 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiarization-Aware Multi-Speaker Automatic Speech Recognition via Large Language Models
Jun 06, 2025Multi-speaker automatic speech recognition (MS-ASR) faces significant challenges in transcribing overlapped speech, a task critical for applications like meeting transcription and conversational analysis. While serialized output training (SOT)-style methods serve as common solutions, they often discard absolute timing information, limiting their utility in time-sensitive scenarios. Leveraging recent advances in large language models (LLMs) for conversational audio processing, we propose a novel diarization-aware multi-speaker ASR system that integrates speaker diarization with LLM-based transcription. Our framework processes structured diarization inputs alongside frame-level speaker and semantic embeddings, enabling the LLM to generate segment-level transcriptions. Experiments demonstrate that the system achieves robust performance in multilingual dyadic conversations and excels in complex, high-overlap multi-speaker meeting scenarios. This work highlights the potential of LLMs as unified back-ends for joint speaker-aware segmentation and transcription.
Sequence-to-Sequence Neural Diarization with Automatic Speaker Detection and Representation
Nov 21, 2024This paper proposes a novel Sequence-to-Sequence Neural Diarization (SSND) framework to perform online and offline speaker diarization. It is developed from the sequence-to-sequence architecture of our previous target-speaker voice activity detection system and then evolves into a new diarization paradigm by addressing two critical problems. 1) Speaker Detection: The proposed approach can utilize incompletely given speaker embeddings to discover the unknown speaker and predict the target voice activities in the audio signal. It does not require a prior diarization system for speaker enrollment in advance. 2) Speaker Representation: The proposed approach can adopt the predicted voice activities as reference information to extract speaker embeddings from the audio signal simultaneously. The representation space of speaker embedding is jointly learned within the whole diarization network without using an extra speaker embedding model. During inference, the SSND framework can process long audio recordings blockwise. The detection module utilizes the previously obtained speaker-embedding buffer to predict both enrolled and unknown speakers' voice activities for each coming audio block. Next, the speaker-embedding buffer is updated according to the predictions of the representation module. Assuming that up to one new speaker may appear in a small block shift, our model iteratively predicts the results of each block and extracts target embeddings for the subsequent blocks until the signal ends. Finally, the last speaker-embedding buffer can re-score the entire audio, achieving highly accurate diarization performance as an offline system. (......)
VoxBlink2: A 100K+ Speaker Recognition Corpus and the Open-Set Speaker-Identification Benchmark
Jul 16, 2024In this paper, we provide a large audio-visual speaker recognition dataset, VoxBlink2, which includes approximately 10M utterances with videos from 110K+ speakers in the wild. This dataset represents a significant expansion over the VoxBlink dataset, encompassing a broader diversity of speakers and scenarios by the grace of an optimized data collection pipeline. Afterward, we explore the impact of training strategies, data scale, and model complexity on speaker verification and finally establish a new single-model state-of-the-art EER at 0.170% and minDCF at 0.006% on the VoxCeleb1-O test set. Such remarkable results motivate us to explore speaker recognition from a new challenging perspective. We raise the Open-Set Speaker-Identification task, which is designed to either match a probe utterance with a known gallery speaker or categorize it as an unknown query. Associated with this task, we design concrete benchmark and evaluation protocols. The data and model resources can be found in http://voxblink2.github.io.
The Database and Benchmark for Source Speaker Verification Against Voice Conversion
Jun 07, 2024


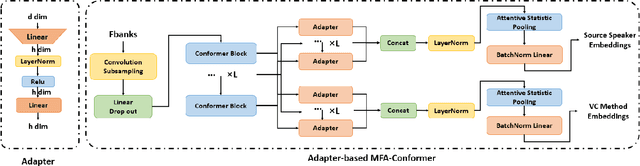
Voice conversion systems can transform audio to mimic another speaker's voice, thereby attacking speaker verification systems. However, ongoing studies on source speaker verification are hindered by limited data availability and methodological constraints. In this paper, we generate a large-scale converted speech database and train a batch of baseline systems based on the MFA-Conformer architecture to promote the source speaker verification task. In addition, we introduce a related task called conversion method recognition. An adapter-based multi-task learning approach is employed to achieve effective conversion method recognition without compromising source speaker verification performance. Additionally, we investigate and effectively address the open-set conversion method recognition problem through the implementation of an open-set nearest neighbor approach.
KunquDB: An Attempt for Speaker Verification in the Chinese Opera Scenario
Mar 20, 2024



