 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Progressive Clustering for Semi-supervised Domain Adaptation in Speaker Verification
Oct 07, 2023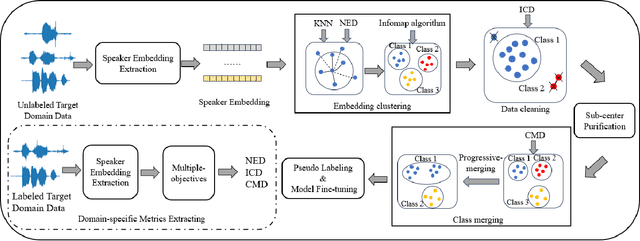
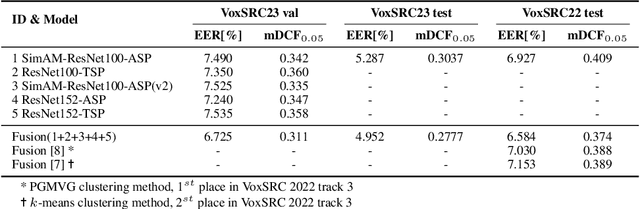
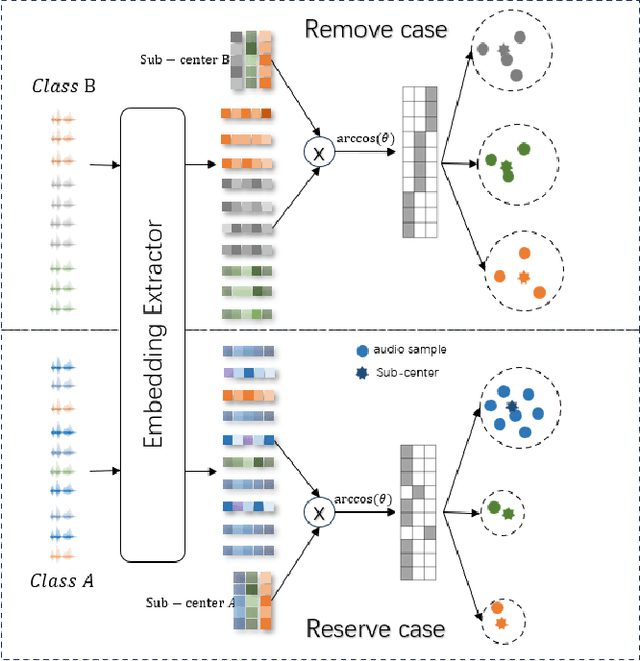
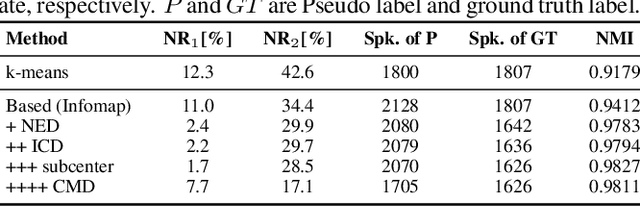
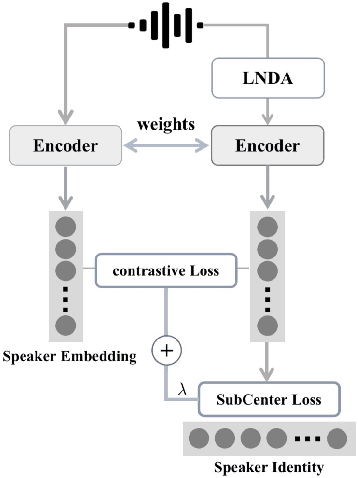
Utilizing the pseudo-labeling algorithm with large-scale unlabeled data becomes crucial for semi-supervised domain adaptation in speaker verification tasks. In this paper, we propose a novel pseudo-labeling method named Multi-objective Progressive Clustering (MoPC), specifically designed for semi-supervised domain adaptation. Firstly, we utilize limited labeled data from the target domain to derive domain-specific descriptors based on multiple distinct objectives, namely within-graph denoising, intra-class denoising and inter-class denoising. Then, the Infomap algorithm is adopted for embedding clustering, and the descriptors are leveraged to further refine the target domain's pseudo-labels. Moreover, to further improve the quality of pseudo labels, we introduce the subcenter-purification and progressive-merging strategy for label denoising. Our proposed MoPC method achieves 4.95% EER and ranked the 1$^{st}$ place on the evaluation set of VoxSRC 2023 track 3. We also conduct additional experiments on the FFSVC dataset and yield promising results.
