 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Speaker-Toolkit: An Open Source Toolkit for Multi-modal Speaker Verification and Diarization
Mar 29, 2024This paper introduces 3D-Speaker-Toolkit, an open source toolkit for multi-modal speaker verification and diarization. It is designed for the needs of academic researchers and industrial practitioners. The 3D-Speaker-Toolkit adeptly leverages the combined strengths of acoustic, semantic, and visual data, seamlessly fusing these modalities to offer robust speaker recognition capabilities. The acoustic module extracts speaker embeddings from acoustic features, employing both fully-supervised and self-supervised learning approaches. The semantic module leverages advanced language models to apprehend the substance and context of spoken language, thereby augmenting the system's proficiency in distinguishing speakers through linguistic patterns. Finally, the visual module applies image processing technologies to scrutinize facial features, which bolsters the precision of speaker diarization in multi-speaker environments. Collectively, these modules empower the 3D-Speaker-Toolkit to attain elevated levels of accuracy and dependability in executing speaker-related tasks, establishing a new benchmark in multi-modal speaker analysis. The 3D-Speaker project also includes a handful of open-sourced state-of-the-art models and a large dataset containing over 10,000 speakers. The toolkit is publicly available at https://github.com/alibaba-damo-academy/3D-Speaker.
Source Tracing: Detecting Voice Spoofing
Dec 16, 2022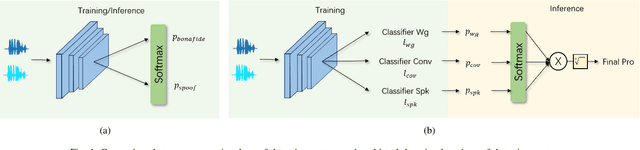
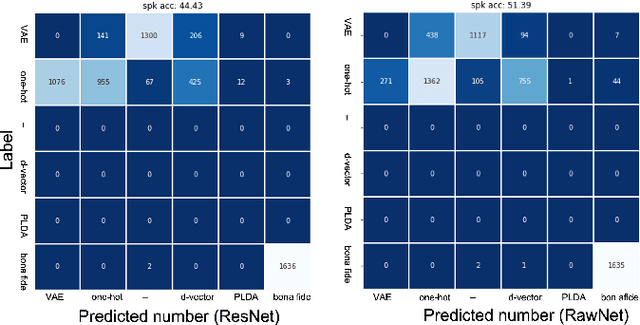
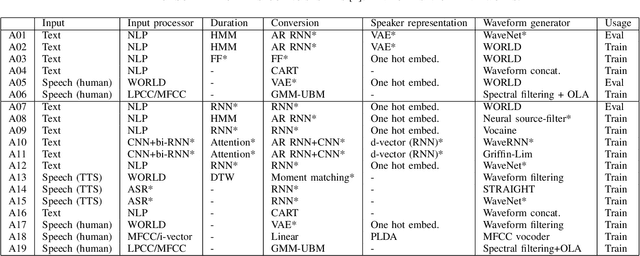
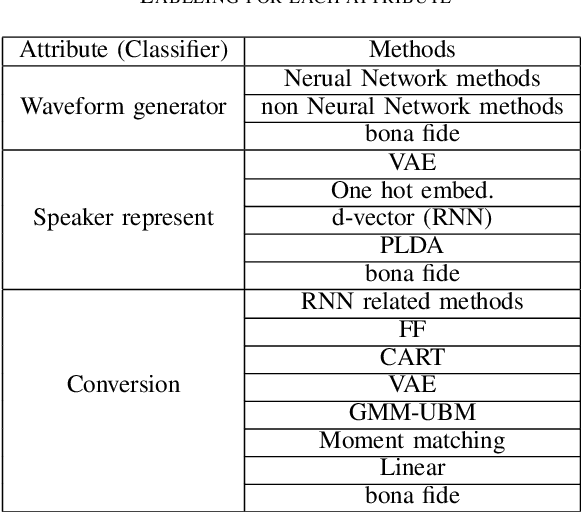
Recent anti-spoofing systems focus on spoofing detection, where the task is only to determine whether the test audio is fake. However, there are few studies putting attention to identifying the methods of generating fake speech. Common spoofing attack algorithms in the logical access (LA) scenario, such as voice conversion and speech synthesis, can be divided into several stages: input processing, conversion, waveform generation, etc. In this work, we propose a system for classifying different spoofing attributes, representing characteristics of different modules in the whole pipeline. Classifying attributes for the spoofing attack other than determining the whole spoofing pipeline can make the system more robust when encountering complex combinations of different modules at different stages. In addition, our system can also be used as an auxiliary system for anti-spoofing against unseen spoofing methods. The experiments are conducted on ASVspoof 2019 LA data set and the proposed method achieved a 20\% relative improvement against conventional binary spoof detection methods.
Binary Neural Network for Speaker Verification
Apr 06, 2021
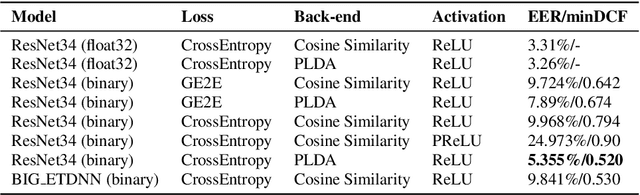


Although deep neural networks are successful for many tasks in the speech domain, the high computational and memory costs of deep neural networks make it difficult to directly deploy highperformance Neural Network systems on low-resource embedded devices. There are several mechanisms to reduce the size of the neural networks i.e. parameter pruning, parameter quantization, etc. This paper focuses on how to apply binary neural networks to the task of speaker verification. The proposed binarization of training parameters can largely maintain the performance while significantly reducing storage space requirements and computational costs. Experiment results show that, after binarizing the Convolutional Neural Network, the ResNet34-based network achieves an EER of around 5% on the Voxceleb1 testing dataset and even outperforms the traditional real number network on the text-dependent dataset: Xiaole while having a 32x memory saving.