 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFun-Audio-Chat Technical Report
Dec 23, 2025Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo.
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Aug 08, 2025The Speaker Diarization and Recognition (SDR) task aims to predict "who spoke when and what" within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
Oct 23, 2024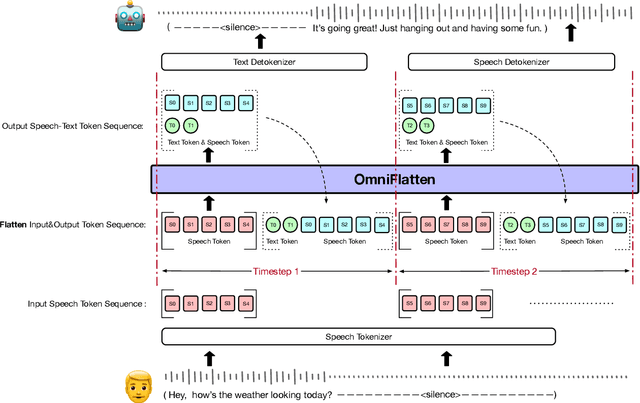
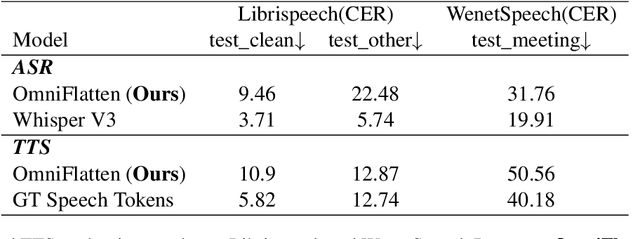
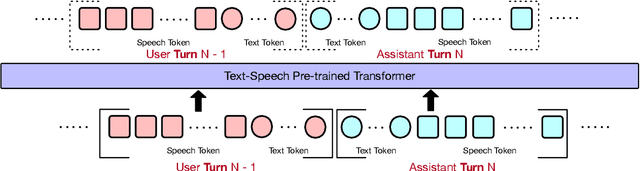
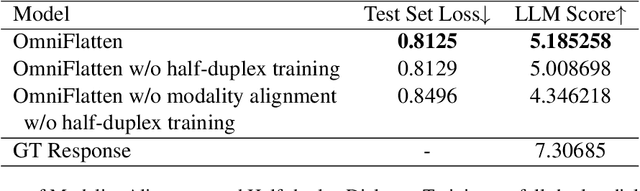
Full-duplex spoken dialogue systems significantly advance over traditional turn-based dialogue systems, as they allow simultaneous bidirectional communication, closely mirroring human-human interactions. However, achieving low latency and natural interactions in full-duplex dialogue systems remains a significant challenge, especially considering human conversation dynamics such as interruptions, backchannels, and overlapping speech. In this paper, we introduce a novel End-to-End GPT-based model OmniFlatten for full-duplex conversation, capable of effectively modeling the complex behaviors inherent to natural conversations with low latency. To achieve full-duplex communication capabilities, we propose a multi-stage post-training scheme that progressively adapts a text-based large language model (LLM) backbone into a speech-text dialogue LLM, capable of generating text and speech in real time, without modifying the architecture of the backbone LLM. The training process comprises three stages: modality alignment, half-duplex dialogue learning, and full-duplex dialogue learning. Throughout all training stages, we standardize the data using a flattening operation, which allows us to unify the training methods and the model architecture across different modalities and tasks. Our approach offers a straightforward modeling technique and a promising research direction for developing efficient and natural end-to-end full-duplex spoken dialogue systems. Audio samples of dialogues generated by OmniFlatten can be found at this web site (https://omniflatten.github.io/).
Integrating Audio, Visual, and Semantic Information for Enhanced Multimodal Speaker Diarization
Aug 22, 2024