Haha-Pod: An Attempt for Laughter-based Non-Verbal Speaker Verification
Sep 25, 2023



It is widely acknowledged that discriminative representation for speaker verification can be extracted from verbal speech. However, how much speaker information that non-verbal vocalization carries is still a puzzle. This paper explores speaker verification based on the most ubiquitous form of non-verbal voice, laughter. First, we use a semi-automatic pipeline to collect a new Haha-Pod dataset from open-source podcast media. The dataset contains over 240 speakers' laughter clips with corresponding high-quality verbal speech. Second, we propose a Two-Stage Teacher-Student (2S-TS) framework to minimize the within-speaker embedding distance between verbal and non-verbal (laughter) signals. Considering Haha-Pod as a test set, two trials (S2L-Eval) are designed to verify the speaker's identity through laugh sounds. Experimental results demonstrate that our method can significantly improve the performance of the S2L-Eval test set with only a minor degradation on the VoxCeleb1 test set. The Haha-Pod dataset is open to access on https://drive.google.com/file/d/1J-HBRTsm_yWrcbkXupy-tiWRt5gE2LzG/view?usp=drive_link.
VoxBlink: X-Large Speaker Verification Dataset on Camera
Aug 23, 2023



In this paper, we contribute a novel and extensive dataset for speaker verification, which contains noisy 38k identities/1.45M utterances (VoxBlink) and relatively cleaned 18k identities/1.02M (VoxBlink-Clean) utterances for training. Firstly, we accumulate a 60K+ users' list with their avatars and download their short videos on YouTube. We then established an automatic and scalable pipeline to extract relevant speech and video segments from these videos. To our knowledge, the VoxBlink dataset is one of the largest speaker recognition datasets available. Secondly, we conduct a series of experiments based on different backbones trained on a mix of the VoxCeleb2 and the VoxBlink-Clean. Our findings highlight a notable performance improvement, ranging from 13% to 30%, across different backbone architectures upon integrating our dataset for training. The dataset will be made publicly available shortly.
The DKU-MSXF Speaker Verification System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023

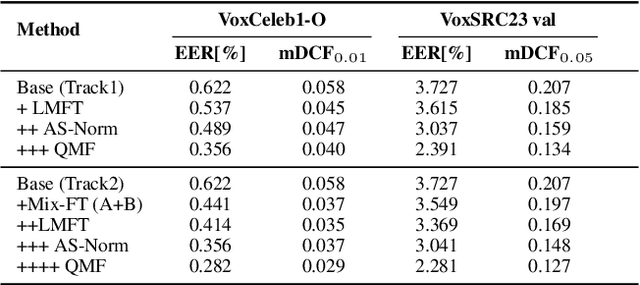
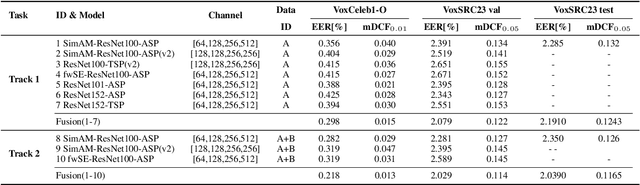
This paper is the system description of the DKU-MSXF System for the track1, track2 and track3 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). For Track 1, we utilize a network structure based on ResNet for training. By constructing a cross-age QMF training set, we achieve a substantial improvement in system performance. For Track 2, we inherite the pre-trained model from Track 1 and conducte mixed training by incorporating the VoxBlink-clean dataset. In comparison to Track 1, the models incorporating VoxBlink-clean data exhibit a performance improvement by more than 10% relatively. For Track3, the semi-supervised domain adaptation task, a novel pseudo-labeling method based on triple thresholds and sub-center purification is adopted to make domain adaptation. The final submission achieves mDCF of 0.1243 in task1, mDCF of 0.1165 in Track 2 and EER of 4.952% in Track 3.
