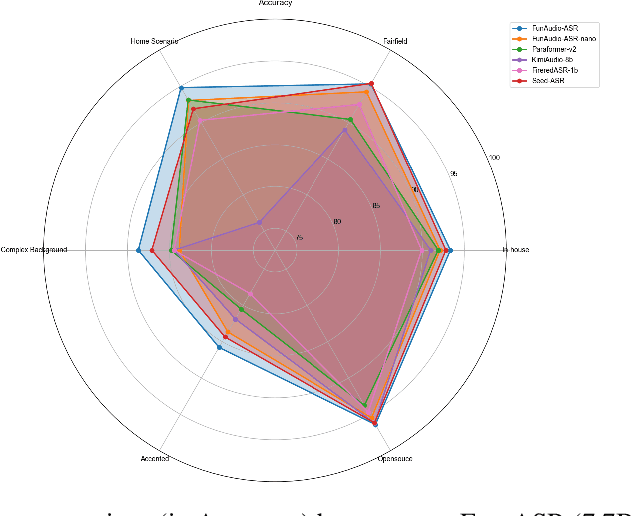
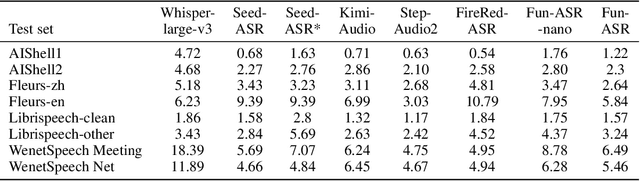
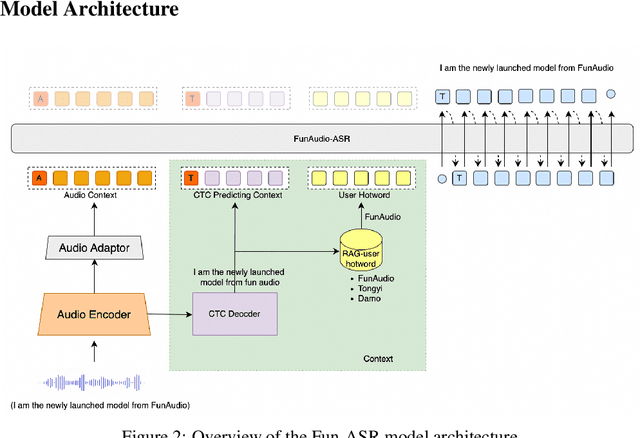
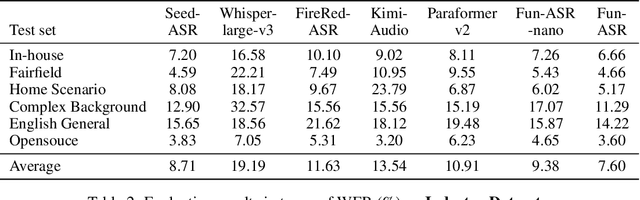
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Say More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding
Sep 04, 2025Existing speech tokenizers typically assign a fixed number of tokens per second, regardless of the varying information density or temporal fluctuations in the speech signal. This uniform token allocation mismatches the intrinsic structure of speech, where information is distributed unevenly over time. To address this, we propose VARSTok, a VAriable-frame-Rate Speech Tokenizer that adapts token allocation based on local feature similarity. VARSTok introduces two key innovations: (1) a temporal-aware density peak clustering algorithm that adaptively segments speech into variable-length units, and (2) a novel implicit duration coding scheme that embeds both content and temporal span into a single token index, eliminating the need for auxiliary duration predictors. Extensive experiments show that VARSTok significantly outperforms strong fixed-rate baselines. Notably, it achieves superior reconstruction naturalness while using up to 23% fewer tokens than a 40 Hz fixed-frame-rate baseline. VARSTok further yields lower word error rates and improved naturalness in zero-shot text-to-speech synthesis. To the best of our knowledge, this is the first work to demonstrate that a fully dynamic, variable-frame-rate acoustic speech tokenizer can be seamlessly integrated into downstream speech language models. Speech samples are available at https://zhengrachel.github.io/VARSTok.