Speaker diarization, the process of segmenting an audio stream or transcribed speech content into homogenous partitions based on speaker identity, plays a crucial role in the interpretation and analysis of human speech. Most existing speaker diarization systems rely exclusively on unimodal acoustic information, making the task particularly challenging due to the innate ambiguities of audio signals. Recent studies have made tremendous efforts towards audio-visual or audio-semantic modeling to enhance performance. However, even the incorporation of up to two modalities often falls short in addressing the complexities of spontaneous and unstructured conversations. To exploit more meaningful dialogue patterns, we propose a novel multimodal approach that jointly utilizes audio, visual, and semantic cues to enhance speaker diarization. Our method elegantly formulates the multimodal modeling as a constrained optimization problem. First, we build insights into the visual connections among active speakers and the semantic interactions within spoken content, thereby establishing abundant pairwise constraints. Then we introduce a joint pairwise constraint propagation algorithm to cluster speakers based on these visual and semantic constraints. This integration effectively leverages the complementary strengths of different modalities, refining the affinity estimation between individual speaker embeddings. Extensive experiments conducted on multiple multimodal datasets demonstrate that our approach consistently outperforms state-of-the-art speaker diarization methods.
Self-Distillation Prototypes Network: Learning Robust Speaker Representations without Supervision
Jun 17, 2024Training speaker-discriminative and robust speaker verification systems without explicit speaker labels remains a persisting challenge. In this paper, we propose a new self-supervised speaker verification approach, Self-Distillation Prototypes Network (SDPN), which effectively facilitates self-supervised speaker representation learning. SDPN assigns the representation of the augmented views of an utterance to the same prototypes as the representation of the original view, thereby enabling effective knowledge transfer between the views. Originally, due to the lack of negative pairs in the SDPN training process, the network tends to align positive pairs very closely in the embedding space, a phenomenon known as model collapse. To alleviate this problem, we introduce a diversity regularization term to embeddings in SDPN. Comprehensive experiments on the VoxCeleb datasets demonstrate the superiority of SDPN in self-supervised speaker verification. SDPN sets a new state-of-the-art on the VoxCeleb1 speaker verification evaluation benchmark, achieving Equal Error Rate 1.80%, 1.99%, and 3.62% for trial VoxCeleb1-O, VoxCeleb1-E and VoxCeleb1-H respectively, without using any speaker labels in training.
ERes2NetV2: Boosting Short-Duration Speaker Verification Performance with Computational Efficiency
Jun 04, 2024Speaker verification systems experience significant performance degradation when tasked with short-duration trial recordings. To address this challenge, a multi-scale feature fusion approach has been proposed to effectively capture speaker characteristics from short utterances. Constrained by the model's size, a robust backbone Enhanced Res2Net (ERes2Net) combining global and local feature fusion demonstrates sub-optimal performance in short-duration speaker verification. To further improve the short-duration feature extraction capability of ERes2Net, we expand the channel dimension within each stage. However, this modification also increases the number of model parameters and computational complexity. To alleviate this problem, we propose an improved ERes2NetV2 by pruning redundant structures, ultimately reducing both the model parameters and its computational cost. A range of experiments conducted on the VoxCeleb datasets exhibits the superiority of ERes2NetV2, which achieves EER of 0.61% for the full-duration trial, 0.98% for the 3s-duration trial, and 1.48% for the 2s-duration trial on VoxCeleb1-O, respectively.
3D-Speaker-Toolkit: An Open Source Toolkit for Multi-modal Speaker Verification and Diarization
Mar 29, 2024This paper introduces 3D-Speaker-Toolkit, an open source toolkit for multi-modal speaker verification and diarization. It is designed for the needs of academic researchers and industrial practitioners. The 3D-Speaker-Toolkit adeptly leverages the combined strengths of acoustic, semantic, and visual data, seamlessly fusing these modalities to offer robust speaker recognition capabilities. The acoustic module extracts speaker embeddings from acoustic features, employing both fully-supervised and self-supervised learning approaches. The semantic module leverages advanced language models to apprehend the substance and context of spoken language, thereby augmenting the system's proficiency in distinguishing speakers through linguistic patterns. Finally, the visual module applies image processing technologies to scrutinize facial features, which bolsters the precision of speaker diarization in multi-speaker environments. Collectively, these modules empower the 3D-Speaker-Toolkit to attain elevated levels of accuracy and dependability in executing speaker-related tasks, establishing a new benchmark in multi-modal speaker analysis. The 3D-Speaker project also includes a handful of open-sourced state-of-the-art models and a large dataset containing over 10,000 speakers. The toolkit is publicly available at https://github.com/alibaba-damo-academy/3D-Speaker.
Improving Speaker Diarization using Semantic Information: Joint Pairwise Constraints Propagation
Sep 19, 2023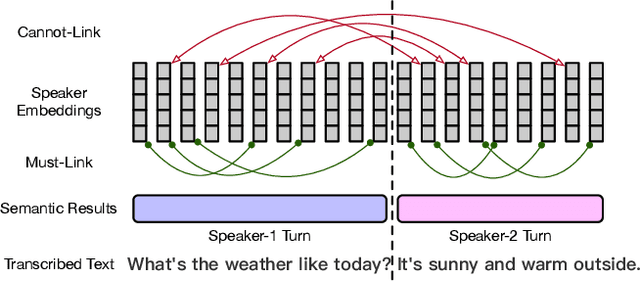



Speaker diarization has gained considerable attention within speech processing research community. Mainstream speaker diarization rely primarily on speakers' voice characteristics extracted from acoustic signals and often overlook the potential of semantic information. Considering the fact that speech signals can efficiently convey the content of a speech, it is of our interest to fully exploit these semantic cues utilizing language models. In this work we propose a novel approach to effectively leverage semantic information in clustering-based speaker diarization systems. Firstly, we introduce spoken language understanding modules to extract speaker-related semantic information and utilize these information to construct pairwise constraints. Secondly, we present a novel framework to integrate these constraints into the speaker diarization pipeline, enhancing the performance of the entire system. Extensive experiments conducted on the public dataset demonstrate the consistent superiority of our proposed approach over acoustic-only speaker diarization systems.
3D-Speaker: A Large-Scale Multi-Device, Multi-Distance, and Multi-Dialect Corpus for Speech Representation Disentanglement
Jun 28, 2023



Disentangling uncorrelated information in speech utterances is a crucial research topic within speech community. Different speech-related tasks focus on extracting distinct speech representations while minimizing the affects of other uncorrelated information. We present a large-scale speech corpus to facilitate the research of speech representation disentanglement. 3D-Speaker contains over 10,000 speakers, each of whom are simultaneously recorded by multiple Devices, locating at different Distances, and some speakers are speaking multiple Dialects. The controlled combinations of multi-dimensional audio data yield a matrix of a diverse blend of speech representation entanglement, thereby motivating intriguing methods to untangle them. The multi-domain nature of 3D-Speaker also makes it a suitable resource to evaluate large universal speech models and experiment methods of out-of-domain learning and self-supervised learning. https://3dspeaker.github.io/