This work aims to promote Chinese opera research in both musical and speech domains, with a primary focus on overcoming the data limitations. We introduce KunquDB, a relatively large-scale, well-annotated audio-visual dataset comprising 339 speakers and 128 hours of content. Originating from the Kunqu Opera Art Canon (Kunqu yishu dadian), KunquDB is meticulously structured by dialogue lines, providing explicit annotations including character names, speaker names, gender information, vocal manner classifications, and accompanied by preliminary text transcriptions. KunquDB provides a versatile foundation for role-centric acoustic studies and advancements in speech-related research, including Automatic Speaker Verification (ASV). Beyond enriching opera research, this dataset bridges the gap between artistic expression and technological innovation. Pioneering the exploration of ASV in Chinese opera, we construct four test trials considering two distinct vocal manners in opera voices: stage speech (ST) and singing (S). Implementing domain adaptation methods effectively mitigates domain mismatches induced by these vocal manner variations while there is still room for further improvement as a benchmark.
Multi-objective Progressive Clustering for Semi-supervised Domain Adaptation in Speaker Verification
Oct 07, 2023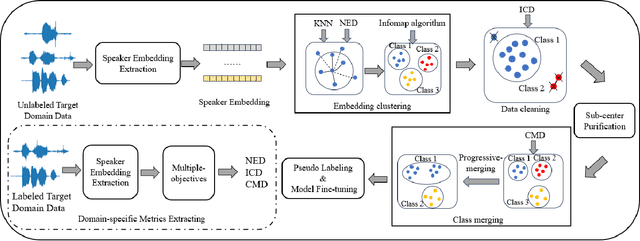
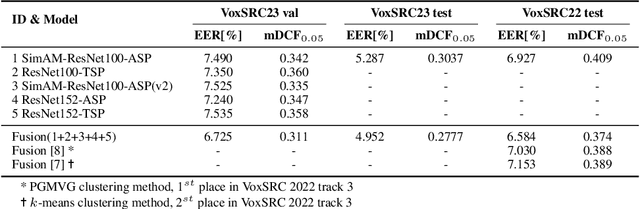
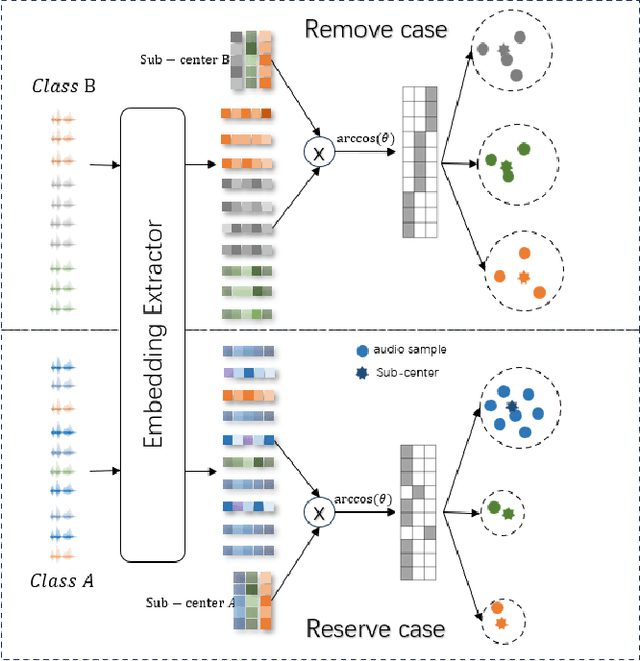
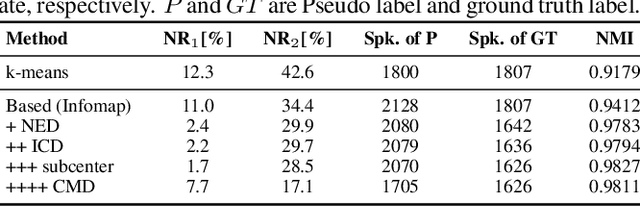
Utilizing the pseudo-labeling algorithm with large-scale unlabeled data becomes crucial for semi-supervised domain adaptation in speaker verification tasks. In this paper, we propose a novel pseudo-labeling method named Multi-objective Progressive Clustering (MoPC), specifically designed for semi-supervised domain adaptation. Firstly, we utilize limited labeled data from the target domain to derive domain-specific descriptors based on multiple distinct objectives, namely within-graph denoising, intra-class denoising and inter-class denoising. Then, the Infomap algorithm is adopted for embedding clustering, and the descriptors are leveraged to further refine the target domain's pseudo-labels. Moreover, to further improve the quality of pseudo labels, we introduce the subcenter-purification and progressive-merging strategy for label denoising. Our proposed MoPC method achieves 4.95% EER and ranked the 1$^{st}$ place on the evaluation set of VoxSRC 2023 track 3. We also conduct additional experiments on the FFSVC dataset and yield promising results.
Haha-Pod: An Attempt for Laughter-based Non-Verbal Speaker Verification
Sep 25, 2023



It is widely acknowledged that discriminative representation for speaker verification can be extracted from verbal speech. However, how much speaker information that non-verbal vocalization carries is still a puzzle. This paper explores speaker verification based on the most ubiquitous form of non-verbal voice, laughter. First, we use a semi-automatic pipeline to collect a new Haha-Pod dataset from open-source podcast media. The dataset contains over 240 speakers' laughter clips with corresponding high-quality verbal speech. Second, we propose a Two-Stage Teacher-Student (2S-TS) framework to minimize the within-speaker embedding distance between verbal and non-verbal (laughter) signals. Considering Haha-Pod as a test set, two trials (S2L-Eval) are designed to verify the speaker's identity through laugh sounds. Experimental results demonstrate that our method can significantly improve the performance of the S2L-Eval test set with only a minor degradation on the VoxCeleb1 test set. The Haha-Pod dataset is open to access on https://drive.google.com/file/d/1J-HBRTsm_yWrcbkXupy-tiWRt5gE2LzG/view?usp=drive_link.
VoxBlink: X-Large Speaker Verification Dataset on Camera
Aug 23, 2023



