Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DKU-MSXF Diarization System for the VoxCeleb Speaker Recognition Challenge 2023
Paper and Code
Aug 17, 2023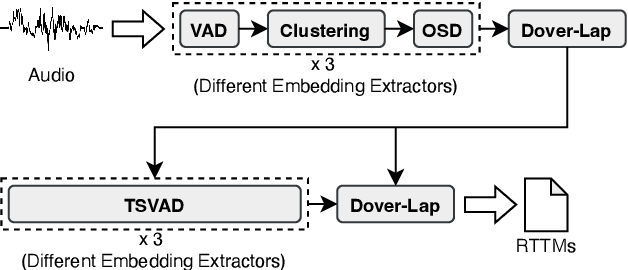
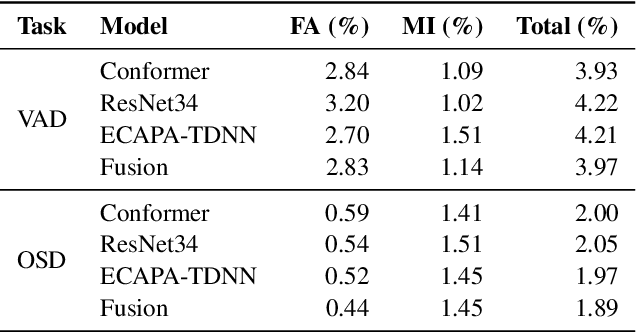

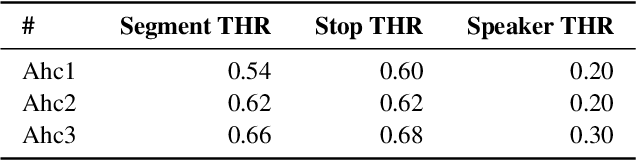
This paper describes the DKU-MSXF submission to track 4 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our system pipeline contains voice activity detection, clustering-based diarization, overlapped speech detection, and target-speaker voice activity detection, where each procedure has a fused output from 3 sub-models. Finally, we fuse different clustering-based and TSVAD-based diarization systems using DOVER-Lap and achieve the 4.30% diarization error rate (DER), which ranks first place on track 4 of the challenge leaderboard.
View paper on