 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxBlink2: A 100K+ Speaker Recognition Corpus and the Open-Set Speaker-Identification Benchmark
Jul 16, 2024In this paper, we provide a large audio-visual speaker recognition dataset, VoxBlink2, which includes approximately 10M utterances with videos from 110K+ speakers in the wild. This dataset represents a significant expansion over the VoxBlink dataset, encompassing a broader diversity of speakers and scenarios by the grace of an optimized data collection pipeline. Afterward, we explore the impact of training strategies, data scale, and model complexity on speaker verification and finally establish a new single-model state-of-the-art EER at 0.170% and minDCF at 0.006% on the VoxCeleb1-O test set. Such remarkable results motivate us to explore speaker recognition from a new challenging perspective. We raise the Open-Set Speaker-Identification task, which is designed to either match a probe utterance with a known gallery speaker or categorize it as an unknown query. Associated with this task, we design concrete benchmark and evaluation protocols. The data and model resources can be found in http://voxblink2.github.io.
CEC: A Noisy Label Detection Method for Speaker Recognition
Jun 19, 2024



Noisy labels are inevitable, even in well-annotated datasets. The detection of noisy labels is of significant importance to enhance the robustness of speaker recognition models. In this paper, we propose a novel noisy label detection approach based on two new statistical metrics: Continuous Inconsistent Counting (CIC) and Total Inconsistent Counting (TIC). These metrics are calculated through Cross-Epoch Counting (CEC) and correspond to the early and late stages of training, respectively. Additionally, we categorize samples based on their prediction results into three categories: inconsistent samples, hard samples, and easy samples. During training, we gradually increase the difficulty of hard samples to update model parameters, preventing noisy labels from being overfitted. Compared to contrastive schemes, our approach not only achieves the best performance in speaker verification but also excels in noisy label detection.
MFAS: Emotion Recognition through Multiple Perspectives Fusion Architecture Search Emulating Human Cognition
Jun 12, 2023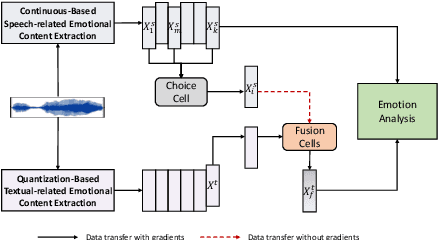

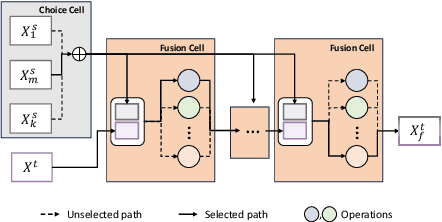
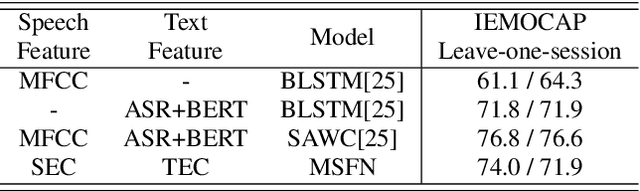
Speech emotion recognition aims to identify and analyze emotional states in target speech similar to humans. Perfect emotion recognition can greatly benefit a wide range of human-machine interaction tasks. Inspired by the human process of understanding emotions, we demonstrate that compared to quantized modeling, understanding speech content from a continuous perspective, akin to human-like comprehension, enables the model to capture more comprehensive emotional information. Additionally, considering that humans adjust their perception of emotional words in textual semantic based on certain cues present in speech, we design a novel search space and search for the optimal fusion strategy for the two types of information. Experimental results further validate the significance of this perception adjustment. Building on these observations, we propose a novel framework called Multiple perspectives Fusion Architecture Search (MFAS). Specifically, we utilize continuous-based knowledge to capture speech semantic and quantization-based knowledge to learn textual semantic. Then, we search for the optimal fusion strategy for them. Experimental results demonstrate that MFAS surpasses existing models in comprehensively capturing speech emotion information and can automatically adjust fusion strategy.