 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Detection System for the ADD Challenge Track 3.2 Based on Score Fusion
Paper and Code
Oct 13, 2022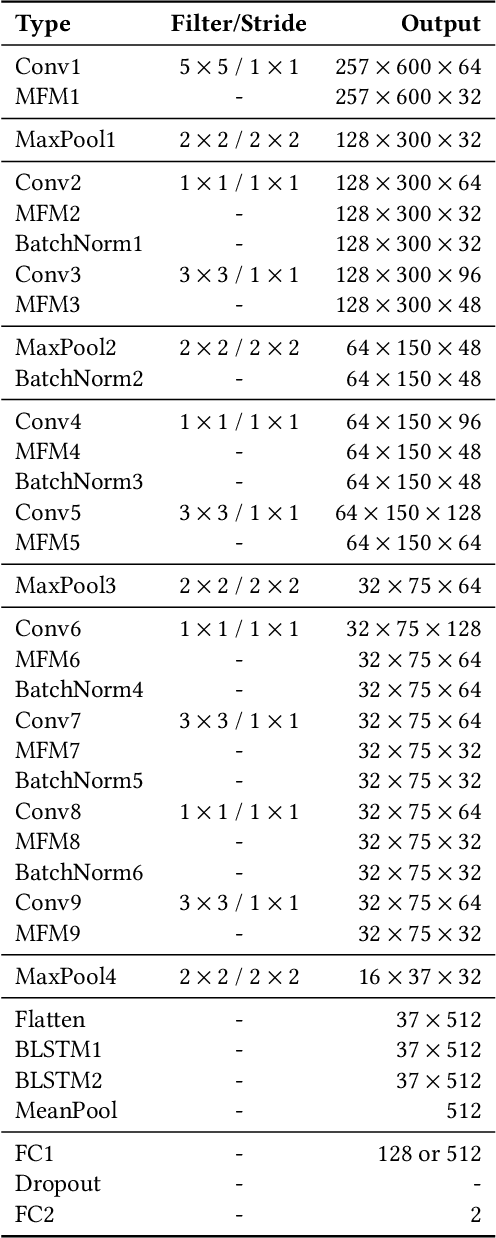
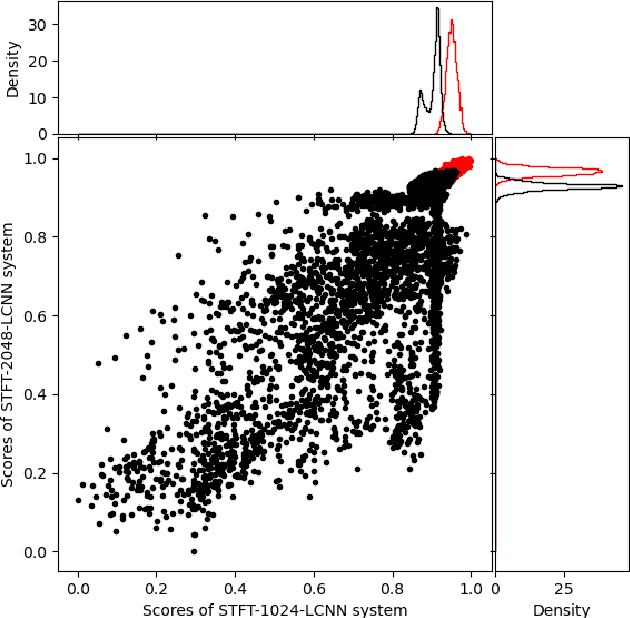
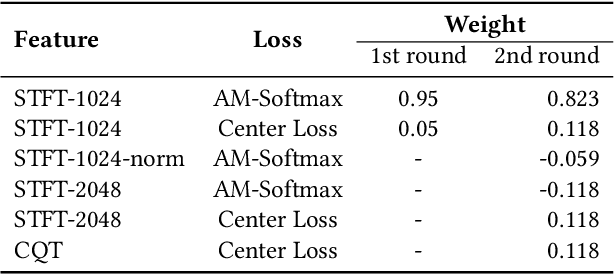
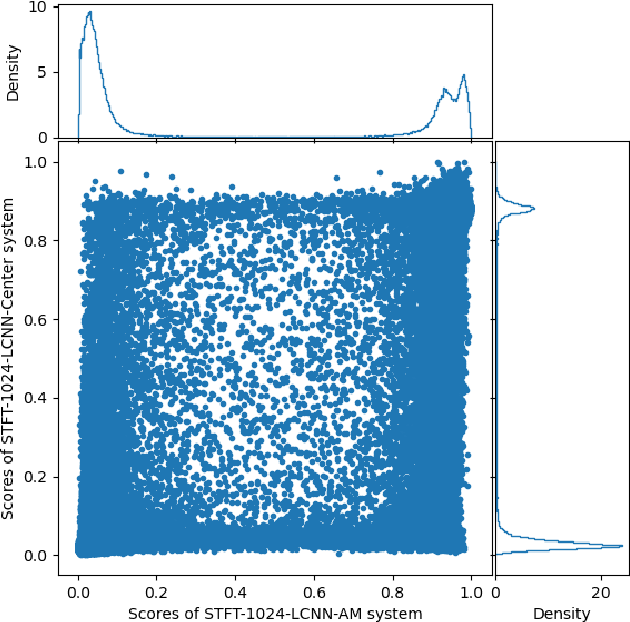
This paper describes the deepfake audio detection system submitted to the Audio Deep Synthesis Detection (ADD) Challenge Track 3.2 and gives an analysis of score fusion. The proposed system is a score-level fusion of several light convolutional neural network (LCNN) based models. Various front-ends are used as input features, including low-frequency short-time Fourier transform and Constant Q transform. Due to the complex noise and rich synthesis algorithms, it is difficult to obtain the desired performance using the training set directly. Online data augmentation methods effectively improve the robustness of fake audio detection systems. In particular, the reasons for the poor improvement of score fusion are explored through visualization of the score distributions and comparison with score distribution on another dataset. The overfitting of the model to the training set leads to extreme values of the scores and low correlation of the score distributions, which makes score fusion difficult. Fusion with partially fake audio detection system improves system performance further. The submission on track 3.2 obtained the weighted equal error rate (WEER) of 11.04\%, which is one of the best performing systems in the challenge.