 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Anti-spoofing Countermeasures Robustness through Joint Optimization and Transfer Learning
Jul 29, 2024Current research in synthesized speech detection primarily focuses on the generalization of detection systems to unknown spoofing methods of noise-free speech. However, the performance of anti-spoofing countermeasures (CM) system is often don't work as well in more challenging scenarios, such as those involving noise and reverberation. To address the problem of enhancing the robustness of CM systems, we propose a transfer learning-based speech enhancement front-end joint optimization (TL-SEJ) method, investigating its effectiveness in improving robustness against noise and reverberation. We evaluated the proposed method's performance through a series of comparative and ablation experiments. The experimental results show that, across different signal-to-noise ratio test conditions, the proposed TL-SEJ method improves recognition accuracy by 2.7% to 15.8% compared to the baseline. Compared to conventional data augmentation methods, our system achieves an accuracy improvement ranging from 0.7% to 5.8% in various noisy conditions and from 1.7% to 2.8% under different RT60 reverberation scenarios. These experiments demonstrate that the proposed method effectively enhances system robustness in noisy and reverberant conditions.
Source Tracing: Detecting Voice Spoofing
Dec 16, 2022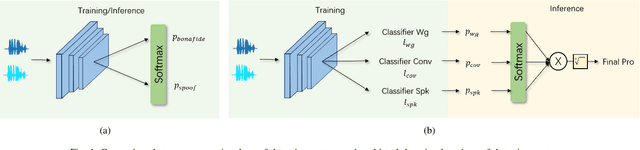
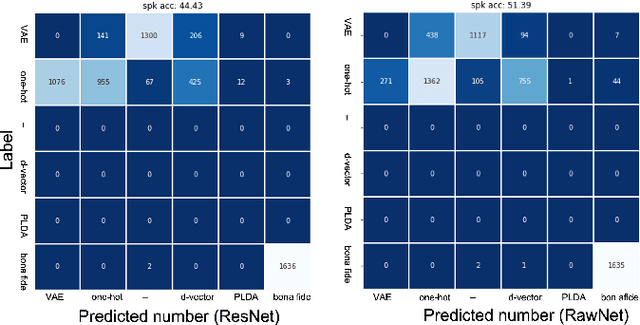
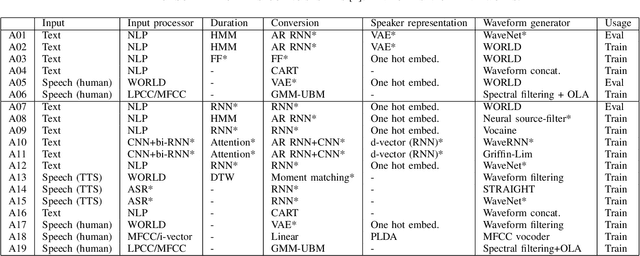
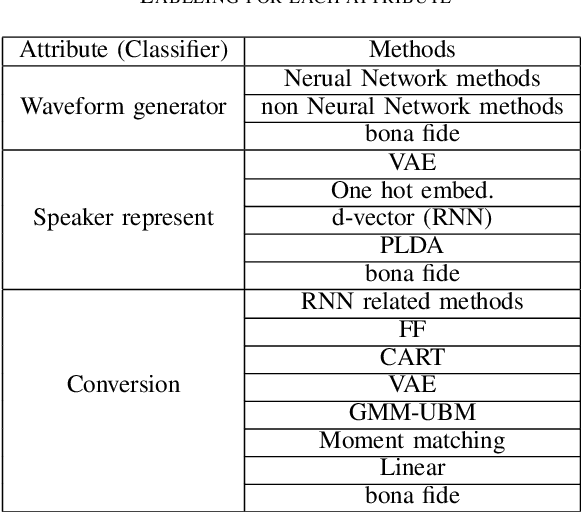
Recent anti-spoofing systems focus on spoofing detection, where the task is only to determine whether the test audio is fake. However, there are few studies putting attention to identifying the methods of generating fake speech. Common spoofing attack algorithms in the logical access (LA) scenario, such as voice conversion and speech synthesis, can be divided into several stages: input processing, conversion, waveform generation, etc. In this work, we propose a system for classifying different spoofing attributes, representing characteristics of different modules in the whole pipeline. Classifying attributes for the spoofing attack other than determining the whole spoofing pipeline can make the system more robust when encountering complex combinations of different modules at different stages. In addition, our system can also be used as an auxiliary system for anti-spoofing against unseen spoofing methods. The experiments are conducted on ASVspoof 2019 LA data set and the proposed method achieved a 20\% relative improvement against conventional binary spoof detection methods.