In this paper, we contribute a novel and extensive dataset for speaker verification, which contains noisy 38k identities/1.45M utterances (VoxBlink) and relatively cleaned 18k identities/1.02M (VoxBlink-Clean) utterances for training. Firstly, we accumulate a 60K+ users' list with their avatars and download their short videos on YouTube. We then established an automatic and scalable pipeline to extract relevant speech and video segments from these videos. To our knowledge, the VoxBlink dataset is one of the largest speaker recognition datasets available. Secondly, we conduct a series of experiments based on different backbones trained on a mix of the VoxCeleb2 and the VoxBlink-Clean. Our findings highlight a notable performance improvement, ranging from 13% to 30%, across different backbone architectures upon integrating our dataset for training. The dataset will be made publicly available shortly.
The DKU-MSXF Diarization System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023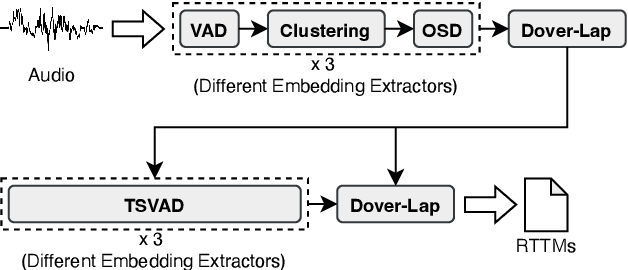
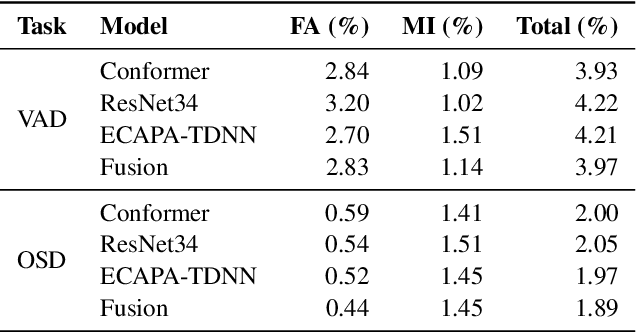

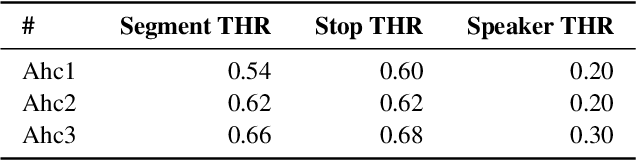
This paper describes the DKU-MSXF submission to track 4 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our system pipeline contains voice activity detection, clustering-based diarization, overlapped speech detection, and target-speaker voice activity detection, where each procedure has a fused output from 3 sub-models. Finally, we fuse different clustering-based and TSVAD-based diarization systems using DOVER-Lap and achieve the 4.30% diarization error rate (DER), which ranks first place on track 4 of the challenge leaderboard.
The DKU-MSXF Speaker Verification System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023

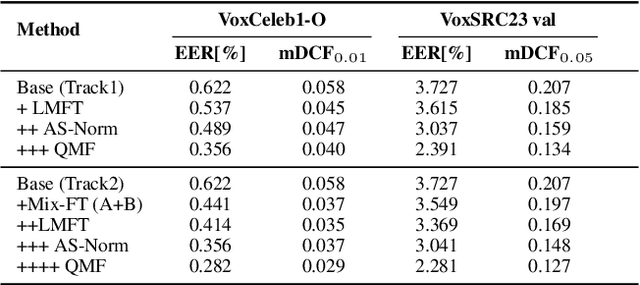
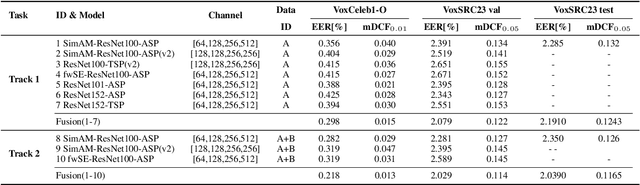
This paper is the system description of the DKU-MSXF System for the track1, track2 and track3 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). For Track 1, we utilize a network structure based on ResNet for training. By constructing a cross-age QMF training set, we achieve a substantial improvement in system performance. For Track 2, we inherite the pre-trained model from Track 1 and conducte mixed training by incorporating the VoxBlink-clean dataset. In comparison to Track 1, the models incorporating VoxBlink-clean data exhibit a performance improvement by more than 10% relatively. For Track3, the semi-supervised domain adaptation task, a novel pseudo-labeling method based on triple thresholds and sub-center purification is adopted to make domain adaptation. The final submission achieves mDCF of 0.1243 in task1, mDCF of 0.1165 in Track 2 and EER of 4.952% in Track 3.