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Aug 08, 2025The Speaker Diarization and Recognition (SDR) task aims to predict "who spoke when and what" within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
Pushing the Frontiers of Self-Distillation Prototypes Network with Dimension Regularization and Score Normalization
May 20, 2025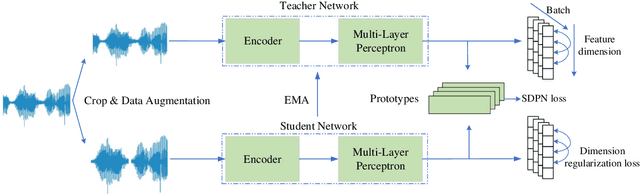
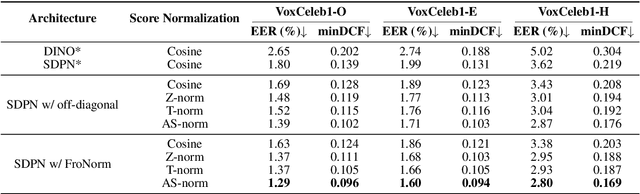

Developing robust speaker verification (SV) systems without speaker labels has been a longstanding challenge. Earlier research has highlighted a considerable performance gap between self-supervised and fully supervised approaches. In this paper, we enhance the non-contrastive self-supervised framework, Self-Distillation Prototypes Network (SDPN), by introducing dimension regularization that explicitly addresses the collapse problem through the application of regularization terms to speaker embeddings. Moreover, we integrate score normalization techniques from fully supervised SV to further bridge the gap toward supervised verification performance. SDPN with dimension regularization and score normalization sets a new state-of-the-art on the VoxCeleb1 speaker verification evaluation benchmark, achieving Equal Error Rate 1.29%, 1.60%, and 2.80% for trial VoxCeleb1-{O,E,H} respectively. These results demonstrate relative improvements of 28.3%, 19.6%, and 22.6% over the current best self-supervised methods, thereby advancing the frontiers of SV technology.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024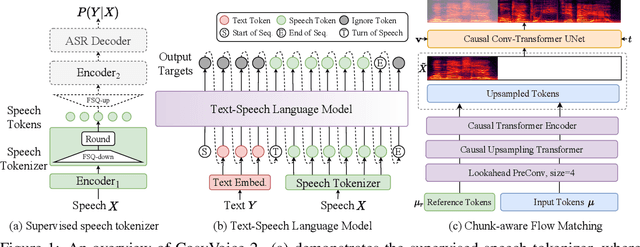


In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
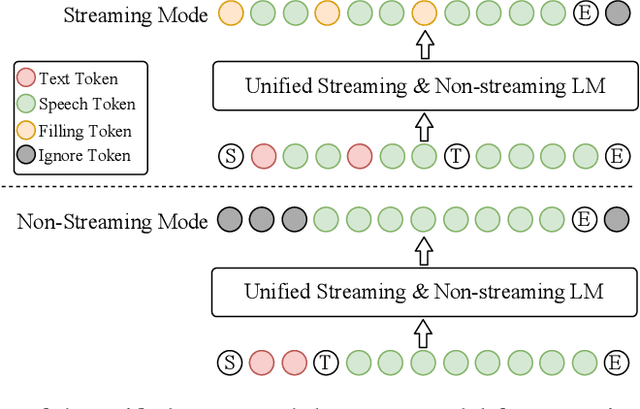
Oct 23, 2024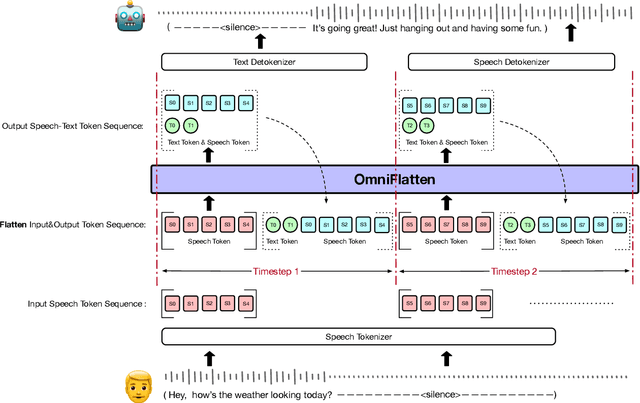
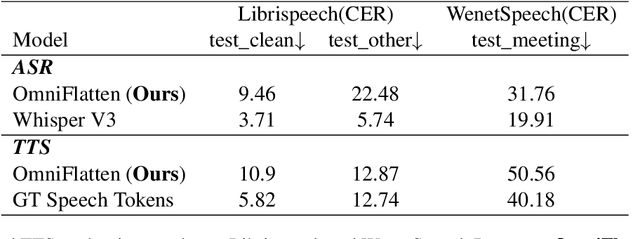
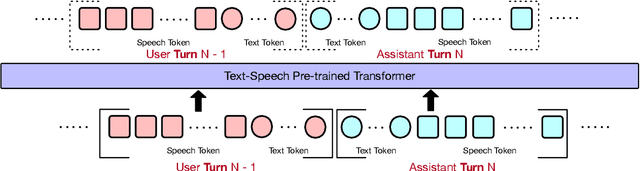
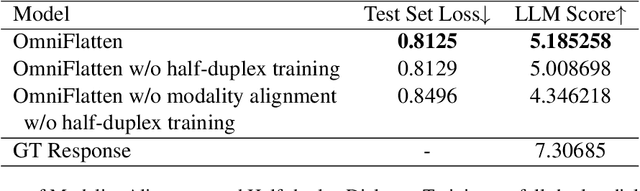
Full-duplex spoken dialogue systems significantly advance over traditional turn-based dialogue systems, as they allow simultaneous bidirectional communication, closely mirroring human-human interactions. However, achieving low latency and natural interactions in full-duplex dialogue systems remains a significant challenge, especially considering human conversation dynamics such as interruptions, backchannels, and overlapping speech. In this paper, we introduce a novel End-to-End GPT-based model OmniFlatten for full-duplex conversation, capable of effectively modeling the complex behaviors inherent to natural conversations with low latency. To achieve full-duplex communication capabilities, we propose a multi-stage post-training scheme that progressively adapts a text-based large language model (LLM) backbone into a speech-text dialogue LLM, capable of generating text and speech in real time, without modifying the architecture of the backbone LLM. The training process comprises three stages: modality alignment, half-duplex dialogue learning, and full-duplex dialogue learning. Throughout all training stages, we standardize the data using a flattening operation, which allows us to unify the training methods and the model architecture across different modalities and tasks. Our approach offers a straightforward modeling technique and a promising research direction for developing efficient and natural end-to-end full-duplex spoken dialogue systems. Audio samples of dialogues generated by OmniFlatten can be found at this web site (https://omniflatten.github.io/).