Low Pass Filtering and Bandwidth Extension for Robust Anti-spoofing Countermeasure Against Codec Variabilities
Nov 12, 2022A reliable voice anti-spoofing countermeasure system needs to robustly protect automatic speaker verification (ASV) systems in various kinds of spoofing scenarios. However, the performance of countermeasure systems could be degraded by channel effects and codecs. In this paper, we show that using the low-frequency subbands of signals as input can mitigate the negative impact introduced by codecs on the countermeasure systems. To validate this, two types of low-pass filters with different cut-off frequencies are applied to countermeasure systems, and the equal error rate (EER) is reduced by up to 25% relatively. In addition, we propose a deep learning based bandwidth extension approach to further improve the detection accuracy. Recent studies show that the error rate of countermeasure systems increase dramatically when the silence part is removed by Voice Activity Detection (VAD), our experimental results show that the filtering and bandwidth extension approaches are also effective under the codec condition when VAD is applied.
Deepfake Detection System for the ADD Challenge Track 3.2 Based on Score Fusion
Oct 13, 2022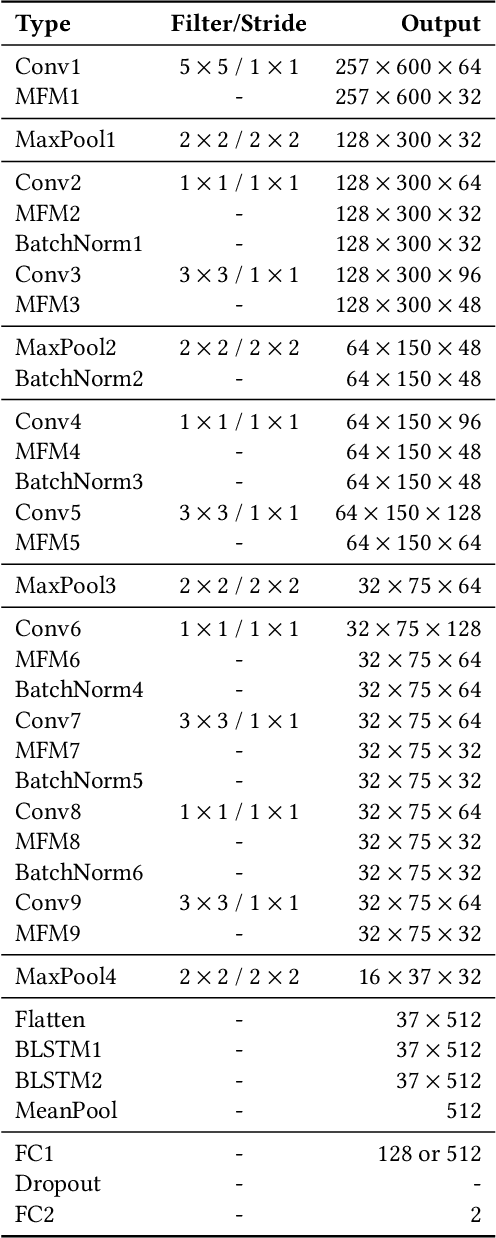
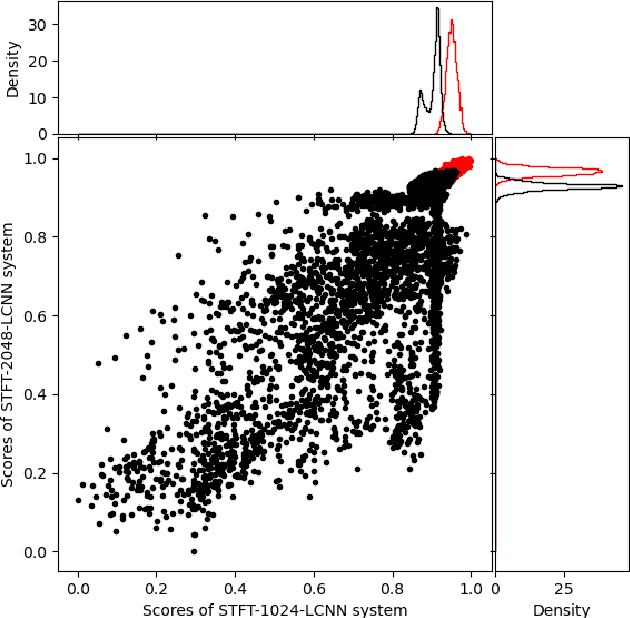