The DKU-MSXF Diarization System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023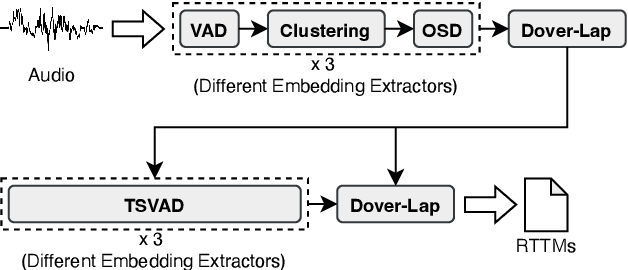
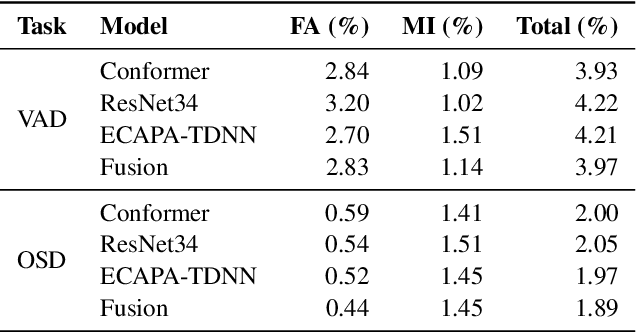

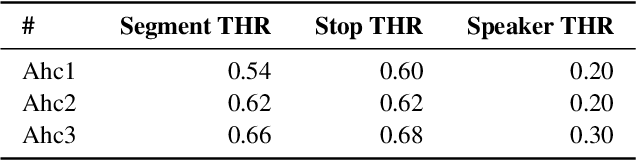
This paper describes the DKU-MSXF submission to track 4 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our system pipeline contains voice activity detection, clustering-based diarization, overlapped speech detection, and target-speaker voice activity detection, where each procedure has a fused output from 3 sub-models. Finally, we fuse different clustering-based and TSVAD-based diarization systems using DOVER-Lap and achieve the 4.30% diarization error rate (DER), which ranks first place on track 4 of the challenge leaderboard.
Source Tracing: Detecting Voice Spoofing
Dec 16, 2022
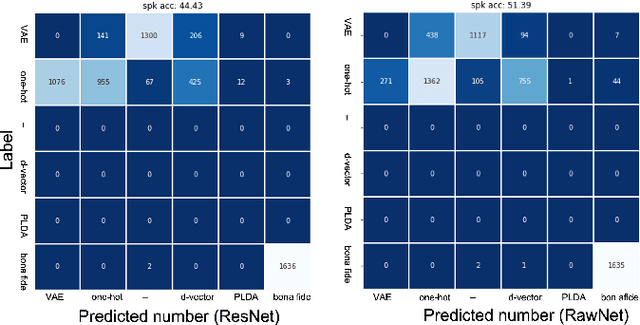
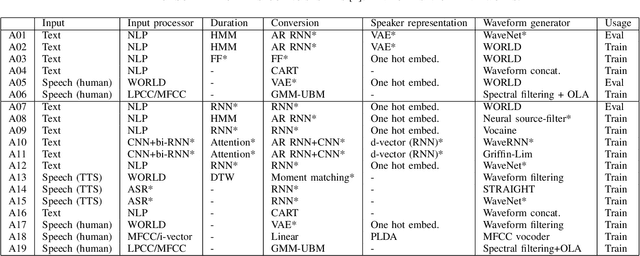
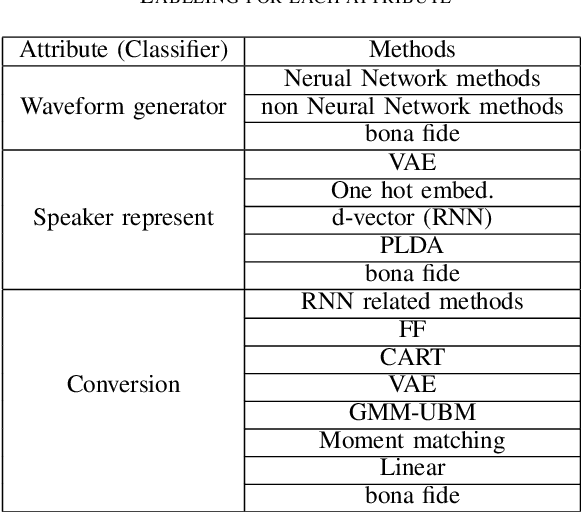
Recent anti-spoofing systems focus on spoofing detection, where the task is only to determine whether the test audio is fake. However, there are few studies putting attention to identifying the methods of generating fake speech. Common spoofing attack algorithms in the logical access (LA) scenario, such as voice conversion and speech synthesis, can be divided into several stages: input processing, conversion, waveform generation, etc. In this work, we propose a system for classifying different spoofing attributes, representing characteristics of different modules in the whole pipeline. Classifying attributes for the spoofing attack other than determining the whole spoofing pipeline can make the system more robust when encountering complex combinations of different modules at different stages. In addition, our system can also be used as an auxiliary system for anti-spoofing against unseen spoofing methods. The experiments are conducted on ASVspoof 2019 LA data set and the proposed method achieved a 20\% relative improvement against conventional binary spoof detection methods.