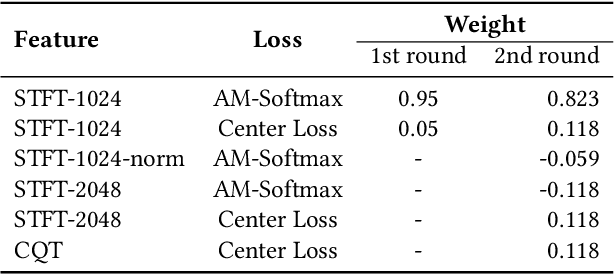
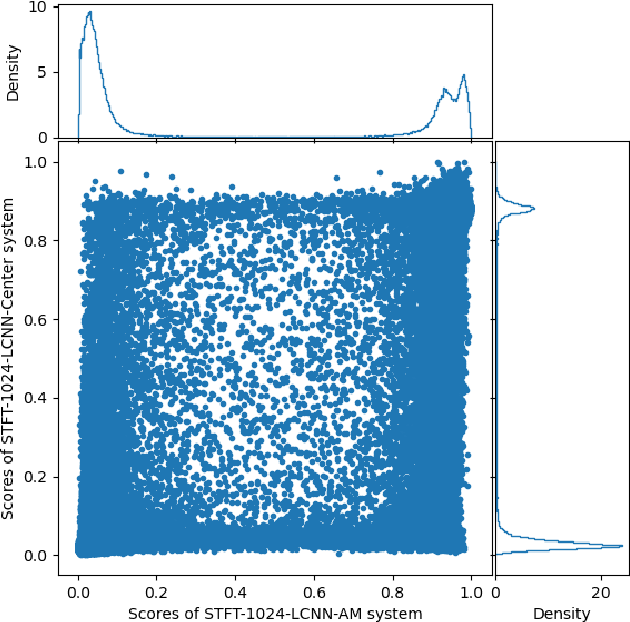
This paper describes the deepfake audio detection system submitted to the Audio Deep Synthesis Detection (ADD) Challenge Track 3.2 and gives an analysis of score fusion. The proposed system is a score-level fusion of several light convolutional neural network (LCNN) based models. Various front-ends are used as input features, including low-frequency short-time Fourier transform and Constant Q transform. Due to the complex noise and rich synthesis algorithms, it is difficult to obtain the desired performance using the training set directly. Online data augmentation methods effectively improve the robustness of fake audio detection systems. In particular, the reasons for the poor improvement of score fusion are explored through visualization of the score distributions and comparison with score distribution on another dataset. The overfitting of the model to the training set leads to extreme values of the scores and low correlation of the score distributions, which makes score fusion difficult. Fusion with partially fake audio detection system improves system performance further. The submission on track 3.2 obtained the weighted equal error rate (WEER) of 11.04\%, which is one of the best performing systems in the challenge.
The DKU-OPPO System for the 2022 Spoofing-Aware Speaker Verification Challenge
Jul 15, 2022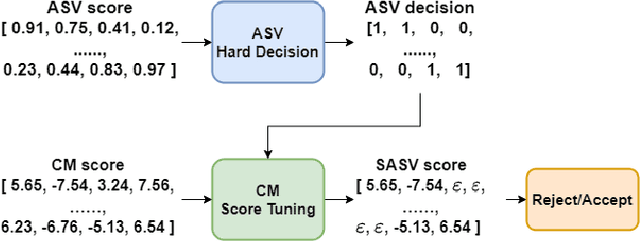
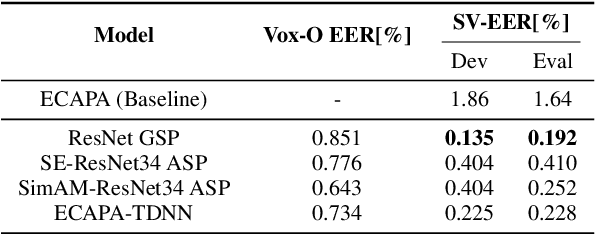
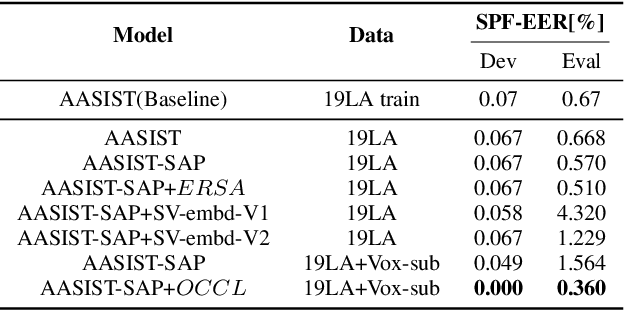
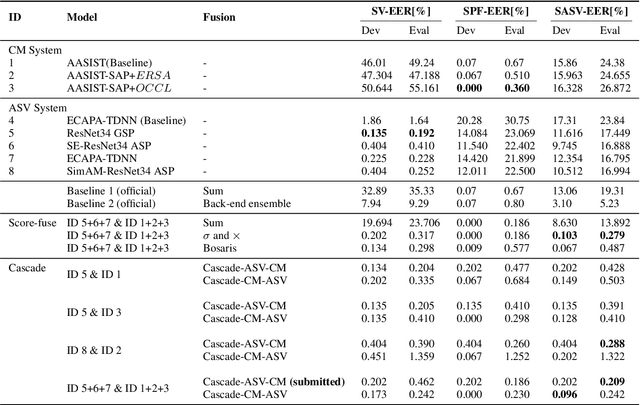
This paper describes our DKU-OPPO system for the 2022 Spoofing-Aware Speaker Verification (SASV) Challenge. First, we split the joint task into speaker verification (SV) and spoofing countermeasure (CM), these two tasks which are optimized separately. For ASV systems, four state-of-the-art methods are employed. For CM systems, we propose two methods on top of the challenge baseline to further improve the performance, namely Embedding Random Sampling Augmentation (ERSA) and One-Class Confusion Loss(OCCL). Second, we also explore whether SV embedding could help improve CM system performance. We observe a dramatic performance degradation of existing CM systems on the domain-mismatched Voxceleb2 dataset. Third, we compare different fusion strategies, including parallel score fusion and sequential cascaded systems. Compared to the 1.71% SASV-EER baseline, our submitted cascaded system obtains a 0.21% SASV-EER on the challenge official evaluation set.
The 2020 Personalized Voice Trigger Challenge: Open Database, Evaluation Metrics and the Baseline Systems
Jan 06, 2021
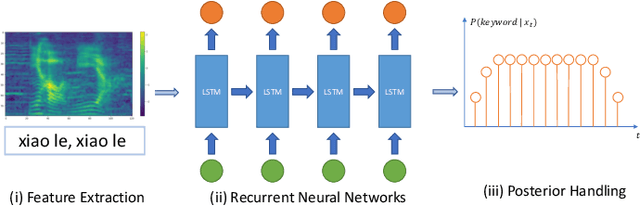

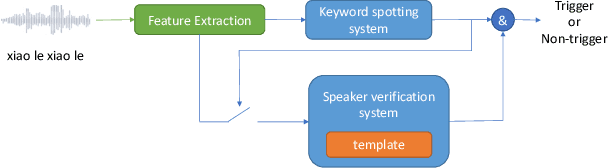
The 2020 Personalized Voice Trigger Challenge (PVTC2020) addresses two different research problems a unified setup: joint wake-up word detection with speaker verification on close-talking single microphone data and far-field multi-channel microphone array data. Specially, the second task poses an additional cross-channel matching challenge on top of the far-field condition. To simulate the real-life application scenario, the enrollment utterances are recorded from close-talking cell-phone only, while the test utterances are recorded from both the close-talking cell-phone and the far-field microphone arrays. This paper introduces our challenge setup and the released database as well as the evaluation metrics. In addition, we present a joint end-to-end neural network baseline system trained with the proposed database for speaker-dependent wake-up word detection. Results show that the cost calculated from the miss rate and the false alarm rate, can reach 0.37 in the close-talking single microphone task and 0.31 in the far-field microphone array task. The official website and the open-source baseline system have been released.