Laugh Betrays You? Learning Robust Speaker Representation From Speech Containing Non-Verbal Fragments
Nov 07, 2022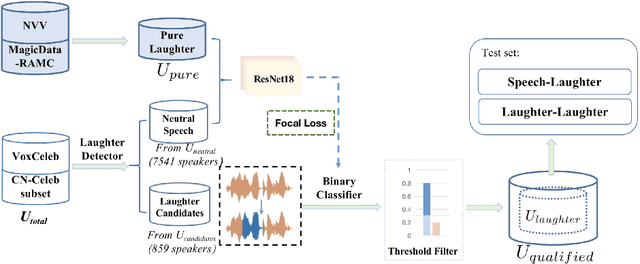
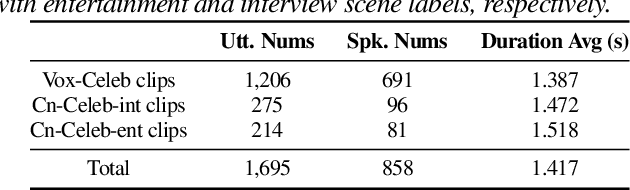

The success of automatic speaker verification shows that discriminative speaker representations can be extracted from neutral speech. However, as a kind of non-verbal voice, laughter should also carry speaker information intuitively. Thus, this paper focuses on exploring speaker verification about utterances containing non-verbal laughter segments. We collect a set of clips with laughter components by conducting a laughter detection script on VoxCeleb and part of the CN-Celeb dataset. To further filter untrusted clips, probability scores are calculated by our binary laughter detection classifier, which is pre-trained by pure laughter and neutral speech. After that, based on the clips whose scores are over the threshold, we construct trials under two different evaluation scenarios: Laughter-Laughter (LL) and Speech-Laughter (SL). Then a novel method called Laughter-Splicing based Network (LSN) is proposed, which can significantly boost performance in both scenarios and maintain the performance on the neutral speech, such as the VoxCeleb1 test set. Specifically, our system achieves relative 20% and 22% improvement on Laughter-Laughter and Speech-Laughter trials, respectively. The meta-data and sample clips have been released at https://github.com/nevermoreLin/Laugh_LSN.
Target-Speaker Voice Activity Detection via Sequence-to-Sequence Prediction
Nov 03, 2022



Target-speaker voice activity detection is currently a promising approach for speaker diarization in complex acoustic environments. This paper presents a novel Sequence-to-Sequence Target-Speaker Voice Activity Detection (Seq2Seq-TSVAD) method that can efficiently address the joint modeling of large-scale speakers and predict high-resolution voice activities. Experimental results show that larger speaker capacity and higher output resolution can significantly reduce the diarization error rate (DER), which achieves the new state-of-the-art performance of 4.55% on the VoxConverse test set and 10.77% on Track 1 of the DIHARD-III evaluation set under the widely-used evaluation metrics.
The DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022
Oct 11, 2022
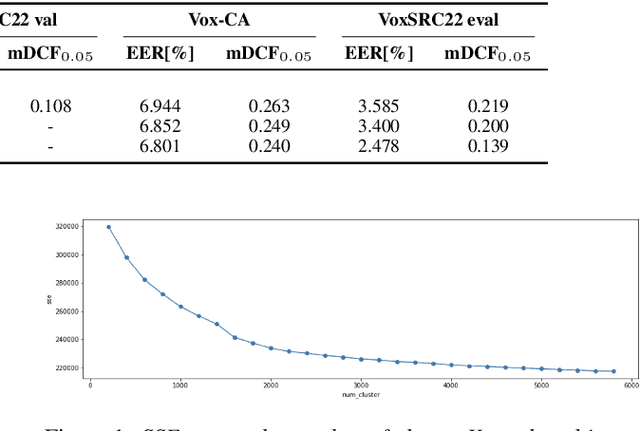
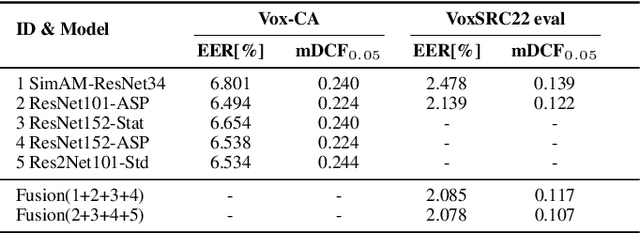
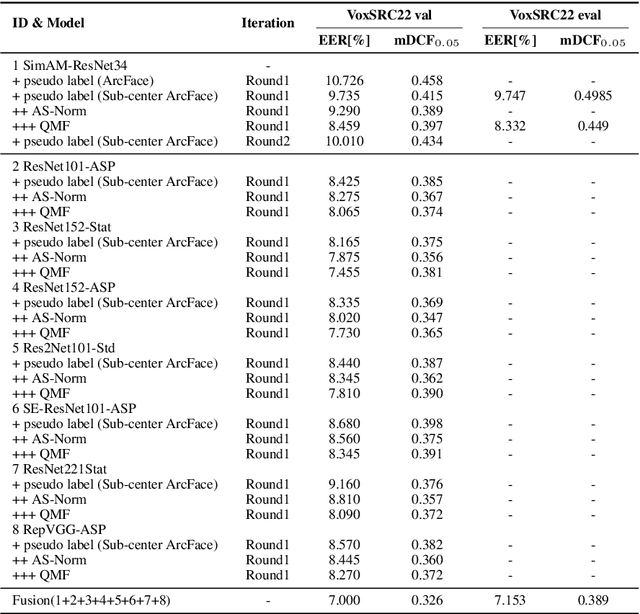
This paper is the system description of the DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC22). In this challenge, we focus on track1 and track3. For track1, multiple backbone networks are adopted to extract frame-level features. Since track1 focus on the cross-age scenarios, we adopt the cross-age trials and perform QMF to calibrate score. The magnitude-based quality measures achieve a large improvement. For track3, the semi-supervised domain adaptation task, the pseudo label method is adopted to make domain adaptation. Considering the noise labels in clustering, the ArcFace is replaced by Sub-center ArcFace. The final submission achieves 0.107 mDCF in task1 and 7.135% EER in task3.
The DKU-DukeECE Diarization System for the VoxCeleb Speaker Recognition Challenge 2022
Oct 04, 2022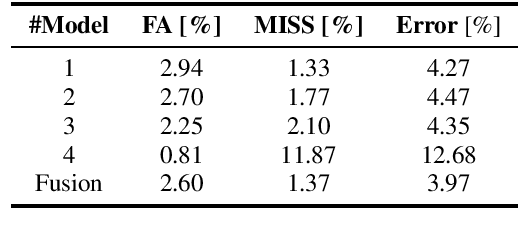

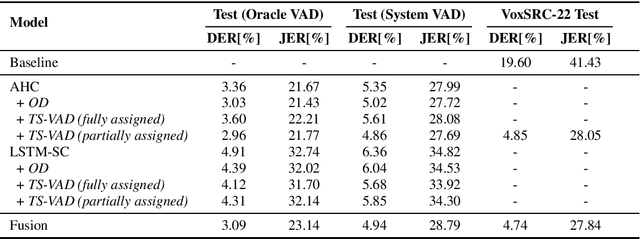
This paper discribes the DKU-DukeECE submission to the 4th track of the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our system contains a fused voice activity detection model, a clustering-based diarization model, and a target-speaker voice activity detection-based overlap detection model. Overall, the submitted system is similar to our previous year's system in VoxSRC-21. The difference is that we use a much better speaker embedding and a fused voice activity detection, which significantly improves the performance. Finally, we fuse 4 different systems using DOVER-lap and achieve 4.75 of the diarization error rate, which ranks the 1st place in track 4.